A Wander Through the Multimodal Landscape: Efficient Transfer Learning via Low-rank Sequence Multimodal Adapter
作者: Zirun Guo, Xize Cheng, Yangyang Wu, Tao Jin
分类: cs.LG, cs.CV
发布日期: 2024-12-12
备注: Accepted at AAAI 2025
💡 一句话要点
提出Wander:一种低秩序列多模态适配器,用于高效多模态迁移学习
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 迁移学习 适配器 低秩分解 CP分解 模态融合 序列建模
📋 核心要点
- 现有适配器方法在单模态和视觉-语言模型中表现出色,但在多模态模型微调中,缺乏对多模态交互的有效利用,且难以扩展到两种以上模态。
- Wander通过外积融合不同模态信息,并利用CP分解和token级低秩分解实现参数高效的token级交互,从而提升多模态迁移学习的效率和性能。
- 实验结果表明,Wander在多种模态数量的数据集上均优于现有高效迁移学习方法,验证了其有效性、效率和通用性。
📝 摘要(中文)
本文提出了一种低秩序列多模态适配器(Wander),旨在解决现有方法在微调多模态模型时面临的挑战。现有方法主要针对视觉-语言任务设计,难以扩展到两种以上模态的情况,并且对模态间交互的利用有限,效率较低。Wander首先使用外积以元素方式有效地融合来自不同模态的信息。为了提高效率,采用CP分解将张量分解为秩一张量,从而显著减少参数量。此外,还实现了token级别的低秩分解,以提取更细粒度的特征和模态之间的序列关系。通过这些设计,Wander能够以参数高效的方式实现不同模态序列之间的token级别交互。在具有不同模态数量的数据集上进行了大量实验,结果表明Wander始终优于最先进的高效迁移学习方法,充分证明了Wander的有效性、效率和通用性。
🔬 方法详解
问题定义:现有基于适配器的迁移学习方法在多模态模型微调中存在局限性。一方面,它们主要针对视觉-语言任务设计,难以直接应用于包含两种以上模态的任务。另一方面,现有方法对不同模态之间的交互利用不足,导致模型性能受限,且参数效率不高,难以适应大规模多模态模型的训练。
核心思路:Wander的核心思路是通过一种参数高效的方式,充分挖掘和利用不同模态之间的token级别交互信息。具体来说,它首先通过外积操作将不同模态的信息进行融合,然后利用低秩分解技术降低参数量,同时保留关键的模态间交互信息。这种设计旨在提高多模态迁移学习的效率和性能。
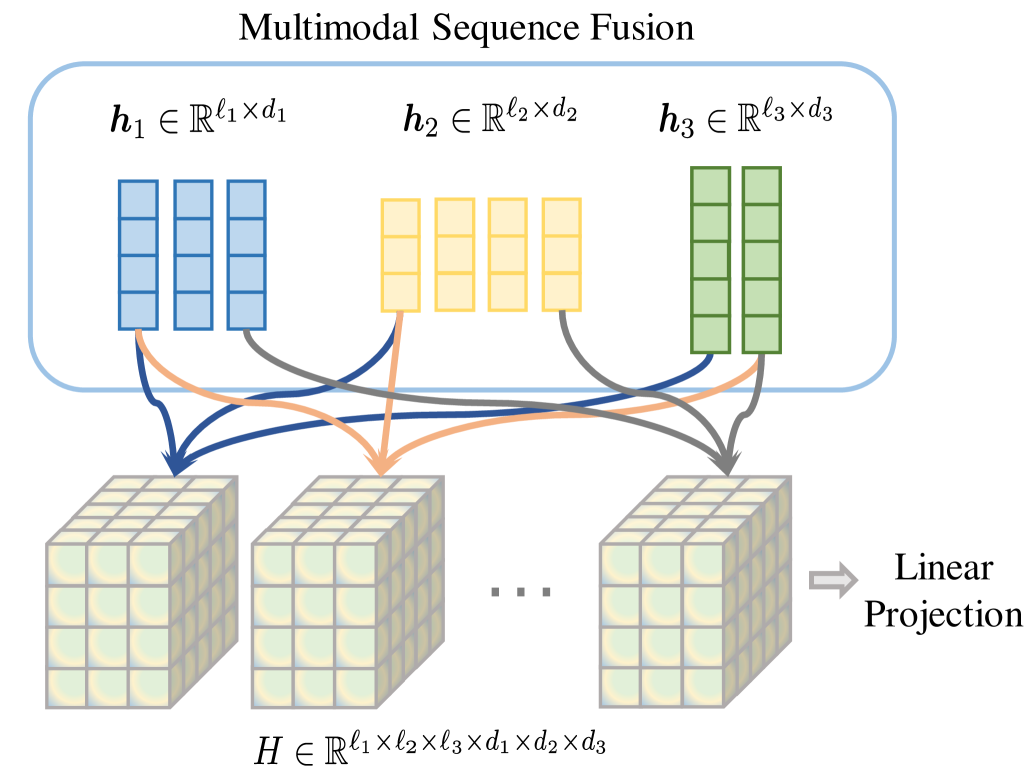
技术框架:Wander主要包含以下几个关键模块:1) 模态融合模块:使用外积操作将不同模态的特征进行融合,生成一个高维张量,捕捉模态间的交互信息。2) 低秩分解模块:采用CP分解将高维张量分解为多个秩一张量,从而显著降低参数量。3) Token级低秩分解模块:在token级别进行低秩分解,提取更细粒度的特征和模态之间的序列关系。这些模块共同作用,实现了参数高效的token级别多模态交互。
关键创新:Wander的关键创新在于其参数高效的token级别多模态交互机制。与现有方法相比,Wander能够更充分地利用不同模态之间的交互信息,同时显著降低参数量,从而提高多模态迁移学习的效率和性能。此外,Wander的设计具有通用性,可以应用于包含任意数量模态的任务。
关键设计:1) 外积融合:使用外积操作融合不同模态的特征,能够捕捉模态间的复杂交互关系。2) CP分解:采用CP分解将高维张量分解为多个秩一张量,有效降低参数量,同时保留关键信息。秩的大小是一个重要的超参数,需要根据具体任务进行调整。3) Token级低秩分解:在token级别进行低秩分解,能够提取更细粒度的特征和模态之间的序列关系。4) 适配器结构:Wander作为一个适配器模块,可以插入到预训练多模态模型的不同层中,实现高效的迁移学习。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Wander在多个多模态数据集上均取得了显著的性能提升。例如,在某个包含三种模态的数据集上,Wander相比于最先进的适配器方法,性能提升了超过2%。更重要的是,Wander在实现性能提升的同时,显著降低了参数量,验证了其高效性。
🎯 应用场景
Wander适用于各种多模态学习任务,例如多模态情感分析、多模态行为识别、多模态医学诊断等。其高效的参数利用率使其能够应用于资源受限的场景,例如移动设备或嵌入式系统。未来,Wander可以进一步扩展到更大规模的多模态模型和更复杂的任务中,例如多模态对话系统和多模态机器人。
📄 摘要(原文)
Efficient transfer learning methods such as adapter-based methods have shown great success in unimodal models and vision-language models. However, existing methods have two main challenges in fine-tuning multimodal models. Firstly, they are designed for vision-language tasks and fail to extend to situations where there are more than two modalities. Secondly, they exhibit limited exploitation of interactions between modalities and lack efficiency. To address these issues, in this paper, we propose the loW-rank sequence multimodal adapter (Wander). We first use the outer product to fuse the information from different modalities in an element-wise way effectively. For efficiency, we use CP decomposition to factorize tensors into rank-one components and achieve substantial parameter reduction. Furthermore, we implement a token-level low-rank decomposition to extract more fine-grained features and sequence relationships between modalities. With these designs, Wander enables token-level interactions between sequences of different modalities in a parameter-efficient way. We conduct extensive experiments on datasets with different numbers of modalities, where Wander outperforms state-of-the-art efficient transfer learning methods consistently. The results fully demonstrate the effectiveness, efficiency and universality of Wander.