HARP: A challenging human-annotated math reasoning benchmark
作者: Albert S. Yue, Lovish Madaan, Ted Moskovitz, DJ Strouse, Aaditya K. Singh
分类: cs.LG
发布日期: 2024-12-11
备注: 28 pages, 17 figures
🔗 代码/项目: GITHUB
💡 一句话要点
提出HARP:一个更具挑战性的人工标注数学推理基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数学推理 基准数据集 大型语言模型 人工标注 问题求解
📋 核心要点
- 现有数学推理基准已接近被前沿模型饱和,难以有效评估模型的推理能力。
- HARP数据集包含高质量的人工标注数学题,覆盖多种难度等级,并提供多重解答。
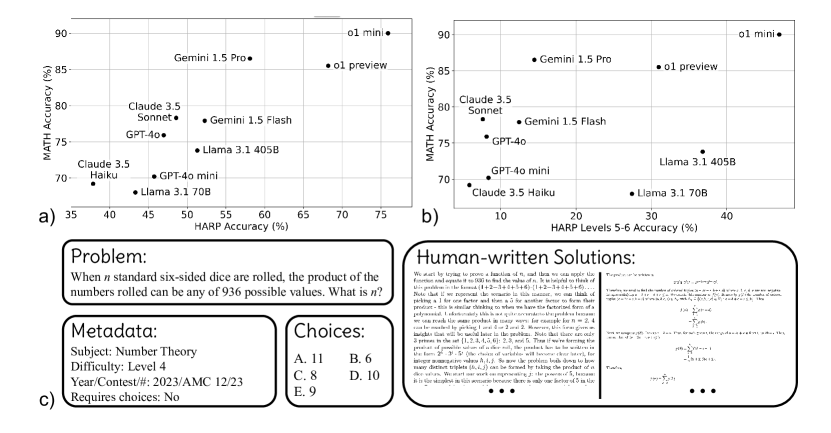
- 实验表明,前沿模型在HARP数据集上,尤其是在高难度问题上,仍有显著提升空间。
📝 摘要(中文)
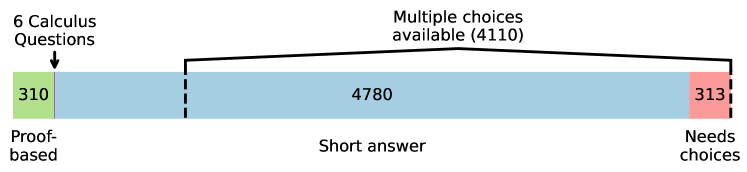
随着大型语言模型的扩展,数学推理正成为一个日益重要的研究领域。然而,即使是像MATH这样之前最具挑战性的评估基准,也接近被前沿模型饱和(o1-mini为90.0%,Gemini 1.5 Pro为86.5%)。我们推出了HARP,即人工标注推理问题(针对数学),包含来自美国国家数学竞赛(A(J)HSME、AMC、AIME、USA(J)MO)的5,409个问题。其中,4,780个问题的答案可以通过SymPy等库自动检查。这些问题分为六个难度级别,前沿模型在最难的197个问题上表现相对较差(o1-mini的平均准确率为41.1%,Gemini 1.5 Pro的平均准确率为9.6%)。我们的数据集还包含多项选择题(针对4,110个问题)和平均每个问题两个人为编写的真实解,为研究提供了新的途径。我们报告了许多前沿模型的评估结果,并分享了一些有趣的分析,例如证明了跨系列的前沿模型本质上会为其更困难的问题扩展推理时间的计算量。最后,我们开源了用于数据集构建(包括抓取)的所有代码和用于评估(包括答案检查)的所有代码,以支持未来的研究。
🔬 方法详解
问题定义:论文旨在解决现有数学推理基准数据集不足以有效评估当前大型语言模型(LLM)的数学推理能力的问题。现有数据集如MATH已接近被前沿模型饱和,无法区分模型在高难度问题上的细微差异。因此,需要一个更具挑战性的基准来推动数学推理领域的研究进展。
核心思路:论文的核心思路是构建一个高质量、人工标注的数学推理数据集,该数据集包含来自高难度数学竞赛的题目,并提供多个人工编写的解答。通过增加问题的难度和提供多重解答,可以更全面地评估模型的推理能力,并促进模型在复杂问题上的学习。
技术框架:HARP数据集的构建流程主要包括以下几个阶段:1) 从美国国家数学竞赛(A(J)HSME、AMC、AIME、USA(J)MO)中收集题目;2) 对题目进行人工标注,包括答案和多重解答;3) 对答案进行自动检查,确保答案的正确性;4) 将题目按照难度进行分级;5) 开源数据集和评估代码,方便研究人员使用。
关键创新:HARP数据集的关键创新在于其高质量的人工标注和高难度的问题。与现有数据集相比,HARP数据集的题目难度更高,更具挑战性,可以更有效地评估模型的推理能力。此外,HARP数据集还提供了多个人工编写的解答,可以为模型提供更丰富的学习信息,并促进模型在复杂问题上的学习。
关键设计:HARP数据集的关键设计包括:1) 题目来源于高难度的数学竞赛,保证了题目的难度和挑战性;2) 提供了多个人工编写的解答,为模型提供了更丰富的学习信息;3) 对答案进行自动检查,确保答案的正确性;4) 将题目按照难度进行分级,方便研究人员选择合适的题目进行评估。
🖼️ 关键图片

📊 实验亮点
实验结果表明,即使是前沿模型在HARP数据集上,尤其是在最难的197个问题上,表现仍然相对较差(o1-mini的平均准确率为41.1%,Gemini 1.5 Pro的平均准确率为9.6%)。这表明HARP数据集对现有模型提出了更高的挑战,并为未来的研究提供了明确的方向。
🎯 应用场景
HARP数据集可用于训练和评估大型语言模型的数学推理能力,推动模型在科学、工程、金融等领域的应用。通过提高模型解决复杂数学问题的能力,可以提升其在实际问题中的表现,例如自动化定理证明、算法设计、数据分析等。
📄 摘要(原文)
Math reasoning is becoming an ever increasing area of focus as we scale large language models. However, even the previously-toughest evals like MATH are now close to saturated by frontier models (90.0% for o1-mini and 86.5% for Gemini 1.5 Pro). We introduce HARP, Human Annotated Reasoning Problems (for Math), consisting of 5,409 problems from the US national math competitions (A(J)HSME, AMC, AIME, USA(J)MO). Of these, 4,780 have answers that are automatically check-able (with libraries such as SymPy). These problems range six difficulty levels, with frontier models performing relatively poorly on the hardest bracket of 197 problems (average accuracy 41.1% for o1-mini, and 9.6% for Gemini 1.5 Pro). Our dataset also features multiple choices (for 4,110 problems) and an average of two human-written, ground-truth solutions per problem, offering new avenues of research that we explore briefly. We report evaluations for many frontier models and share some interesting analyses, such as demonstrating that frontier models across families intrinsically scale their inference-time compute for more difficult problems. Finally, we open source all code used for dataset construction (including scraping) and all code for evaluation (including answer checking) to enable future research at: https://github.com/aadityasingh/HARP.