Federated In-Context LLM Agent Learning
作者: Panlong Wu, Kangshuo Li, Junbao Nan, Fangxin Wang
分类: cs.LG, cs.AI, cs.CL, cs.CR
发布日期: 2024-12-11
💡 一句话要点
提出FICAL:一种保护隐私的联邦上下文LLM Agent学习方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 大型语言模型 上下文学习 知识纲要 隐私保护
📋 核心要点
- 现有联邦学习训练LLM Agent面临数据隐私和通信成本高的挑战,直接传输模型参数或原始数据存在泄露风险。
- FICAL算法通过联邦学习聚合知识纲要而非模型参数,利用上下文学习能力训练LLM Agent,保护数据隐私。
- 实验表明,FICAL在保持竞争力的性能的同时,显著降低了通信成本,达到了3.33×10^5倍的降低。
📝 摘要(中文)
大型语言模型(LLM)通过实现逻辑推理、工具使用以及与外部系统交互,彻底改变了智能服务。LLM的发展经常受到高质量数据稀缺的阻碍,而这些数据本质上是敏感的。联邦学习(FL)通过促进分布式LLM的协同训练,同时保护私有数据,提供了一个潜在的解决方案。然而,FL框架面临着巨大的带宽和计算需求,以及来自异构数据分布的挑战。LLM新兴的上下文学习能力提供了一种有前景的方法,通过聚合自然语言而不是庞大的模型参数。然而,这种方法存在隐私泄露的风险,因为它需要在聚合期间收集和呈现来自各个客户端的数据样本。在本文中,我们提出了一种新颖的保护隐私的联邦上下文LLM Agent学习(FICAL)算法,据我们所知,这是第一个利用上下文学习的力量通过FL训练各种LLM Agent的工作。在我们的设计中,由一种新颖的LLM增强的知识纲要生成(KCG)模块生成的知识纲要在客户端和服务器之间传输,而不是先前FL方法中的模型参数。除此之外,还设计了一种基于检索增强生成(RAG)的工具学习和利用(TLU)模块,我们将聚合的全局知识纲要作为教师来教LLM Agent工具的使用。我们进行了广泛的实验,结果表明,与其他SOTA基线相比,FICAL具有竞争力的性能,并且通信成本显著降低了$\mathbf{3.33\times10^5}$倍。
🔬 方法详解
问题定义:论文旨在解决联邦学习环境下训练LLM Agent时,数据隐私保护和通信成本高昂的问题。传统的联邦学习方法,如联邦平均,需要传输大量的模型参数,这带来了巨大的通信开销。此外,直接共享原始数据或中间表示也存在隐私泄露的风险。因此,如何在保护用户数据隐私的前提下,高效地进行联邦LLM Agent学习是一个亟待解决的问题。
核心思路:论文的核心思路是利用LLM的上下文学习能力,通过联邦学习聚合知识纲要(Knowledge Compendiums)而非模型参数。知识纲要是一种自然语言形式的知识表示,可以有效地概括客户端的数据特征,同时避免直接暴露原始数据。通过在客户端和服务器之间传输知识纲要,可以显著降低通信成本,并保护用户数据隐私。
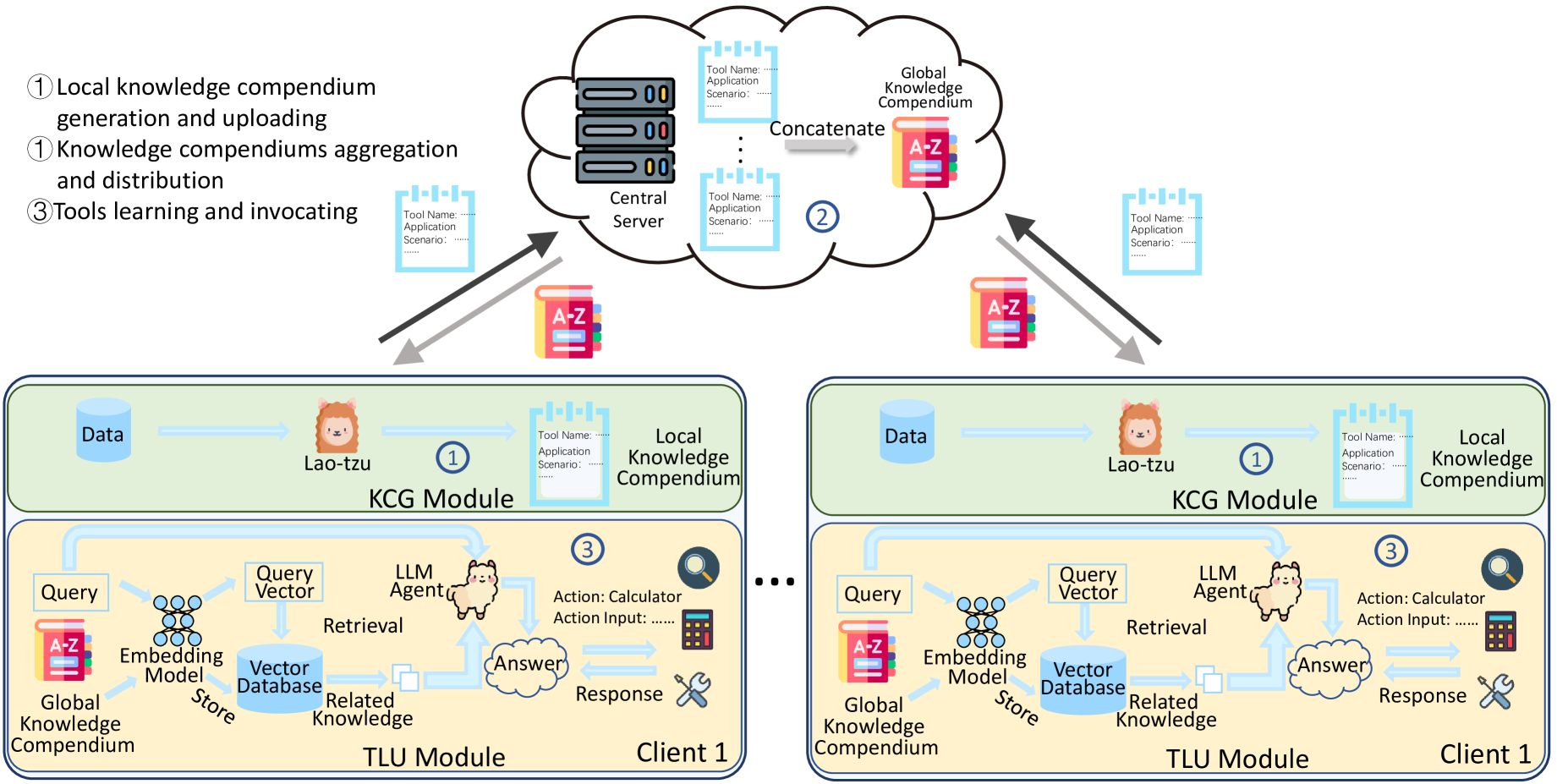
技术框架:FICAL算法的整体框架包括以下几个主要模块:1) LLM增强的知识纲要生成(KCG)模块:该模块负责在客户端利用LLM生成知识纲要,用于概括本地数据特征。2) 联邦聚合模块:该模块负责在服务器端聚合来自各个客户端的知识纲要,生成全局知识纲要。3) 检索增强生成(RAG)的工具学习和利用(TLU)模块:该模块利用全局知识纲要作为教师,指导LLM Agent学习工具的使用。
关键创新:论文最重要的技术创新点在于提出了基于知识纲要的联邦上下文LLM Agent学习方法。与传统的联邦学习方法相比,FICAL算法不需要传输模型参数,而是传输自然语言形式的知识纲要,这显著降低了通信成本,并提高了隐私保护能力。此外,利用RAG的TLU模块,可以有效地将全局知识纲要迁移到LLM Agent,提高其工具使用能力。
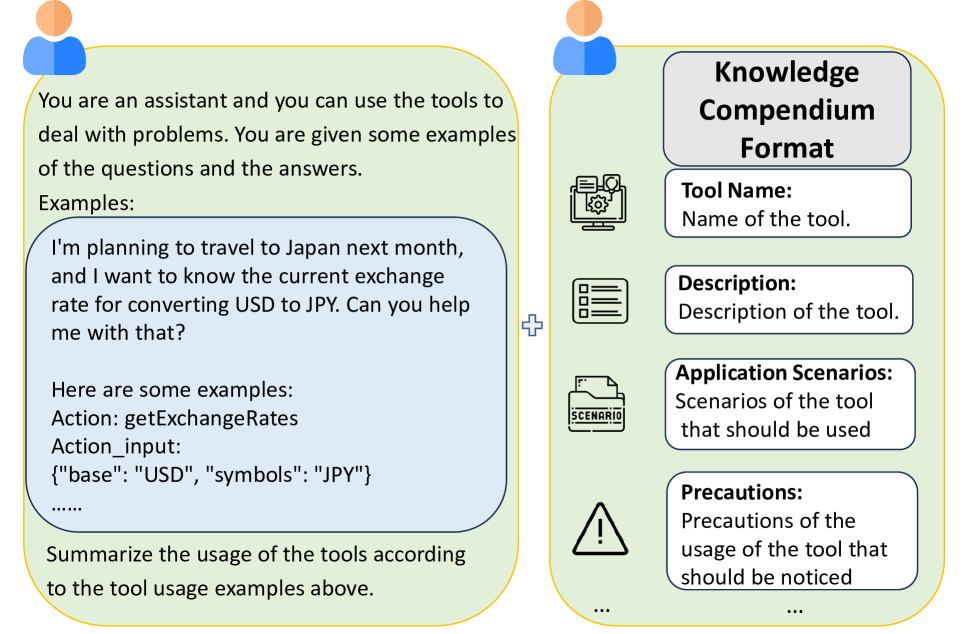
关键设计:KCG模块的关键设计在于如何利用LLM有效地生成知识纲要。论文可能采用了prompt engineering等技术,引导LLM生成高质量的知识纲要。TLU模块的关键设计在于如何利用全局知识纲要指导LLM Agent学习工具的使用。这可能涉及到设计合适的损失函数,以及调整LLM的训练策略。具体的参数设置、损失函数、网络结构等技术细节在论文中应该有更详细的描述(未知)。
🖼️ 关键图片

📊 实验亮点
实验结果表明,FICAL算法在保持与SOTA基线相当的性能水平下,通信成本显著降低了3.33×10^5倍。这一结果表明,基于知识纲要的联邦上下文学习方法可以有效地降低通信成本,并提高隐私保护能力。具体的性能指标和对比基线需要在论文中进一步查阅(未知)。
🎯 应用场景
FICAL算法具有广泛的应用前景,例如在医疗健康、金融风控、智能客服等领域,可以利用分布在不同机构的私有数据,训练强大的LLM Agent,提供个性化的智能服务,同时保护用户数据隐私。该研究有望推动联邦学习和LLM Agent技术的融合,促进人工智能在各个领域的应用。
📄 摘要(原文)
Large Language Models (LLMs) have revolutionized intelligent services by enabling logical reasoning, tool use, and interaction with external systems as agents. The advancement of LLMs is frequently hindered by the scarcity of high-quality data, much of which is inherently sensitive. Federated learning (FL) offers a potential solution by facilitating the collaborative training of distributed LLMs while safeguarding private data. However, FL frameworks face significant bandwidth and computational demands, along with challenges from heterogeneous data distributions. The emerging in-context learning capability of LLMs offers a promising approach by aggregating natural language rather than bulky model parameters. Yet, this method risks privacy leakage, as it necessitates the collection and presentation of data samples from various clients during aggregation. In this paper, we propose a novel privacy-preserving Federated In-Context LLM Agent Learning (FICAL) algorithm, which to our best knowledge for the first work unleashes the power of in-context learning to train diverse LLM agents through FL. In our design, knowledge compendiums generated by a novel LLM-enhanced Knowledge Compendiums Generation (KCG) module are transmitted between clients and the server instead of model parameters in previous FL methods. Apart from that, an incredible Retrieval Augmented Generation (RAG) based Tool Learning and Utilizing (TLU) module is designed and we incorporate the aggregated global knowledge compendium as a teacher to teach LLM agents the usage of tools. We conducted extensive experiments and the results show that FICAL has competitive performance compared to other SOTA baselines with a significant communication cost decrease of $\mathbf{3.33\times10^5}$ times.