MAPLE: A Framework for Active Preference Learning Guided by Large Language Models
作者: Saaduddin Mahmud, Mason Nakamura, Shlomo Zilberstein
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-12-10 (更新: 2024-12-20)
备注: AAAI 2025 AI Alignment Track
💡 一句话要点
MAPLE:基于大语言模型的主动偏好学习框架,提升样本效率和查询质量
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 主动偏好学习 大语言模型 自然语言反馈 贝叶斯优化 人机交互
📋 核心要点
- 现有偏好学习方法计算成本高昂,依赖大量人工标注,且缺乏模型可解释性。
- MAPLE框架利用大语言模型建模偏好分布,结合自然语言反馈和传统偏好学习方法。
- 实验证明MAPLE能加速学习进程,并提升人类用户回答偏好查询的效率和准确性。
📝 摘要(中文)
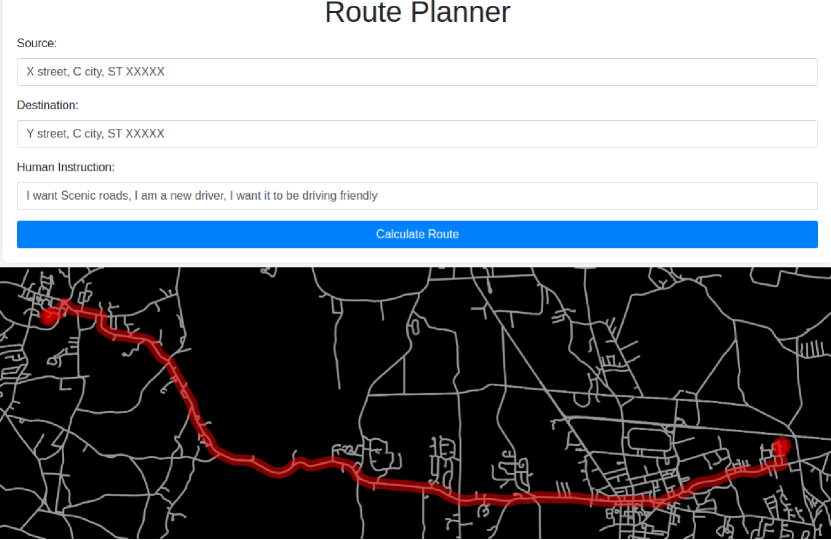
本文提出MAPLE,一个基于大语言模型(LLM)引导的贝叶斯主动偏好学习框架。现有方法常面临计算负担高、人工监督成本高和缺乏可解释性等问题。MAPLE利用LLM对偏好函数分布进行建模,并以自然语言反馈和传统偏好学习反馈(如成对轨迹排序)为条件。MAPLE还采用主动学习来系统地减少这种分布的不确定性,并结合语言条件的主动查询选择机制来识别信息丰富且易于回答的查询,从而减轻人工负担。在包括使用OpenStreetMap数据的真实车辆路线规划基准在内的两个基准上评估了MAPLE的样本效率和偏好推断质量。结果表明,MAPLE加速了学习过程,并有效提高了人类回答查询的能力。
🔬 方法详解
问题定义:论文旨在解决传统偏好学习方法中存在的样本效率低、人工标注负担重以及缺乏可解释性的问题。现有方法在处理复杂偏好学习任务时,需要大量的训练数据和人工反馈,并且难以理解模型学习到的偏好模式。
核心思路:论文的核心思路是利用大语言模型(LLM)的强大语言理解和生成能力,将自然语言反馈融入到偏好学习过程中。通过LLM建模偏好函数分布,并结合主动学习策略,选择信息量最大的查询,从而减少人工标注的需求,提高学习效率。
技术框架:MAPLE框架主要包含以下几个模块:1) 基于LLM的偏好函数分布建模模块:利用LLM对偏好函数进行建模,并以自然语言反馈和传统偏好学习反馈作为条件,更新偏好函数分布。2) 主动查询选择模块:采用语言条件的主动查询选择机制,选择信息量最大且易于回答的查询,以减少人工负担。3) 偏好学习模块:根据用户的反馈,更新偏好模型,并不断优化偏好函数分布。整体流程是,首先利用LLM初始化偏好函数分布,然后通过主动查询选择模块选择查询,用户给出反馈后,更新偏好模型,重复该过程直到模型收敛。
关键创新:MAPLE的关键创新在于将大语言模型引入到主动偏好学习框架中,利用LLM的语言理解能力来建模偏好函数分布,并结合语言条件的主动查询选择机制,从而显著提高了样本效率和查询质量。与传统方法相比,MAPLE能够更好地利用自然语言反馈,减少人工标注的需求,并提高学习效率。
关键设计:论文中关键的设计包括:1) 如何将自然语言反馈融入到LLM的偏好函数建模中;2) 如何设计语言条件的主动查询选择机制,选择信息量最大且易于回答的查询;3) 如何平衡探索(exploration)和利用(exploitation),以避免陷入局部最优解。具体的参数设置、损失函数和网络结构等技术细节在论文中进行了详细描述(未知)。
🖼️ 关键图片


📊 实验亮点
实验结果表明,MAPLE在车辆路线规划等基准测试中,相较于传统方法,显著提高了样本效率和偏好推断质量。具体而言,MAPLE能够以更少的样本学习到更准确的偏好模型,并有效提高了人类用户回答查询的效率和准确性。具体提升幅度未知,需要在论文中查找。
🎯 应用场景
MAPLE框架可应用于各种需要用户偏好学习的场景,例如个性化推荐系统、机器人任务规划、自动驾驶路线规划等。通过结合自然语言反馈,MAPLE能够更有效地学习用户的偏好,并提供更符合用户需求的个性化服务。该研究的潜在价值在于降低偏好学习的成本,提高学习效率,并促进人机协作。
📄 摘要(原文)
The advent of large language models (LLMs) has sparked significant interest in using natural language for preference learning. However, existing methods often suffer from high computational burdens, taxing human supervision, and lack of interpretability. To address these issues, we introduce MAPLE, a framework for large language model-guided Bayesian active preference learning. MAPLE leverages LLMs to model the distribution over preference functions, conditioning it on both natural language feedback and conventional preference learning feedback, such as pairwise trajectory rankings. MAPLE also employs active learning to systematically reduce uncertainty in this distribution and incorporates a language-conditioned active query selection mechanism to identify informative and easy-to-answer queries, thus reducing human burden. We evaluate MAPLE's sample efficiency and preference inference quality across two benchmarks, including a real-world vehicle route planning benchmark using OpenStreetMap data. Our results demonstrate that MAPLE accelerates the learning process and effectively improves humans' ability to answer queries.