Text2Cypher: Bridging Natural Language and Graph Databases
作者: Makbule Gulcin Ozsoy, Leila Messallem, Jon Besga, Gianandrea Minneci
分类: cs.LG
发布日期: 2024-12-13
💡 一句话要点
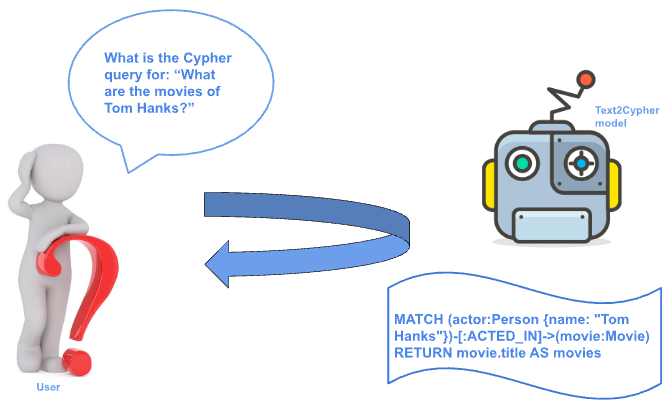
Text2Cypher:构建自然语言到图数据库查询的桥梁,提升非技术用户的使用体验。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Text2Cypher 自然语言查询 图数据库 Cypher查询语言 大型语言模型 数据集构建 模型微调
📋 核心要点
- 现有方法难以将自然语言准确转换为Cypher查询,大型语言模型在处理复杂语义时表现不足。
- 论文提出通过高质量数据集微调大型语言模型,提升自然语言到Cypher查询的翻译准确性。
- 实验表明,在整理后的数据集上微调的模型在BLEU和精确匹配指标上均有显著提升。
📝 摘要(中文)
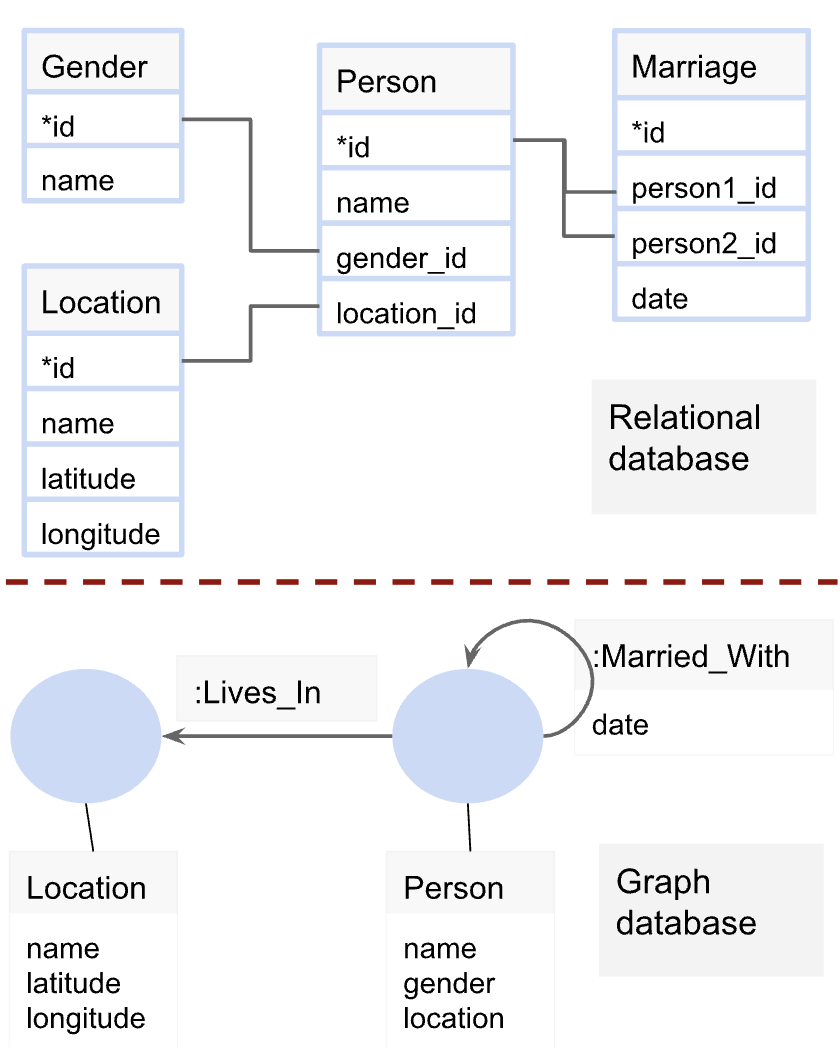
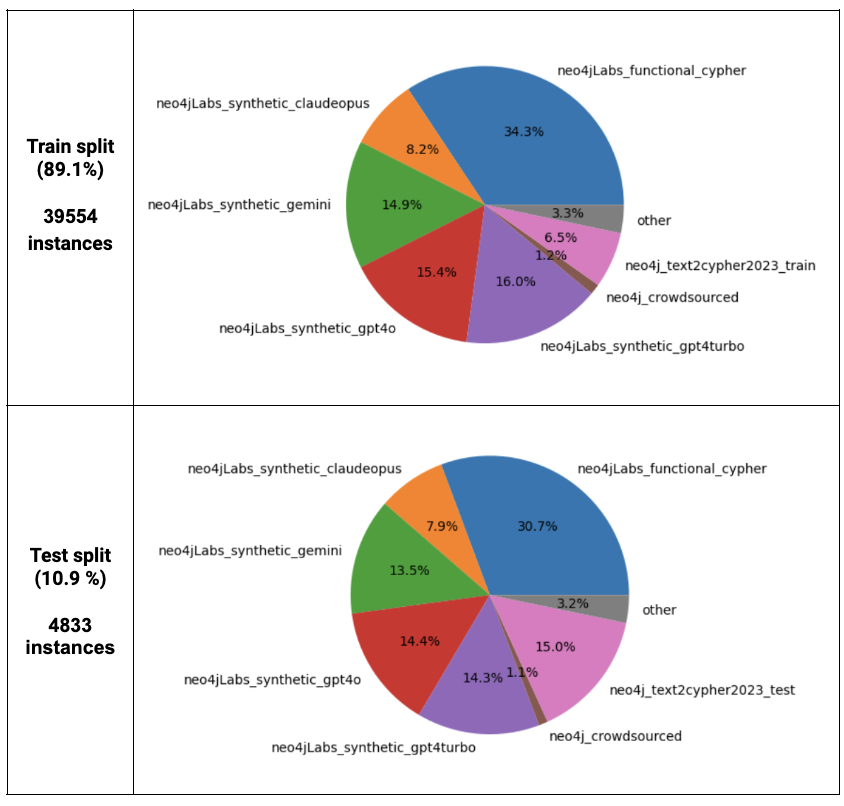
知识图谱利用节点、关系和属性来表示复杂数据。图数据库及其Cypher查询语言能够高效地建模和查询知识图谱。然而,使用Cypher需要专业知识,这对于非专业用户来说是一个挑战。本文旨在通过将自然语言查询翻译成Cypher查询语言来弥合这一差距,从而扩展知识图谱对非技术专家的实用性。虽然大型语言模型(LLMs)可以用于此目的,但它们通常难以捕捉复杂的细微差别,导致输出不完整或不正确。在特定领域数据集上微调LLM已被证明是一种更有希望的方法,但高质量、公开可用的Text2Cypher数据集的有限性使得这具有挑战性。本文展示了如何组合、清理和组织多个公开可用的数据集,总共得到44,387个实例,从而实现有效的微调和评估。在这些数据集上微调的模型显示出显著的性能提升,在Google-BLEU和精确匹配分数方面优于基线模型,突出了高质量数据集和微调在提高Text2Cypher性能方面的重要性。
🔬 方法详解
问题定义:论文旨在解决非技术用户难以使用Cypher查询语言访问图数据库的问题。现有方法,如直接使用大型语言模型,在处理复杂查询时准确率较低,主要痛点在于缺乏高质量的训练数据,导致模型无法有效学习自然语言到Cypher的映射关系。
核心思路:核心思路是通过构建和清洗大规模高质量的Text2Cypher数据集,然后在此数据集上微调大型语言模型。这样可以使模型更好地学习领域知识和语言模式,从而提高翻译的准确性和鲁棒性。
技术框架:该方法主要包含两个阶段:数据集构建与清洗阶段,以及模型微调与评估阶段。数据集构建阶段涉及收集多个公开可用的Text2Cypher数据集,并进行清洗、去重和格式统一等处理。模型微调阶段则使用清洗后的数据集对预训练的大型语言模型进行微调,使其适应Text2Cypher任务。最后,使用标准指标(如BLEU和精确匹配)评估微调后的模型性能。
关键创新:关键创新在于构建了一个大规模、高质量的Text2Cypher数据集,并验证了其在提升模型性能方面的有效性。该数据集的构建过程包括了数据清洗、去重和格式统一等步骤,保证了数据的质量和一致性。
关键设计:论文的关键设计在于数据集的清洗和组织方式,以及选择合适的预训练模型进行微调。具体的技术细节包括:如何有效地去除数据集中的噪声和冗余信息,如何将不同来源的数据集统一到相同的格式,以及如何选择合适的损失函数和优化器来微调大型语言模型。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在构建的44,387个实例数据集上微调的模型,在Google-BLEU和精确匹配分数方面均优于基线模型,证明了高质量数据集和微调在提高Text2Cypher性能方面的有效性。具体的性能提升数据在论文中进行了详细展示。
🎯 应用场景
该研究成果可应用于智能问答系统、知识图谱查询、数据分析等领域。通过将自然语言转换为Cypher查询,非技术用户可以更方便地访问和利用图数据库中的信息,从而提高工作效率和决策质量。未来,该技术有望进一步扩展到其他领域,如医疗、金融等,为各行业提供更智能化的数据服务。
📄 摘要(原文)
Knowledge graphs use nodes, relationships, and properties to represent arbitrarily complex data. When stored in a graph database, the Cypher query language enables efficient modeling and querying of knowledge graphs. However, using Cypher requires specialized knowledge, which can present a challenge for non-expert users. Our work Text2Cypher aims to bridge this gap by translating natural language queries into Cypher query language and extending the utility of knowledge graphs to non-technical expert users. While large language models (LLMs) can be used for this purpose, they often struggle to capture complex nuances, resulting in incomplete or incorrect outputs. Fine-tuning LLMs on domain-specific datasets has proven to be a more promising approach, but the limited availability of high-quality, publicly available Text2Cypher datasets makes this challenging. In this work, we show how we combined, cleaned and organized several publicly available datasets into a total of 44,387 instances, enabling effective fine-tuning and evaluation. Models fine-tuned on this dataset showed significant performance gains, with improvements in Google-BLEU and Exact Match scores over baseline models, highlighting the importance of high-quality datasets and fine-tuning in improving Text2Cypher performance.