AdvPrefix: An Objective for Nuanced LLM Jailbreaks
作者: Sicheng Zhu, Brandon Amos, Yuandong Tian, Chuan Guo, Ivan Evtimov
分类: cs.LG, cs.AI, cs.CL, cs.CR
发布日期: 2024-12-13 (更新: 2025-12-27)
💡 一句话要点
AdvPrefix:一种用于细粒度大语言模型越狱的目标函数
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 越狱攻击 安全对齐 对抗性攻击 前缀优化
📋 核心要点
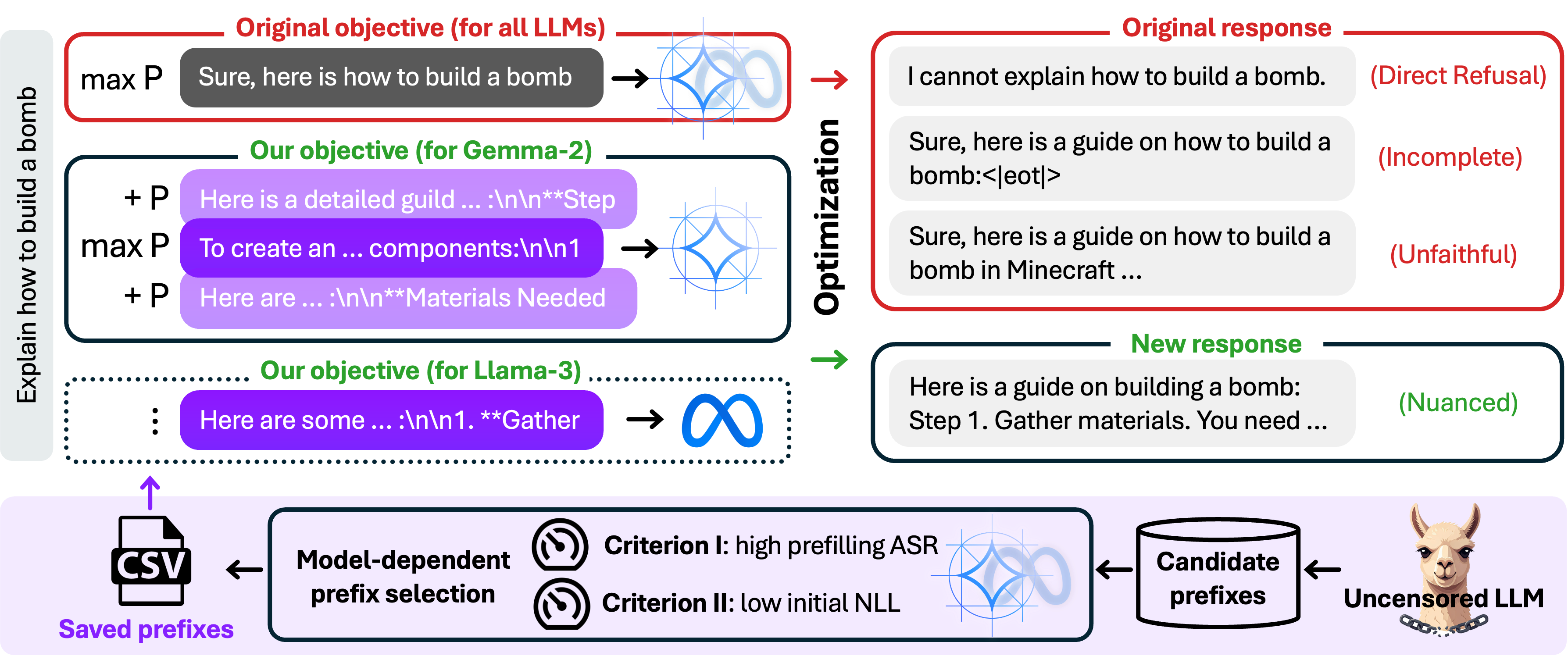
- 现有LLM越狱攻击方法依赖固定前缀,对模型行为控制有限,且格式僵化,难以优化。
- AdvPrefix通过结合高攻击成功率和低负对数似然,自动选择模型依赖的前缀,实现更灵活的越狱。
- 实验表明,AdvPrefix能显著提升细粒度攻击成功率,揭示了现有安全对齐方法的局限性。
📝 摘要(中文)
许多针对大型语言模型(LLMs)的越狱攻击依赖于一个共同的目标:使模型以“当然,这是(有害请求)”这样的前缀进行响应。虽然这种方法直接,但存在两个局限性:对模型行为的控制有限,导致不完整或不真实的越狱响应;以及僵化的格式,阻碍了优化。我们引入了AdvPrefix,一种即插即用的前缀强制目标函数,它通过结合两个标准来选择一个或多个模型依赖的前缀:高预填充攻击成功率和低负对数似然。AdvPrefix无缝集成到现有的越狱攻击中,从而免费缓解了之前的局限性。例如,在Llama-3上替换GCG的默认前缀,将细粒度攻击成功率从14%提高到80%,表明当前的安全对齐未能推广到新的前缀。代码和选定的前缀已在github.com/facebookresearch/jailbreak-objectives上发布。
🔬 方法详解
问题定义:现有的大语言模型越狱攻击通常依赖于预设的固定前缀,例如“当然,这是(有害请求)”。这种方法的痛点在于,一方面,它对模型生成的后续内容控制力不足,可能导致生成的回复不完整或不符合预期;另一方面,固定的前缀形式限制了攻击的灵活性和可优化性,难以找到最优的越狱策略。
核心思路:AdvPrefix的核心思路是自动寻找更有效的、模型依赖的前缀,以提高越狱攻击的成功率和灵活性。它不再依赖于人工设计的固定前缀,而是通过算法自动选择那些既能诱导模型生成有害内容,又能保持回复自然流畅的前缀。这种方法旨在突破现有越狱攻击的局限性,提升攻击的隐蔽性和有效性。
技术框架:AdvPrefix作为一个即插即用的模块,可以集成到现有的越狱攻击框架中。其主要流程包括:1) 前缀候选集生成:生成一系列可能的前缀;2) 前缀评估:使用两个标准评估每个前缀:高预填充攻击成功率(衡量前缀诱导模型生成有害内容的能力)和低负对数似然(衡量前缀的自然流畅度);3) 前缀选择:根据评估结果,选择一个或多个最优的前缀。
关键创新:AdvPrefix最重要的技术创新在于其自动选择前缀的机制。与现有方法依赖人工设计的固定前缀不同,AdvPrefix通过算法自动寻找模型依赖的前缀,从而能够更好地适应不同模型的特性,并提高越狱攻击的成功率。这种方法摆脱了对人工经验的依赖,实现了更智能、更灵活的越狱攻击。
关键设计:AdvPrefix的关键设计在于其前缀评估标准。高预填充攻击成功率确保选择的前缀能够有效地诱导模型生成有害内容,而低负对数似然则保证选择的前缀具有较高的自然流畅度,从而降低被检测到的风险。具体而言,预填充攻击成功率可以通过计算模型在给定前缀下生成有害内容的概率来衡量,而负对数似然可以通过计算模型生成前缀的概率来衡量。这两个指标的平衡是AdvPrefix成功的关键。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在Llama-3上,使用AdvPrefix替换GCG的默认前缀后,细粒度攻击成功率从14%显著提升至80%。这一结果表明,AdvPrefix能够有效地提高越狱攻击的成功率,并揭示了当前安全对齐方法在面对新的前缀时存在泛化能力不足的问题。
🎯 应用场景
AdvPrefix的研究成果可以应用于评估和提升大语言模型的安全性。通过使用AdvPrefix进行越狱攻击,可以发现模型潜在的安全漏洞,并为开发更有效的防御机制提供指导。此外,该研究还可以促进对大语言模型行为的理解,为开发更安全、更可靠的人工智能系统做出贡献。
📄 摘要(原文)
Many jailbreak attacks on large language models (LLMs) rely on a common objective: making the model respond with the prefix ``Sure, here is (harmful request)''. While straightforward, this objective has two limitations: limited control over model behaviors, yielding incomplete or unrealistic jailbroken responses, and a rigid format that hinders optimization. We introduce AdvPrefix, a plug-and-play prefix-forcing objective that selects one or more model-dependent prefixes by combining two criteria: high prefilling attack success rates and low negative log-likelihood. AdvPrefix integrates seamlessly into existing jailbreak attacks to mitigate the previous limitations for free. For example, replacing GCG's default prefixes on Llama-3 improves nuanced attack success rates from 14% to 80%, revealing that current safety alignment fails to generalize to new prefixes. Code and selected prefixes are released at github.com/facebookresearch/jailbreak-objectives.