Aspen Open Jets: Unlocking LHC Data for Foundation Models in Particle Physics
作者: Oz Amram, Luca Anzalone, Joschka Birk, Darius A. Faroughy, Anna Hallin, Gregor Kasieczka, Michael Krämer, Ian Pang, Humberto Reyes-Gonzalez, David Shih
分类: hep-ph, cs.LG, hep-ex, stat.ML
发布日期: 2024-12-13 (更新: 2025-11-05)
备注: 11 pages, 4 figures, the AspenOpenJets dataset can be found at http://doi.org/10.25592/uhhfdm.16505
期刊: Mach.Learn.Sci.Tech. 6 (2025) 3, 030601
💡 一句话要点
AspenOpenJets:利用LHC开放数据预训练粒子物理领域Foundation模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 高能物理 喷注分析 Foundation模型 预训练 CMS开放数据 机器学习 深度学习 领域泛化
📋 核心要点
- 现有高能物理机器学习模型泛化能力弱,难以适应不同数据集和任务。
- 论文提出利用CMS开放数据构建AspenOpenJets数据集,并预训练OmniJet-$α$ Foundation模型。
- 实验表明,预训练后的模型在生成任务上性能显著提升,尤其是在领域偏移较大的情况下。
📝 摘要(中文)
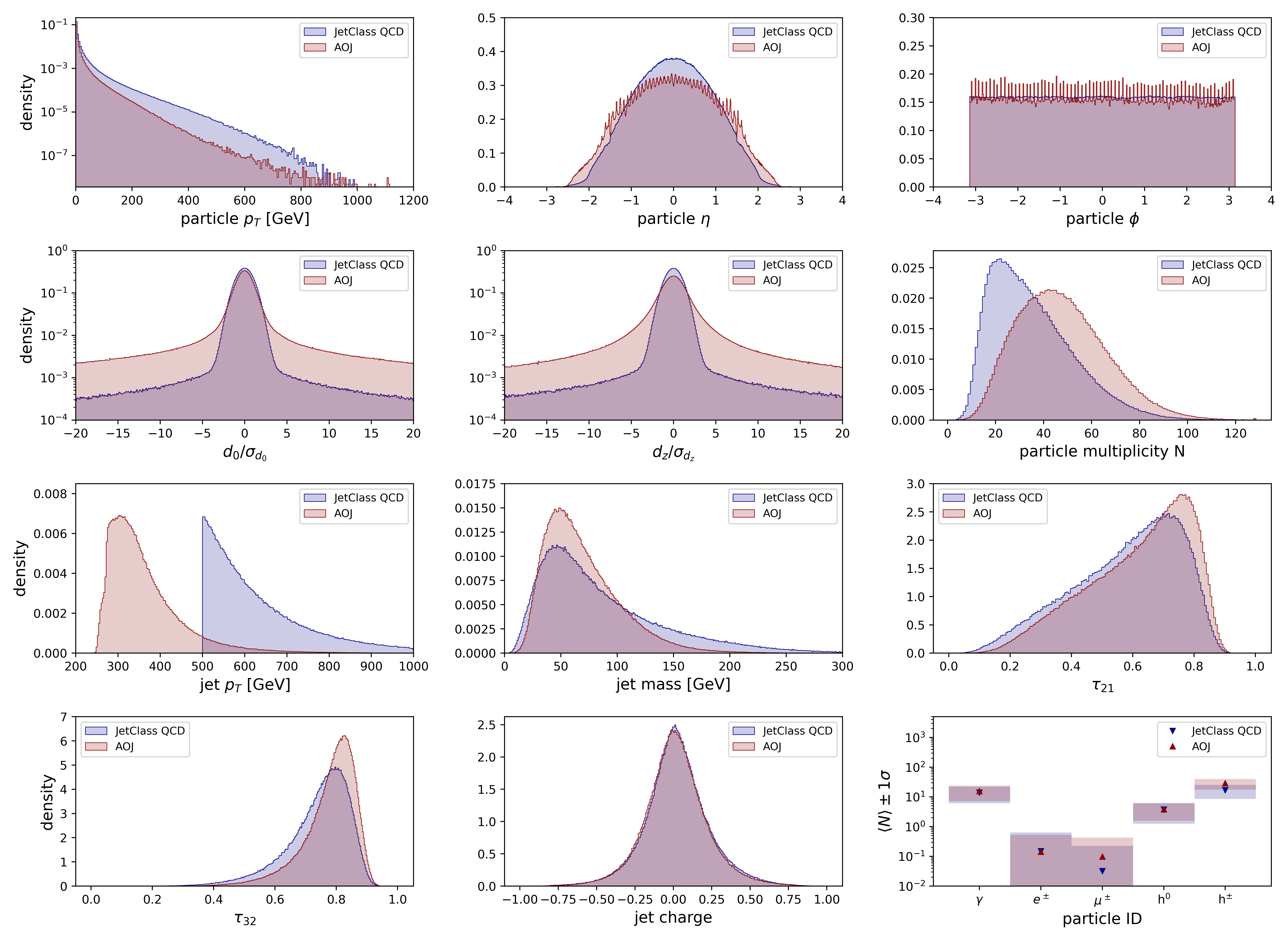
本研究展示了大型强子对撞机(LHC)CMS实验收集的数据如何用于预训练高能物理(HEP)领域的Foundation模型。具体而言,我们引入了AspenOpenJets数据集,该数据集包含约1.78亿个高横向动量($p_T$)喷注,来源于CMS 2016开放数据。我们证明了在AspenOpenJets上预训练OmniJet-$α$ Foundation模型,能够显著提升其在生成任务上的性能,尤其是在存在显著领域偏移的情况下,例如生成来自模拟JetClass数据集的boosted top喷注和QCD喷注。除了展示在真实质子-质子碰撞数据上预训练喷注Foundation模型的强大能力外,我们还提供了ML-ready的AspenOpenJets数据集,供进一步的公开使用。
🔬 方法详解
问题定义:现有高能物理领域的机器学习模型,特别是用于喷注分析的模型,通常需要针对特定数据集和任务进行训练,泛化能力较弱。这限制了它们在不同实验条件和物理过程中的应用。因此,如何利用大规模真实实验数据,构建具有良好泛化能力的Foundation模型,是亟待解决的问题。
核心思路:论文的核心思路是利用大型强子对撞机CMS实验的开放数据,构建一个大规模的喷注数据集(AspenOpenJets),并在此数据集上预训练一个Foundation模型(OmniJet-$α$)。通过在大规模真实数据上进行预训练,模型可以学习到更通用的喷注特征表示,从而提高其在不同数据集和任务上的泛化能力。
技术框架:整体框架包含两个主要阶段:1) 数据集构建:从CMS 2016开放数据中提取高横向动量喷注,构建AspenOpenJets数据集。2) 模型预训练与评估:在AspenOpenJets数据集上预训练OmniJet-$α$模型,然后在JetClass数据集上进行生成任务的评估,包括生成boosted top喷注和QCD喷注。
关键创新:最重要的创新点在于利用真实实验数据(CMS开放数据)进行Foundation模型的预训练。与以往主要依赖模拟数据进行训练的方法不同,本研究利用真实数据,使模型能够更好地学习到真实物理过程中的复杂特征,从而提高其泛化能力。
关键设计:OmniJet-$α$模型的具体结构和参数设置未知,但论文强调了使用大规模真实数据进行预训练的重要性。损失函数和网络结构的选择可能对最终性能有影响,但论文重点在于展示预训练策略的有效性。数据集构建方面,高横向动量喷注的选择可能旨在关注更具区分性的喷注特征。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在AspenOpenJets数据集上预训练的OmniJet-$α$模型,在生成JetClass数据集中的boosted top喷注和QCD喷注时,性能显著提升。这证明了利用真实实验数据进行预训练的有效性,为高能物理领域的Foundation模型研究提供了有力支持。具体的性能提升幅度未知,但论文强调了在存在显著领域偏移的情况下,预训练带来的优势。
🎯 应用场景
该研究成果可应用于高能物理领域的喷注分析、粒子识别、异常检测等任务。通过预训练的Foundation模型,可以降低对特定数据集和任务的依赖,提高模型的泛化能力和效率。未来,该方法有望推广到其他高能物理实验数据,构建更强大的通用模型,加速新物理的发现。
📄 摘要(原文)
Foundation models are deep learning models pre-trained on large amounts of data which are capable of generalizing to multiple datasets and/or downstream tasks. This work demonstrates how data collected by the CMS experiment at the Large Hadron Collider can be useful in pre-training foundation models for HEP. Specifically, we introduce the AspenOpenJets dataset, consisting of approximately 178M high $p_T$ jets derived from CMS 2016 Open Data. We show how pre-training the OmniJet-$α$ foundation model on AspenOpenJets improves performance on generative tasks with significant domain shift: generating boosted top and QCD jets from the simulated JetClass dataset. In addition to demonstrating the power of pre-training of a jet-based foundation model on actual proton-proton collision data, we provide the ML-ready derived AspenOpenJets dataset for further public use.