Towards LLM-based optimization compilers. Can LLMs learn how to apply a single peephole optimization? Reasoning is all LLMs need!
作者: Xiangxin Fang, Lev Mukhanov
分类: cs.LG, cs.AI, cs.PL
发布日期: 2024-12-11
备注: 13 pages, 8 figures
💡 一句话要点
研究表明,具备增强推理能力的大语言模型更擅长汇编代码的窥孔优化任务
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 编译器优化 窥孔优化 AArch64汇编 思维链推理
📋 核心要点
- 现有研究主要集中于缺乏增强推理机制的开源LLM,限制了其在编译器优化任务中的表现。
- 该研究探索了具备增强推理能力(如思维链)的LLM在汇编代码窥孔优化中的应用潜力。
- 实验表明,未经微调的GPT-o1在窥孔优化任务中优于微调后的Llama2和GPT-4o。
📝 摘要(中文)
大型语言模型(LLM)在各种语言处理任务中展现出巨大潜力,最近的研究也探索了它们在编译器优化中的应用。然而,这些研究主要集中在传统的开源LLM上,例如Llama2,它们缺乏增强的推理机制。本研究调查了微调后的70亿参数Llama2模型在尝试学习和应用AArch64汇编代码的简单窥孔优化时产生的错误。我们分析了LLM产生的错误,并将其与最先进的OpenAI模型(包括GPT-4o和GPT-o1(预览版))进行了比较,这些模型实现了高级推理逻辑。我们证明,OpenAI GPT-o1即使没有经过微调,也优于微调后的Llama2和GPT-4o。我们的研究结果表明,这种优势很大程度上归功于GPT-o1中实现的思维链推理。我们希望我们的工作能够激发更多关于使用具有增强推理机制和思维链的LLM进行代码生成和优化的研究。
🔬 方法详解
问题定义:论文旨在研究大型语言模型在编译器优化中的应用,特别是针对AArch64汇编代码的窥孔优化。现有方法主要依赖于开源LLM,如Llama2,但这些模型缺乏高级推理能力,导致优化效果不佳。因此,该研究关注如何利用具备更强推理能力的LLM来提升代码优化性能。
核心思路:论文的核心思路是利用具备增强推理能力(如思维链)的大型语言模型,例如OpenAI的GPT-o1,来执行窥孔优化任务。这种思路基于这样的假设:更强的推理能力能够帮助LLM更好地理解代码的语义,从而更准确地应用优化规则。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 使用微调后的Llama2模型进行窥孔优化实验,并分析其产生的错误;2) 使用未经微调的GPT-4o和GPT-o1模型进行相同的窥孔优化实验;3) 对比不同模型在优化任务中的表现,特别是关注GPT-o1的思维链推理能力对优化效果的影响。
关键创新:该研究的关键创新在于发现并验证了具备增强推理能力的大型语言模型在代码优化任务中的优势。与以往主要关注开源LLM的研究不同,该研究强调了推理能力在代码优化中的重要性,并证明了GPT-o1等具备思维链推理能力的模型能够取得更好的优化效果。
关键设计:该研究的关键设计包括:1) 选择AArch64汇编代码作为优化对象,因为它是一种常见的指令集架构;2) 使用简单的窥孔优化作为测试用例,以便更清晰地评估不同模型的优化能力;3) 对Llama2进行微调,以便使其能够更好地适应窥孔优化任务;4) 使用GPT-o1的思维链推理能力,以便使其能够更好地理解代码的语义。
🖼️ 关键图片

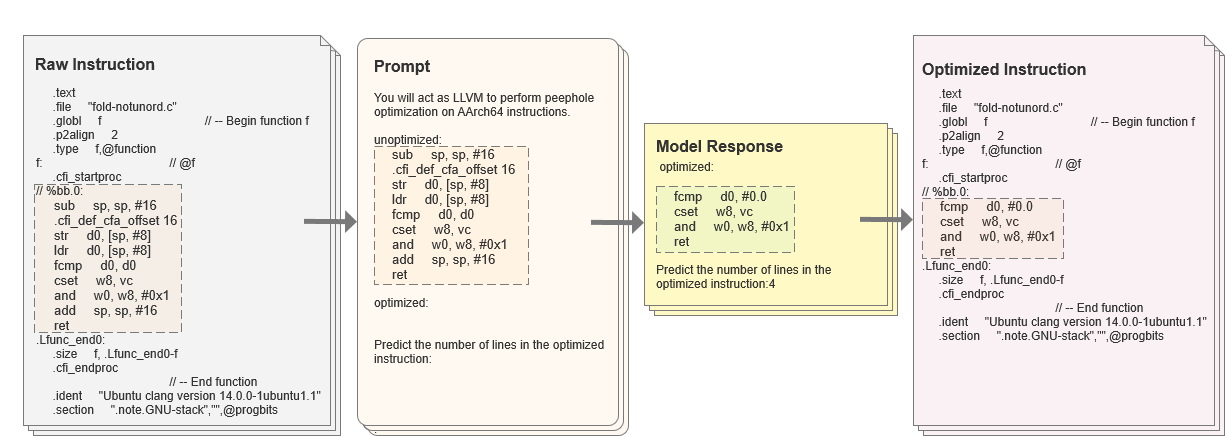

📊 实验亮点
实验结果表明,未经微调的GPT-o1在AArch64汇编代码的窥孔优化任务中,优于微调后的70亿参数Llama2模型和GPT-4o。这一结果突显了增强推理能力(特别是思维链推理)在代码优化中的重要性,并为未来基于LLM的编译器优化研究提供了新的方向。
🎯 应用场景
该研究成果可应用于编译器优化、代码生成、程序自动修复等领域。通过利用具备增强推理能力的大语言模型,可以提升编译器的优化效率,生成更高效的代码,并自动修复程序中的错误。未来,该技术有望在嵌入式系统、移动设备和云计算等领域得到广泛应用。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated great potential in various language processing tasks, and recent studies have explored their application in compiler optimizations. However, all these studies focus on the conventional open-source LLMs, such as Llama2, which lack enhanced reasoning mechanisms. In this study, we investigate the errors produced by the fine-tuned 7B-parameter Llama2 model as it attempts to learn and apply a simple peephole optimization for the AArch64 assembly code. We provide an analysis of the errors produced by the LLM and compare it with state-of-the-art OpenAI models which implement advanced reasoning logic, including GPT-4o and GPT-o1 (preview). We demonstrate that OpenAI GPT-o1, despite not being fine-tuned, outperforms the fine-tuned Llama2 and GPT-4o. Our findings indicate that this advantage is largely due to the chain-of-thought reasoning implemented in GPT-o1. We hope our work will inspire further research on using LLMs with enhanced reasoning mechanisms and chain-of-thought for code generation and optimization.