Scaling Combinatorial Optimization Neural Improvement Heuristics with Online Search and Adaptation
作者: Federico Julian Camerota Verdù, Lorenzo Castelli, Luca Bortolussi
分类: cs.LG, cs.AI
发布日期: 2024-12-13
💡 一句话要点
提出LRBS搜索策略,提升DRL组合优化启发式算法的性能与泛化性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 组合优化 深度强化学习 束搜索 旅行商问题 启发式算法 自适应优化 车辆路径规划
📋 核心要点
- 现有基于DRL的组合优化方法在泛化性和求解大规模问题上存在挑战,性能提升空间有限。
- 论文提出LRBS搜索策略,通过有限步数的展开搜索,增强模型探索能力,提升解的质量。
- 实验表明,LRBS在TSP及其变体上显著提升了性能,缩小了与最优解的差距,并超越了现有自适应方法。
📝 摘要(中文)
本文提出了一种名为有限展开束搜索(LRBS)的束搜索策略,用于基于深度强化学习(DRL)的组合优化改进启发式算法。该方法利用在欧几里得旅行商问题(TSP)上预训练的模型,显著提高了模型在同分布数据上的性能以及对更大规模问题的泛化能力。实验结果表明,LRBS实现了优于现有改进启发式算法的最优性差距,并缩小了与最先进的构造性方法之间的差距。此外,本文还将分析扩展到两个取货和交付TSP变体,以验证结果。最后,本文采用LRBS搜索策略对预训练的改进策略进行离线和在线自适应,从而提高了搜索性能,并超越了最近用于构造性启发式算法的自适应方法。
🔬 方法详解
问题定义:论文旨在解决使用深度强化学习进行组合优化时,改进启发式算法的性能和泛化能力不足的问题。现有的基于DRL的改进启发式算法,通常难以泛化到更大规模的问题实例,并且在同分布数据上的性能也存在提升空间。
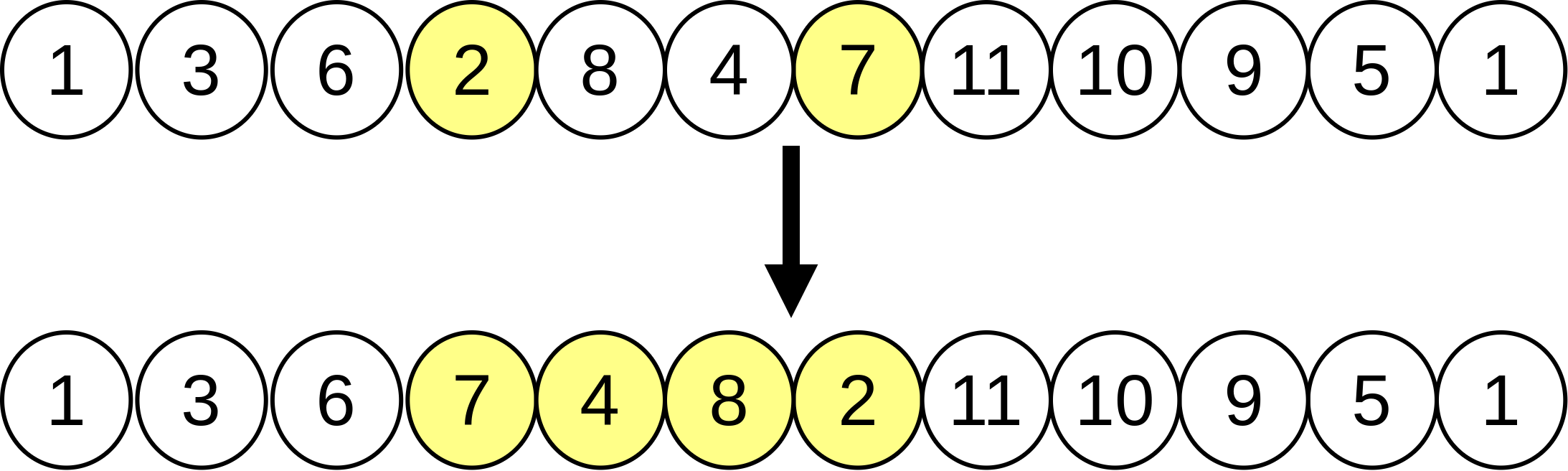
核心思路:论文的核心思路是利用束搜索(Beam Search)策略,在预训练的改进策略的基础上,进行有限步数的展开搜索(Limited Rollout)。通过在每一步选择多个候选解,并对这些候选解进行进一步的改进,从而探索更大的解空间,找到更优的解。
技术框架:整体框架包括以下几个主要阶段:1) 使用DRL预训练一个改进策略,该策略能够对给定的解进行局部优化;2) 使用LRBS算法,从初始解开始,在每一步利用预训练的改进策略生成多个候选解;3) 对这些候选解进行评估,选择最优的几个候选解作为下一轮搜索的起点;4) 重复上述过程,直到达到预设的搜索深度或找到满足要求的解。
关键创新:最重要的技术创新点在于将束搜索策略与预训练的DRL改进策略相结合,提出了一种新的搜索算法LRBS。与传统的束搜索算法不同,LRBS利用DRL模型来指导搜索过程,从而能够更有效地探索解空间。此外,LRBS还引入了有限展开的概念,避免了搜索过程的无限展开,提高了搜索效率。
关键设计:LRBS的关键设计包括:1) 束的大小(Beam Size),决定了每一步保留的候选解的数量;2) 展开深度(Rollout Depth),决定了搜索的步数;3) 评估函数,用于评估候选解的质量,通常使用目标函数的值作为评估标准;4) 预训练的DRL模型,其网络结构和训练方式会影响搜索的性能。论文中使用了Pointer Network作为DRL模型,并使用REINFORCE算法进行训练。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LRBS在欧几里得TSP问题上显著提升了性能,缩小了与最优解的差距。例如,在较大规模的TSP实例上,LRBS实现了优于现有改进启发式算法的最优性差距,并缩小了与最先进的构造性方法之间的差距。此外,LRBS还成功应用于两个取货和交付TSP变体,验证了其泛化能力。通过离线和在线自适应,LRBS进一步提高了搜索性能,超越了最近用于构造性启发式算法的自适应方法。
🎯 应用场景
该研究成果可应用于各种组合优化问题,例如车辆路径规划、任务调度、资源分配等。通过结合深度强化学习和搜索算法,可以有效地解决大规模、复杂的组合优化问题,提高生产效率,降低运营成本。未来,该方法有望在物流、交通、制造业等领域得到广泛应用。
📄 摘要(原文)
We introduce Limited Rollout Beam Search (LRBS), a beam search strategy for deep reinforcement learning (DRL) based combinatorial optimization improvement heuristics. Utilizing pre-trained models on the Euclidean Traveling Salesperson Problem, LRBS significantly enhances both in-distribution performance and generalization to larger problem instances, achieving optimality gaps that outperform existing improvement heuristics and narrowing the gap with state-of-the-art constructive methods. We also extend our analysis to two pickup and delivery TSP variants to validate our results. Finally, we employ our search strategy for offline and online adaptation of the pre-trained improvement policy, leading to improved search performance and surpassing recent adaptive methods for constructive heuristics.