Refusal Tokens: A Simple Way to Calibrate Refusals in Large Language Models
作者: Neel Jain, Aditya Shrivastava, Chenyang Zhu, Daben Liu, Alfy Samuel, Ashwinee Panda, Anoop Kumar, Micah Goldblum, Tom Goldstein
分类: cs.LG, cs.CL
发布日期: 2024-12-09 (更新: 2025-08-29)
备注: 20 pages
💡 一句话要点
提出Refusal Tokens,通过简单方式校准大语言模型的拒绝行为
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 拒绝策略 安全AI 可控生成 拒绝令牌
📋 核心要点
- 现有方法训练多个模型以适应不同拒绝率需求,计算成本高昂且缺乏灵活性。
- 核心思想是在训练时引入拒绝令牌,并在推理时调整其生成概率来控制拒绝行为。
- 该方法无需额外微调即可控制拒绝率,通过干预生成过程实现灵活的拒绝策略。
📝 摘要(中文)
构建安全可靠的语言模型的关键在于使其能够适当地拒绝执行某些指令或回答某些问题。对于不同类别的用户查询,例如,不明确的问题、执行非法行为的指令或超出模型知识范围的查询,我们可能希望模型输出拒绝消息。然而,工程化能够拒绝回答此类问题的模型是复杂的,因为个体可能希望其模型对拒绝各种类别的查询表现出不同程度的敏感性,并且不同的用户可能希望有不同的拒绝率。目前默认的方法是训练多个模型,每个模型具有不同比例的来自每个类别的拒绝消息,以实现所需的拒绝率,这在计算上是昂贵的,并且可能需要训练新模型以适应每个用户对拒绝率的期望偏好。为了解决这些挑战,我们提出了拒绝令牌(refusal tokens),每个拒绝类别对应一个令牌,或者使用单个拒绝令牌,在训练期间将其添加到模型响应的前面。然后,我们展示了如何在推理期间增加或减少生成每个类别的拒绝令牌的概率,以控制模型的拒绝行为。拒绝令牌使得控制单个模型的拒绝率成为可能,而无需任何进一步的微调,只需在生成过程中进行选择性干预。
🔬 方法详解
问题定义:现有的大语言模型在处理用户请求时,缺乏灵活的拒绝机制。针对不同类型的请求(例如,不合理的问题、非法指令、超出知识范围的查询),模型难以根据用户偏好或安全需求进行适当的拒绝。传统方法需要训练多个模型,每个模型对应不同的拒绝率,这导致了巨大的计算开销和维护成本。此外,这种方法难以适应用户个性化的拒绝偏好,需要为每个用户定制模型。
核心思路:论文的核心思路是引入“拒绝令牌”(Refusal Tokens)。通过在训练数据中,将特定类别的拒绝令牌添加到模型拒绝回答的语句前,使模型学习到这些令牌与拒绝行为之间的关联。在推理阶段,可以通过调整这些拒绝令牌的生成概率,来控制模型对特定类型请求的拒绝程度。这种方法的核心在于解耦了模型的训练和拒绝策略的调整,使得可以在不重新训练模型的情况下,灵活地控制其拒绝行为。
技术框架:该方法的技术框架主要包含两个阶段:训练阶段和推理阶段。在训练阶段,首先需要定义一系列拒绝类别,并为每个类别创建一个对应的拒绝令牌。然后,在构建训练数据集时,对于需要模型拒绝的样本,在其目标输出前添加相应的拒绝令牌。使用该数据集训练大语言模型。在推理阶段,当模型接收到用户请求时,可以根据需要调整各个拒绝令牌的生成概率。例如,如果希望模型更严格地拒绝非法指令,可以提高对应拒绝令牌的生成概率。模型最终的输出将取决于调整后的令牌概率分布。
关键创新:该方法最重要的技术创新点在于将拒绝行为的控制从模型训练中解耦出来。与传统方法需要训练多个模型不同,该方法只需要训练一个模型,并通过在推理阶段调整拒绝令牌的生成概率来实现灵活的拒绝策略。这种方法极大地降低了计算成本,并提高了模型的适应性。此外,该方法还允许用户根据自己的偏好定制模型的拒绝行为,从而提高了用户体验。
关键设计:关键设计包括:1) 拒绝令牌的选取:选择与模型词汇表中现有词汇差异较大的特殊token,以避免混淆。2) 拒绝类别的划分:根据实际应用场景,合理划分拒绝类别,例如,非法指令、有害信息、超出知识范围等。3) 拒绝令牌概率的调整策略:可以采用多种策略来调整拒绝令牌的生成概率,例如,基于规则的方法、基于用户反馈的方法等。4) 损失函数的设计:在训练阶段,可以使用交叉熵损失函数来训练模型,并可以对拒绝令牌的预测进行加权,以提高模型的拒绝能力。
🖼️ 关键图片
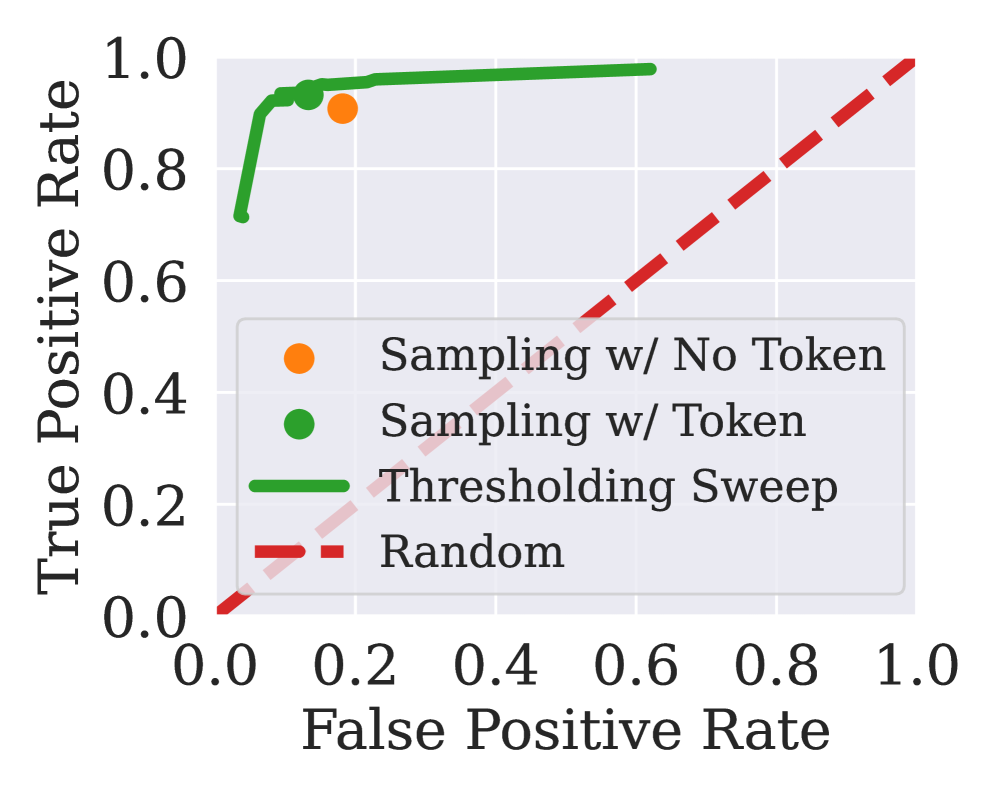
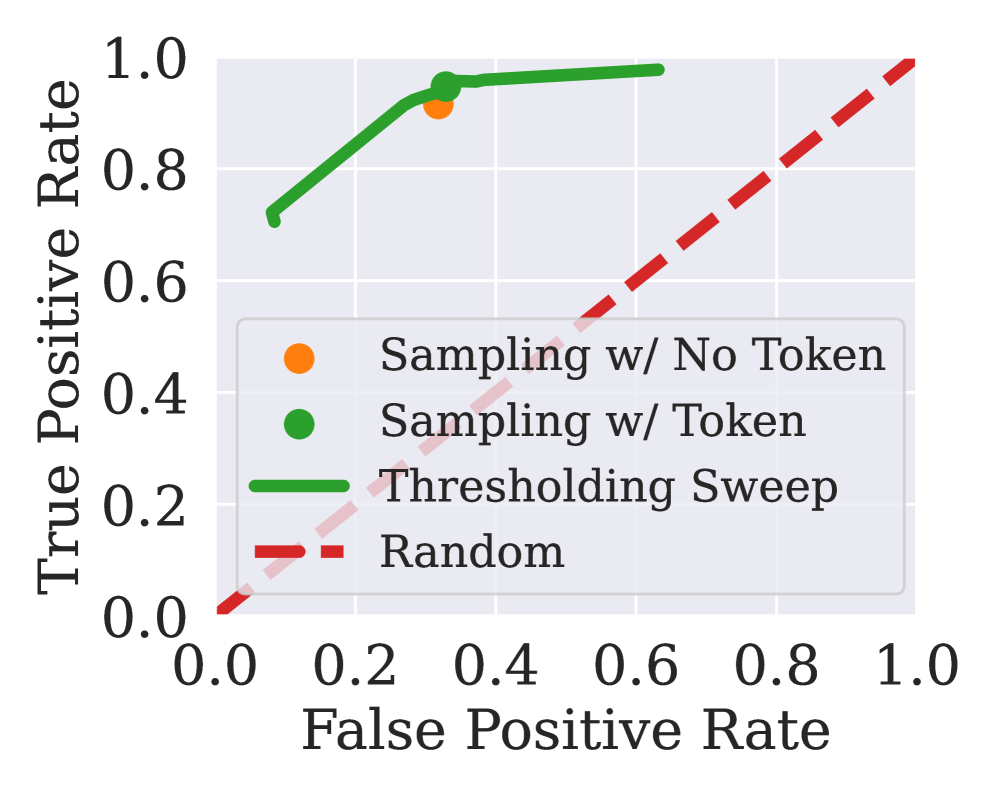
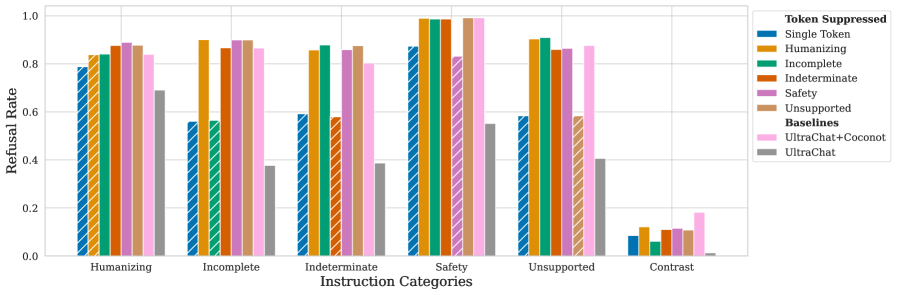
📊 实验亮点
论文提出的Refusal Tokens方法在控制大语言模型的拒绝行为方面表现出色。实验结果表明,该方法能够在不进行额外微调的情况下,有效调整模型对不同类别请求的拒绝率。与传统方法相比,该方法显著降低了计算成本,并提高了模型的适应性。具体性能数据未知,但论文强调了其在灵活性和效率方面的优势。
🎯 应用场景
该研究成果可广泛应用于各种需要安全可靠的大语言模型应用场景,例如智能客服、聊天机器人、内容生成等。通过灵活控制模型的拒绝行为,可以有效避免模型生成有害信息、泄露隐私或违反法律法规。此外,该方法还可以用于个性化定制模型的行为,以满足不同用户的需求。未来,该技术有望成为构建安全可信人工智能系统的关键组成部分。
📄 摘要(原文)
A key component of building safe and reliable language models is enabling the models to appropriately refuse to follow certain instructions or answer certain questions. We may want models to output refusal messages for various categories of user queries, for example, ill-posed questions, instructions for committing illegal acts, or queries which require information past the model's knowledge horizon. Engineering models that refuse to answer such questions is complicated by the fact that an individual may want their model to exhibit varying levels of sensitivity for refusing queries of various categories, and different users may want different refusal rates. The current default approach involves training multiple models with varying proportions of refusal messages from each category to achieve the desired refusal rates, which is computationally expensive and may require training a new model to accommodate each user's desired preference over refusal rates. To address these challenges, we propose refusal tokens, one such token for each refusal category or a single refusal token, which are prepended to the model's responses during training. We then show how to increase or decrease the probability of generating the refusal token for each category during inference to steer the model's refusal behavior. Refusal tokens enable controlling a single model's refusal rates without the need of any further fine-tuning, but only by selectively intervening during generation.