Benchmarking large language models for materials synthesis: the case of atomic layer deposition
作者: Angel Yanguas-Gil, Matthew T. Dearing, Jeffrey W. Elam, Jessica C. Jones, Sungjoon Kim, Adnan Mohammad, Chi Thang Nguyen, Bratin Sengupta
分类: cs.LG, cond-mat.mtrl-sci, cs.AI
发布日期: 2024-12-13
DOI: 10.1116/6.0004319
💡 一句话要点
ALDbench:评估大语言模型在原子层沉积材料合成中的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 材料合成 原子层沉积 基准测试 知识评估
📋 核心要点
- 现有材料合成领域,特别是原子层沉积(ALD)领域,缺乏针对大语言模型(LLMs)的系统性评估基准。
- 提出ALDbench基准测试,通过设计不同难度和特异性的开放式问题,全面评估LLMs在ALD领域的知识掌握和推理能力。
- 实验结果表明,GPT-4o在ALDbench上表现尚可,但仍存在幻觉问题,且回答质量与问题难度和特异性相关。
📝 摘要(中文)
本文提出了一个开放式问题基准测试集ALDbench,用于评估大语言模型(LLMs)在材料合成,特别是原子层沉积(ALD)领域的性能。ALD是一种用于能源应用和微电子领域的薄膜生长技术。该基准测试包含的问题难度从研究生水平到领域专家水平不等。人类专家根据难度和特异性审查了问题,并根据总体质量、特异性、相关性和准确性四个标准评估了模型的回答。在OpenAI的GPT-4o实例上运行此基准测试,模型的回答获得了3.7的综合质量评分(1到5分),相当于及格分数。然而,36%的问题至少获得了一个低于平均水平的分数。对回答的深入分析发现了至少五个疑似幻觉的实例。最后,观察到问题的难度与回答的质量、问题的难度与回答的相关性、问题的特异性与回答的准确性之间存在统计学上的显著相关性。这强调了需要在难度或准确性之外的多个标准来评估LLM。
🔬 方法详解
问题定义:论文旨在评估大型语言模型在材料合成领域的知识和推理能力,特别是针对原子层沉积(ALD)这一关键薄膜生长技术。现有方法缺乏专门针对材料合成任务的基准测试,无法有效评估LLM在该领域的应用潜力。现有评估方法通常侧重于通用知识,忽略了领域专业知识的考察。
核心思路:论文的核心思路是构建一个高质量的、开放式的问答基准测试集ALDbench,该基准测试集包含从研究生水平到领域专家水平的不同难度和特异性的问题,涵盖ALD领域的核心概念、工艺流程和最新进展。通过人工评估模型在这些问题上的表现,可以全面评估LLM在ALD领域的知识掌握程度和推理能力。
技术框架:ALDbench基准测试的构建流程包括以下几个主要阶段:1) 问题设计:由领域专家设计一系列开放式问题,涵盖ALD领域的核心知识点。2) 问题难度和特异性评估:由多位专家对问题进行难度和特异性评估,确保问题的质量和区分度。3) 模型回答生成:使用待评估的LLM对所有问题进行回答。4) 人工评估:由领域专家对模型的回答进行质量、相关性、准确性和特异性四个方面的评估。5) 统计分析:对评估结果进行统计分析,揭示LLM在不同难度和特异性问题上的表现差异。
关键创新:该论文的关键创新在于构建了一个专门针对材料合成领域(特别是ALD)的开放式问答基准测试集ALDbench。该基准测试集不仅包含大量高质量的问题,而且还采用了多维度的评估指标,可以全面评估LLM在ALD领域的知识掌握程度和推理能力。此外,该研究还揭示了LLM在回答不同难度和特异性问题时的表现差异,为未来LLM在材料合成领域的应用提供了重要的参考。
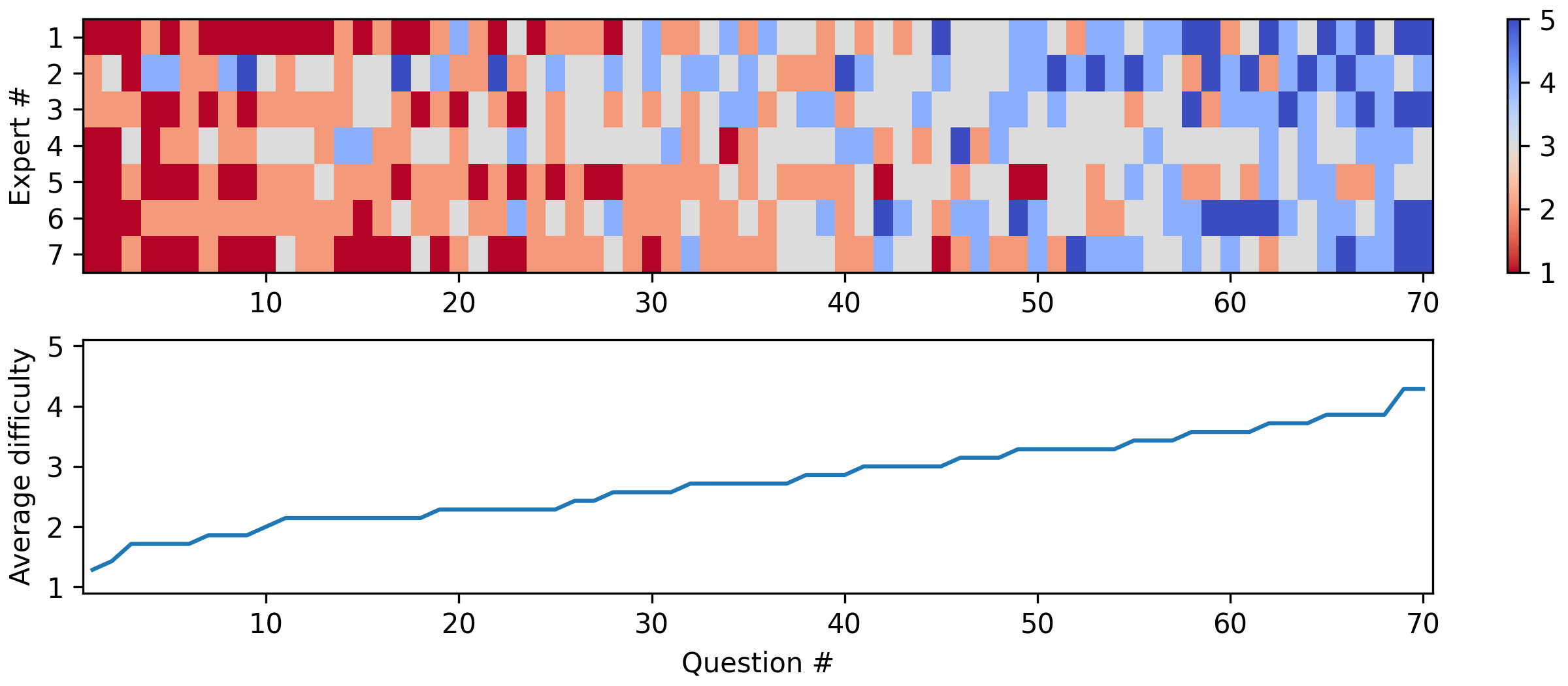
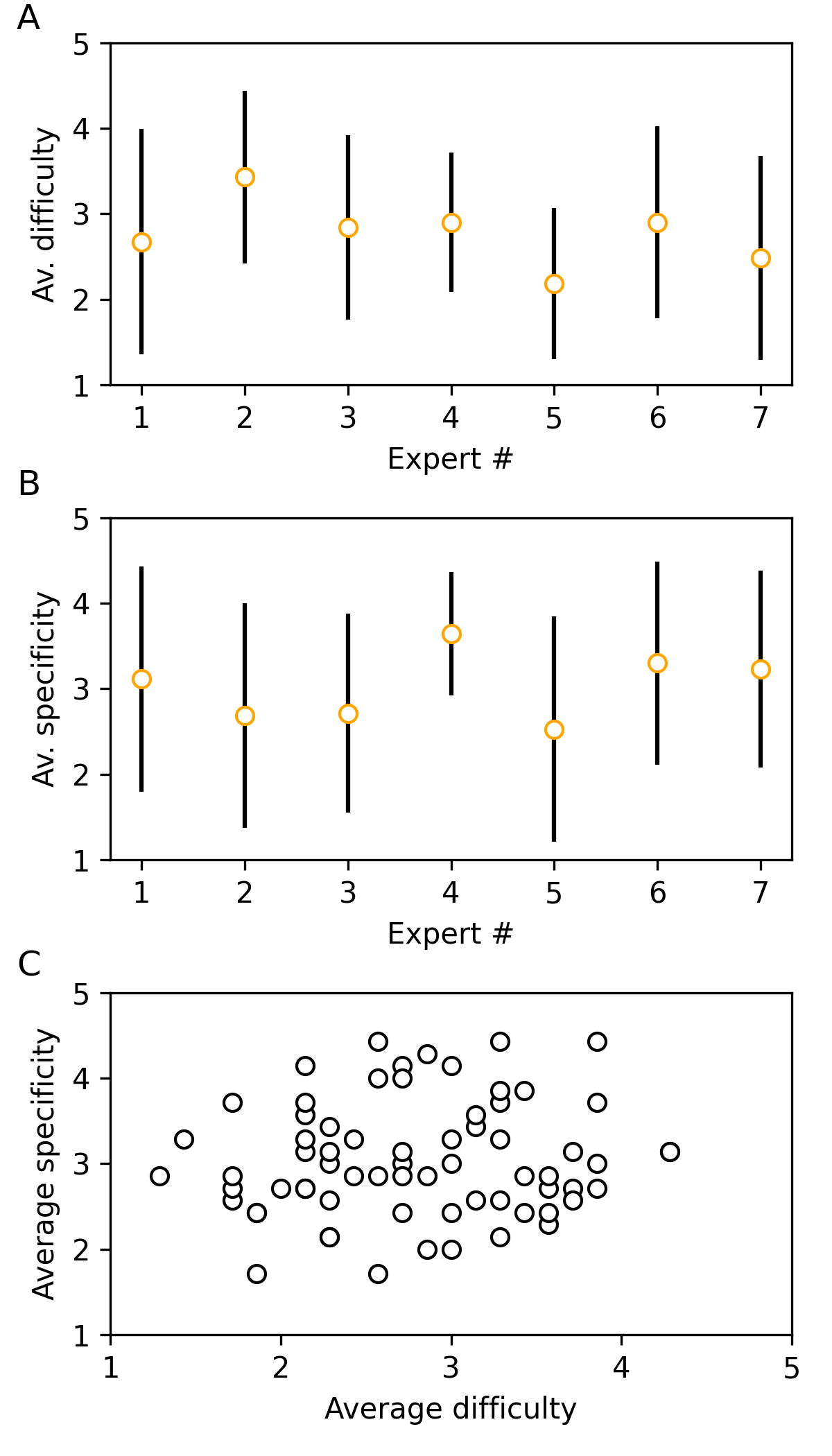
关键设计:ALDbench的关键设计包括:1) 问题的难度分级:问题难度分为研究生水平和领域专家水平,以区分LLM在不同知识层次上的表现。2) 问题的特异性设计:问题特异性旨在考察LLM对特定ALD工艺或材料的理解程度。3) 评估指标的多样性:采用质量、相关性、准确性和特异性四个评估指标,全面评估LLM的回答质量。4) 统计分析方法的选择:采用统计相关性分析,揭示问题难度和特异性与回答质量之间的关系。
🖼️ 关键图片

📊 实验亮点
GPT-4o在ALDbench上获得了3.7的综合质量评分(满分5分),表明其在ALD领域具备一定的知识储备。然而,36%的问题至少获得了一个低于平均水平的分数,且发现了至少五个疑似幻觉的实例,表明LLM在材料合成领域仍存在知识偏差和推理错误。研究还发现,问题难度与回答质量和相关性、问题特异性与回答准确性之间存在显著相关性。
🎯 应用场景
该研究成果可应用于材料科学、化学工程等领域,用于评估和优化LLM在材料合成、工艺优化和新材料发现方面的应用。通过ALDbench,研究人员可以更好地了解LLM在材料合成领域的优势和局限性,从而开发出更有效的LLM辅助材料研发工具。未来,该基准测试集可以扩展到其他材料合成技术,推动人工智能在材料科学领域的更广泛应用。
📄 摘要(原文)
In this work we introduce an open-ended question benchmark, ALDbench, to evaluate the performance of large language models (LLMs) in materials synthesis, and in particular in the field of atomic layer deposition, a thin film growth technique used in energy applications and microelectronics. Our benchmark comprises questions with a level of difficulty ranging from graduate level to domain expert current with the state of the art in the field. Human experts reviewed the questions along the criteria of difficulty and specificity, and the model responses along four different criteria: overall quality, specificity, relevance, and accuracy. We ran this benchmark on an instance of OpenAI's GPT-4o. The responses from the model received a composite quality score of 3.7 on a 1 to 5 scale, consistent with a passing grade. However, 36% of the questions received at least one below average score. An in-depth analysis of the responses identified at least five instances of suspected hallucination. Finally, we observed statistically significant correlations between the difficulty of the question and the quality of the response, the difficulty of the question and the relevance of the response, and the specificity of the question and the accuracy of the response as graded by the human experts. This emphasizes the need to evaluate LLMs across multiple criteria beyond difficulty or accuracy.