Explore Theory of Mind: Program-guided adversarial data generation for theory of mind reasoning
作者: Melanie Sclar, Jane Yu, Maryam Fazel-Zarandi, Yulia Tsvetkov, Yonatan Bisk, Yejin Choi, Asli Celikyilmaz
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-12-12
💡 一句话要点
提出ExploreToM框架,通过程序引导的对抗数据生成增强LLM的心智理论推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 心智理论 大型语言模型 对抗数据生成 程序引导 A*搜索
📋 核心要点
- 现有心智理论评估数据集规模有限,模式简单,可能导致评估盲点和模型能力高估。
- ExploreToM利用A*搜索和领域特定语言,生成多样且具有挑战性的故事场景,用于LLM的心智理论能力测试。
- 实验表明,现有LLM在ExploreToM生成的数据上表现不佳,但使用该数据微调后,在ToMi基准测试中性能显著提升。
📝 摘要(中文)
本文提出了ExploreToM,这是一个用于大规模生成多样且具有挑战性的心智理论数据的框架,旨在实现稳健的训练和评估。该方法利用A*搜索算法,在一个自定义的领域特定语言上进行搜索,以生成复杂的故事结构和新颖、多样且合理的场景,从而测试LLM的极限。评估结果表明,最先进的LLM,如Llama-3.1-70B和GPT-4o,在ExploreToM生成的数据上的准确率分别低至0%和9%,突显了对更稳健的心智理论评估的需求。由于生成的数据是先前工作的概念超集,因此在ExploreToM数据上进行微调,在经典的ToMi基准测试(Le et al., 2019)上产生了27个百分点的准确率提升。ExploreToM还有助于发现模型在展现心智理论时缺失的底层技能和因素,例如不可靠的状态跟踪或数据不平衡,这些因素可能导致模型在基准测试中表现不佳。
🔬 方法详解
问题定义:论文旨在解决现有心智理论评估数据集的局限性问题。现有数据集规模小、模式简单,无法充分评估大型语言模型(LLM)的心智理论能力,导致对模型能力的过度估计。这些数据集缺乏多样性和复杂性,容易被模型通过简单的模式匹配来解决,而无法真正理解故事背后的心理状态和推理过程。
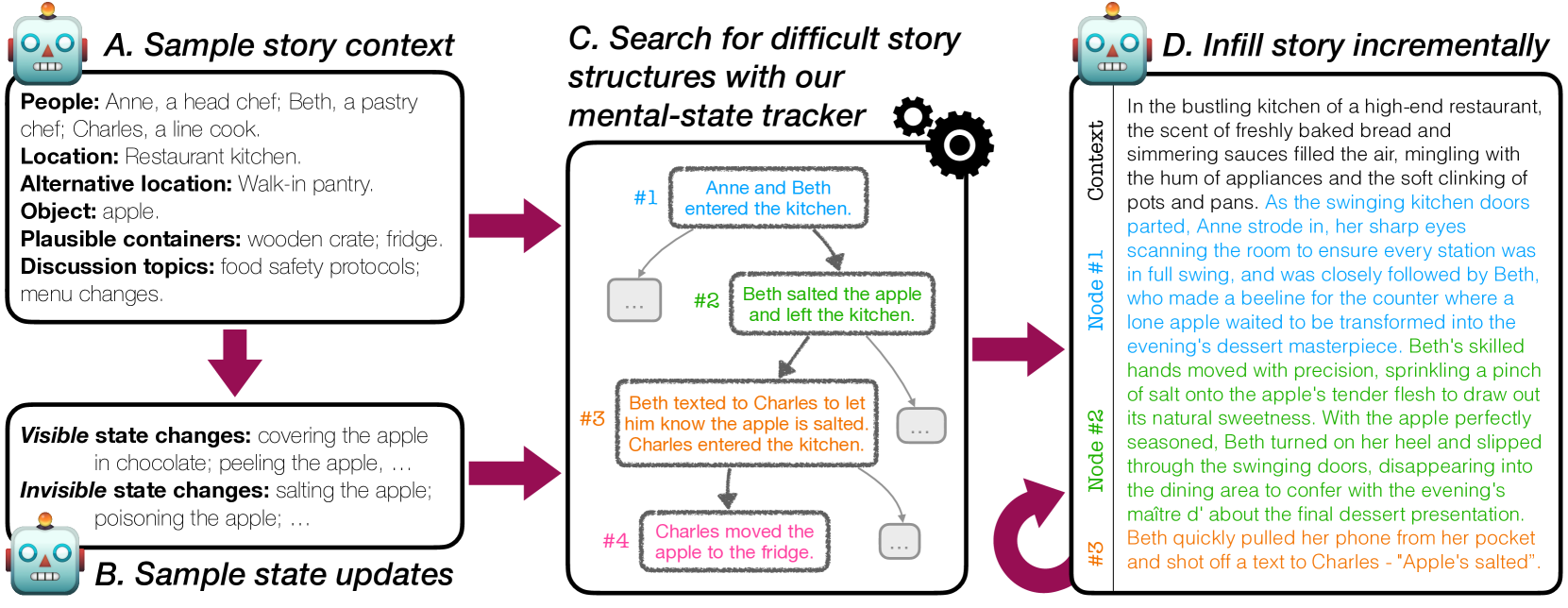
核心思路:论文的核心思路是利用程序生成的方式,自动创建大量多样且具有挑战性的心智理论场景。通过定义一个领域特定语言(DSL),并使用A*搜索算法在该DSL上进行搜索,可以生成复杂的故事结构和新颖的场景,从而更全面地测试LLM的心智理论能力。这种方法能够克服现有数据集的局限性,提供更可靠的评估结果。
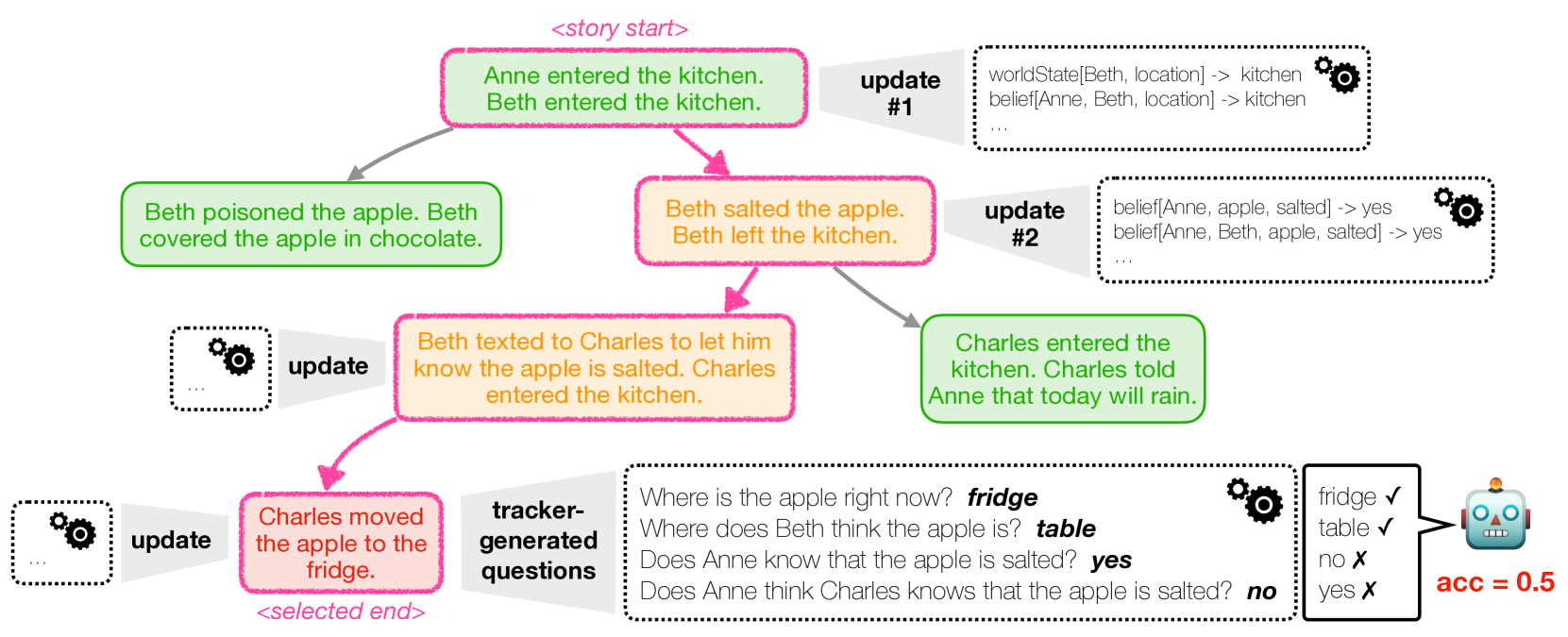
技术框架:ExploreToM框架主要包含以下几个模块:1) 领域特定语言(DSL)定义:定义用于描述心智理论场景的语法和语义规则。2) A搜索算法:利用A搜索算法在DSL定义的空间中搜索,生成满足特定条件的故事结构。3) 数据生成:将生成的故事结构转化为自然语言文本,创建心智理论数据集。4) 模型评估:使用生成的数据集评估LLM的心智理论能力。5) 模型微调:使用生成的数据集微调LLM,提高其心智理论能力。
关键创新:ExploreToM的关键创新在于其程序引导的对抗数据生成方法。与传统的手工标注或简单的规则生成方法不同,ExploreToM利用A*搜索算法在DSL定义的空间中进行搜索,可以生成更复杂、多样且具有挑战性的场景。这种方法能够有效地发现LLM在心智理论推理方面的弱点,并提供更可靠的评估结果。此外,生成的数据集是现有数据集的概念超集,可以用于微调LLM,提高其在现有基准测试中的性能。
关键设计:DSL的设计是ExploreToM的关键。DSL需要能够表达各种心智理论场景,包括信念、意图、情感等。A*搜索算法的目标函数需要能够引导搜索过程,生成具有挑战性的场景。例如,可以设计目标函数,使得生成的场景包含多个角色的信念冲突,或者需要进行多步推理才能得出正确答案。此外,数据生成过程需要保证生成的故事文本流畅自然,避免引入不必要的噪声。
🖼️ 关键图片
📊 实验亮点
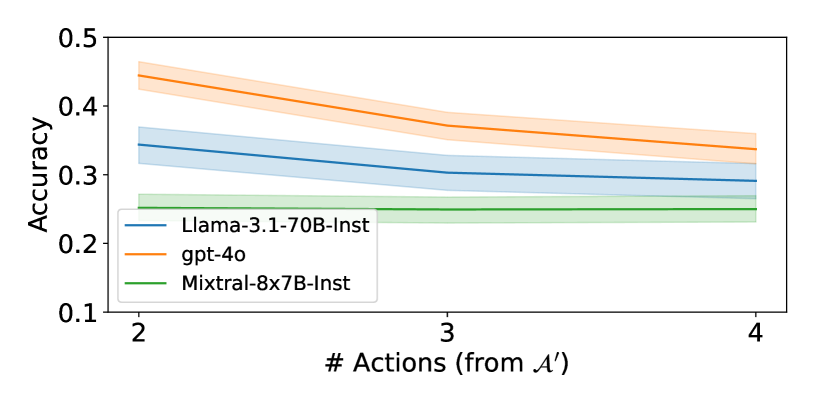
实验结果表明,最先进的LLM(如Llama-3.1-70B和GPT-4o)在ExploreToM生成的数据上的准确率分别低至0%和9%,表明现有模型的心智理论能力远低于预期。然而,使用ExploreToM生成的数据进行微调后,在经典的ToMi基准测试中,模型的准确率提高了27个百分点,证明了该框架生成的数据的有效性。这些结果突显了现有心智理论评估的局限性,并为开发更强大的心智理论模型提供了新的途径。
🎯 应用场景
ExploreToM框架可应用于开发更具社会智能的AI系统,例如,在人机交互、教育、医疗等领域,AI系统需要理解人类的意图、情感和信念,才能更好地与人类进行沟通和协作。该研究有助于提升AI系统的心智理论能力,使其能够更好地理解人类行为,做出更合理的决策,并提供更个性化的服务。未来,该框架可以扩展到其他认知能力评估,促进通用人工智能发展。
📄 摘要(原文)
Do large language models (LLMs) have theory of mind? A plethora of papers and benchmarks have been introduced to evaluate if current models have been able to develop this key ability of social intelligence. However, all rely on limited datasets with simple patterns that can potentially lead to problematic blind spots in evaluation and an overestimation of model capabilities. We introduce ExploreToM, the first framework to allow large-scale generation of diverse and challenging theory of mind data for robust training and evaluation. Our approach leverages an A* search over a custom domain-specific language to produce complex story structures and novel, diverse, yet plausible scenarios to stress test the limits of LLMs. Our evaluation reveals that state-of-the-art LLMs, such as Llama-3.1-70B and GPT-4o, show accuracies as low as 0% and 9% on ExploreToM-generated data, highlighting the need for more robust theory of mind evaluation. As our generations are a conceptual superset of prior work, fine-tuning on our data yields a 27-point accuracy improvement on the classic ToMi benchmark (Le et al., 2019). ExploreToM also enables uncovering underlying skills and factors missing for models to show theory of mind, such as unreliable state tracking or data imbalances, which may contribute to models' poor performance on benchmarks.