Optimal Control with Natural Images: Efficient Reinforcement Learning using Overcomplete Sparse Codes
作者: Peter N. Loxley
分类: cs.LG, cs.AI, eess.SY
发布日期: 2024-12-12 (更新: 2025-12-24)
💡 一句话要点
提出基于过完备稀疏编码的强化学习方法,高效解决自然图像序列上的最优控制问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 最优控制 自然图像 稀疏编码 过完备表示
📋 核心要点
- 现有方法在处理自然图像序列的最优控制问题时,面临计算复杂度高、难以扩展到大规模状态空间的挑战。
- 论文提出利用过完备稀疏编码表示自然图像,并结合强化学习算法,旨在降低计算复杂度,提升学习效率。
- 实验结果表明,该方法在新的强化学习基准上,能够高效地解决比传统方法大几个数量级的最优控制任务。
📝 摘要(中文)
本文将自然图像序列上的最优控制问题形式化为强化学习任务,并推导了图像包含足够信息以实现最优策略的一般条件。研究表明,当自然图像被编码为“高效”图像表示时,强化学习提供了一种计算高效的方法来寻找最优策略。通过引入一个新的强化学习基准来证明这一点,该基准可以轻松扩展到大量状态和长视野。特别地,通过将每个图像表示为过完备稀疏编码,我们能够有效地解决一个最优控制任务,该任务比使用完备编码可解决的任务大几个数量级。本文提供了对这种行为的理论论证,并证明深度学习并非自然图像高效最优控制的必要条件。
🔬 方法详解
问题定义:论文旨在解决自然图像序列上的最优控制问题。现有方法,如基于完备编码的强化学习,在处理大规模状态空间时计算成本过高,难以扩展到复杂的自然图像场景。因此,需要一种更高效的图像表示方法和强化学习算法,以实现自然图像上的最优控制。
核心思路:论文的核心思路是利用过完备稀疏编码来表示自然图像。过完备稀疏编码能够更有效地捕捉图像中的关键特征,从而降低状态空间的维度,并提高强化学习算法的效率。通过学习图像的稀疏表示,强化学习算法可以更快地找到最优策略。
技术框架:整体框架包括图像编码和策略学习两个主要阶段。首先,使用过完备稀疏编码将自然图像转换为稀疏表示。然后,将这些稀疏表示作为强化学习算法的状态输入,学习最优控制策略。具体流程为:输入自然图像序列 -> 过完备稀疏编码 -> 状态表示 -> 强化学习算法 -> 最优策略。
关键创新:最重要的技术创新点在于使用过完备稀疏编码作为自然图像的表示方法。与传统的完备编码相比,过完备稀疏编码能够更有效地捕捉图像中的关键特征,从而降低状态空间的维度,并提高强化学习算法的效率。此外,论文还证明了深度学习并非解决此类问题的必要手段。
关键设计:论文的关键设计包括:1)选择合适的过完备字典学习算法,以获得高质量的稀疏编码;2)设计合适的强化学习算法,以有效地利用稀疏编码的状态表示;3)设计新的强化学习基准,以便于评估算法在自然图像上的性能。具体的参数设置和网络结构等细节在论文中进行了详细描述(未知)。
🖼️ 关键图片


📊 实验亮点
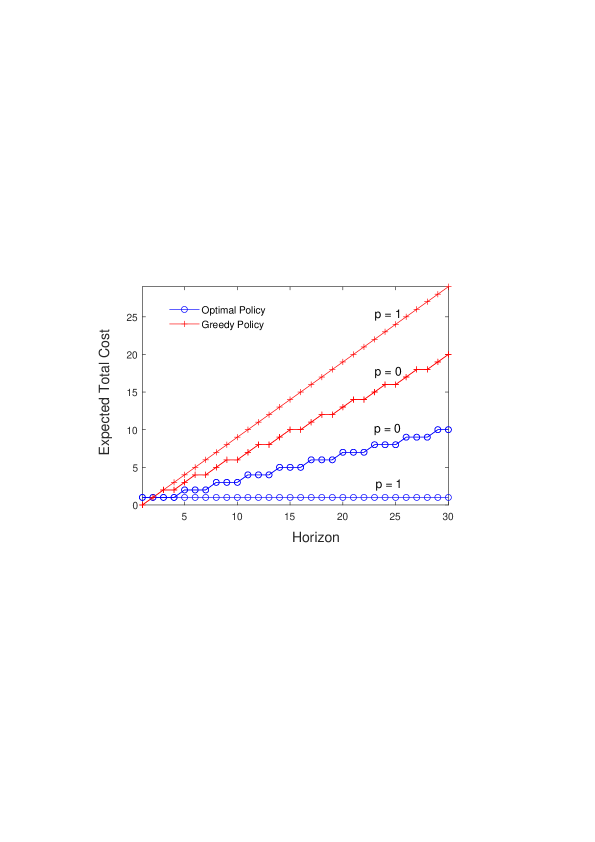
实验结果表明,使用过完备稀疏编码的强化学习方法,能够高效地解决比使用完备编码可解决的任务大几个数量级的最优控制任务。这表明该方法在处理大规模状态空间时具有显著的优势。具体的性能数据和对比基线在论文中进行了详细描述(未知)。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、游戏AI等领域。通过学习自然图像中的最优控制策略,机器人可以更好地理解周围环境,并做出更合理的决策。此外,该方法还可以用于开发更智能的游戏AI,使游戏角色能够更好地适应复杂的游戏环境。
📄 摘要(原文)
Optimal control and sequential decision making are widely used in many complex tasks. Optimal control over a sequence of natural images is a first step towards understanding the role of vision in control. Here, we formalize this problem as a reinforcement learning task, and derive general conditions under which an image includes enough information to implement an optimal policy. Reinforcement learning is shown to provide a computationally efficient method for finding optimal policies when natural images are encoded into "efficient" image representations. This is demonstrated by introducing a new reinforcement learning benchmark that easily scales to large numbers of states and long horizons. In particular, by representing each image as an overcomplete sparse code, we are able to efficiently solve an optimal control task that is orders of magnitude larger than those tasks solvable using complete codes. Theoretical justification for this behaviour is provided. This work also demonstrates that deep learning is not necessary for efficient optimal control with natural images.