Adversarial Vulnerabilities in Large Language Models for Time Series Forecasting
作者: Fuqiang Liu, Sicong Jiang, Luis Miranda-Moreno, Seongjin Choi, Lijun Sun
分类: cs.LG, cs.AI, cs.CL, cs.CR
发布日期: 2024-12-11 (更新: 2025-03-12)
备注: AISTATS 2025
🔗 代码/项目: GITHUB
💡 一句话要点
针对LLM时间序列预测的对抗攻击框架,揭示模型脆弱性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对抗攻击 大型语言模型 时间序列预测 鲁棒性 黑盒优化
📋 核心要点
- 现有基于LLM的时间序列预测模型缺乏对对抗攻击的鲁棒性评估,实际应用中存在安全隐患。
- 提出一种定向对抗攻击框架,通过优化生成最小扰动,有效降低LLM时间序列预测的准确性。
- 实验证明,该攻击框架在多种LLM架构和数据集上均有效,性能下降远超随机噪声,凸显模型脆弱性。
📝 摘要(中文)
大型语言模型(LLMs)最近在时间序列预测中展现出巨大潜力,能够处理复杂的时序数据。然而,它们在实际应用中的鲁棒性和可靠性仍有待探索,特别是它们对对抗攻击的敏感性。本文提出了一个针对基于LLM的时间序列预测的定向对抗攻击框架。通过采用无梯度和黑盒优化方法,我们生成了最小但非常有效的扰动,这些扰动显著降低了多个数据集和LLM架构的预测精度。实验结果表明,对抗攻击比随机噪声导致更严重的性能下降,并证明了我们的攻击在不同的LLM(包括使用GPT-3.5、GPT-4、LLaMa和Mistral的LLMTime、TimeGPT和TimeLLM)上的广泛有效性。这些结果强调了LLM在时间序列预测中的关键漏洞,突出了对鲁棒防御机制的需求,以确保它们在实际应用中的可靠部署。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLMs)在时间序列预测任务中对对抗攻击的脆弱性。现有方法缺乏对LLM鲁棒性的充分评估,使得模型在实际部署中容易受到恶意攻击,导致预测精度显著下降。
核心思路:论文的核心思路是通过生成对抗样本来评估LLM的鲁棒性。具体而言,通过对输入时间序列数据添加微小的、难以察觉的扰动,使得LLM的预测结果产生显著偏差,从而揭示模型的脆弱性。这种方法旨在模拟实际应用中可能存在的恶意攻击,并为后续的防御机制研究提供依据。
技术框架:该对抗攻击框架主要包含以下几个阶段:1) 选择目标LLM模型和时间序列数据集;2) 定义攻击目标,例如降低预测精度到特定水平;3) 使用无梯度或黑盒优化方法生成对抗扰动;4) 将扰动添加到原始时间序列数据,生成对抗样本;5) 使用对抗样本对LLM进行预测,评估攻击效果。
关键创新:该论文的关键创新在于提出了一个针对LLM时间序列预测的定向对抗攻击框架。与传统的对抗攻击方法不同,该框架专门针对时间序列数据和LLM的特点进行了优化,能够生成更有效的对抗扰动。此外,该框架采用了无梯度和黑盒优化方法,使其能够攻击各种类型的LLM,包括那些无法访问内部参数的模型。
关键设计:在对抗扰动的生成过程中,论文采用了多种优化算法,例如粒子群优化(PSO)和差分进化(DE)。这些算法旨在寻找最小的扰动,同时最大化对预测精度的影响。此外,论文还设计了一种损失函数,用于衡量攻击效果,该损失函数考虑了预测精度和扰动的大小。在实验中,论文针对不同的LLM模型和数据集,调整了优化算法的参数,以获得最佳的攻击效果。
🖼️ 关键图片
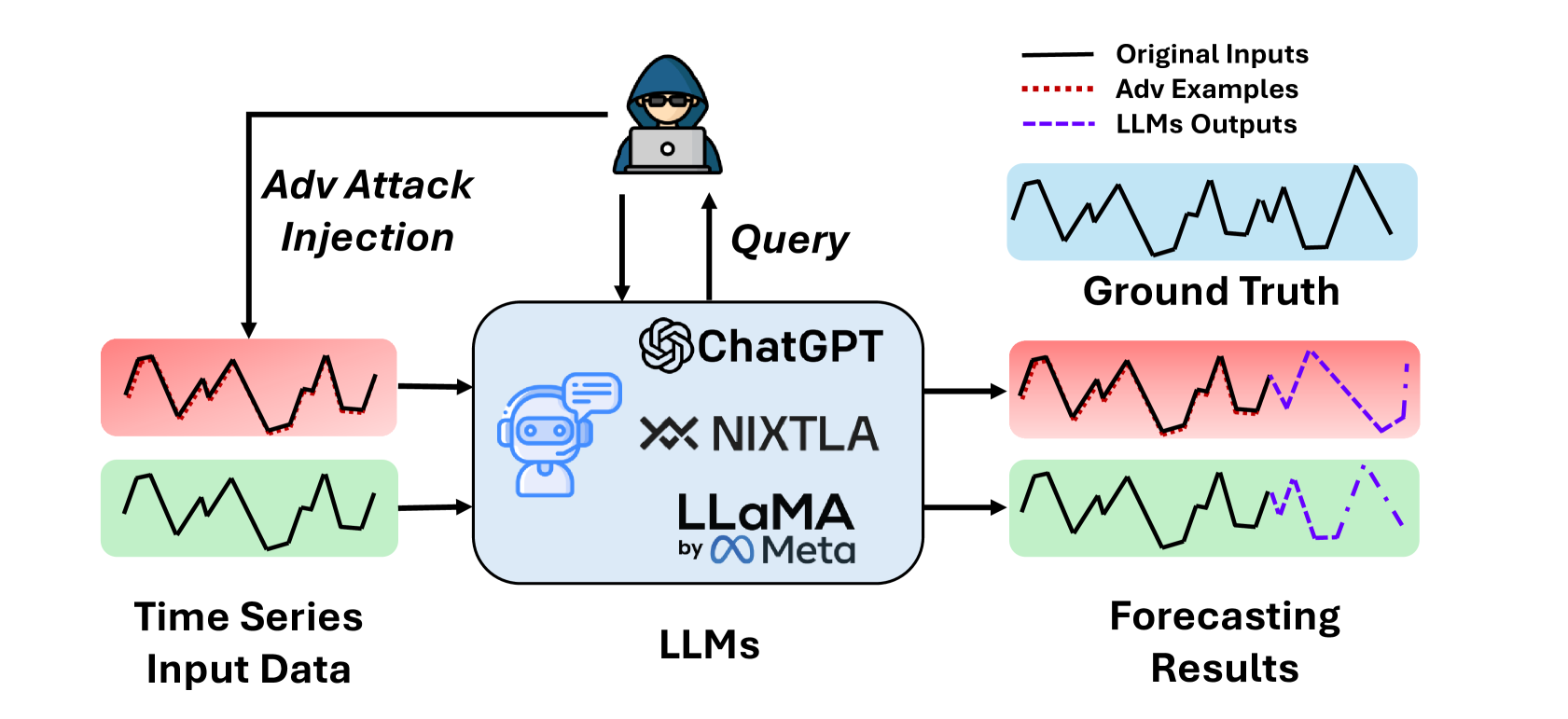
📊 实验亮点
实验结果表明,该对抗攻击框架能够显著降低多种LLM(包括LLMTime、TimeGPT和TimeLLM)在多个时间序列数据集上的预测精度。与随机噪声相比,对抗攻击导致的性能下降更为严重,凸显了LLM在时间序列预测中的脆弱性。例如,在某些数据集上,对抗攻击可以将预测精度降低50%以上。
🎯 应用场景
该研究成果可应用于评估和提升LLM在金融预测、供应链管理、能源需求预测等领域的安全性。通过揭示LLM的脆弱性,促使开发更鲁棒的防御机制,保障关键应用场景的可靠性和稳定性,避免因对抗攻击导致重大经济损失或决策失误。
📄 摘要(原文)
Large Language Models (LLMs) have recently demonstrated significant potential in time series forecasting, offering impressive capabilities in handling complex temporal data. However, their robustness and reliability in real-world applications remain under-explored, particularly concerning their susceptibility to adversarial attacks. In this paper, we introduce a targeted adversarial attack framework for LLM-based time series forecasting. By employing both gradient-free and black-box optimization methods, we generate minimal yet highly effective perturbations that significantly degrade the forecasting accuracy across multiple datasets and LLM architectures. Our experiments, which include models like LLMTime with GPT-3.5, GPT-4, LLaMa, and Mistral, TimeGPT, and TimeLLM show that adversarial attacks lead to much more severe performance degradation than random noise, and demonstrate the broad effectiveness of our attacks across different LLMs. The results underscore the critical vulnerabilities of LLMs in time series forecasting, highlighting the need for robust defense mechanisms to ensure their reliable deployment in practical applications. The code repository can be found at https://github.com/JohnsonJiang1996/AdvAttack_LLM4TS.