ONEBench to Test Them All: Sample-Level Benchmarking Over Open-Ended Capabilities
作者: Adhiraj Ghosh, Sebastian Dziadzio, Ameya Prabhu, Vishaal Udandarao, Samuel Albanie, Matthias Bethge
分类: cs.LG, cs.CL, cs.CV
发布日期: 2024-12-09 (更新: 2025-06-17)
💡 一句话要点
提出ONEBench:一个用于评估基础模型开放式能力的可扩展样本级基准测试框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 开放式评估 基准测试 基础模型 样本级评估 异构数据 不完整数据 聚合算法 模型评估
📋 核心要点
- 现有固定测试集无法充分评估基础模型的开放式能力,存在过拟合和数据集偏差等问题。
- ONEBench通过整合多个数据集样本,构建统一的可扩展样本池,支持自定义开放式评估基准。
- 提出的聚合算法能有效处理异构和不完整数据,实现可靠的模型排序,并显著降低评估成本。
📝 摘要(中文)
传统的固定测试集在评估基础模型的开放式能力方面存在不足。为了解决这个问题,我们提出了ONEBench(开放式基准测试),这是一种新的测试范式,它将各个评估数据集整合到一个统一的、不断扩展的样本池中。ONEBench允许用户从这个池中生成自定义的、开放式的评估基准,对应于特定的感兴趣的能力。通过聚合跨测试集的样本,ONEBench能够评估超出原始测试集所涵盖的各种能力,同时减轻过拟合和数据集偏差。最重要的是,它将模型评估构建为一个选择和聚合样本级测试的集体过程。从特定任务基准测试到ONEBench的转变带来了两个挑战:(1)异质性和(2)不完整性。异质性指的是对各种指标的聚合,而不完整性描述的是对在不同数据子集上评估的模型的比较。为了应对这些挑战,我们探索了将稀疏测量聚合为可靠模型分数的算法。我们的聚合算法确保了可识别性(渐近地恢复真实分数)和快速收敛,从而能够以更少的数据进行准确的模型排序。在同质数据集上,我们表明我们的聚合算法提供的排名与平均分数产生的排名高度相关。我们还展示了对约95%的缺失测量的鲁棒性,从而在模型排名几乎没有变化的情况下,将评估成本降低高达20倍。我们为语言模型引入了ONEBench-LLM,为视觉-语言模型引入了ONEBench-LMM,统一了这些领域的评估。总的来说,我们提出了一种开放式评估技术,它可以聚合不完整的、异构的样本级测量,从而随着快速发展的基础模型不断增长基准。
🔬 方法详解
问题定义:现有评估方法依赖于固定的、特定任务的数据集,无法全面评估基础模型的开放式能力。这些数据集容易导致模型过拟合,并且可能存在数据集偏差,使得评估结果不具有普适性。此外,针对不同任务的评估指标各不相同,难以进行统一比较。
核心思路:ONEBench的核心思路是将多个数据集的样本整合到一个统一的样本池中,允许用户根据需要选择样本子集,构建自定义的评估基准。通过这种方式,可以评估模型在各种不同场景下的能力,并减轻过拟合和数据集偏差的影响。同时,ONEBench还提出了一种聚合算法,用于处理不同评估指标和不完整数据,从而实现可靠的模型排序。
技术框架:ONEBench的整体框架包括以下几个主要模块:1) 样本池构建:将多个数据集的样本整合到一个统一的样本池中,并为每个样本标注相关信息,如所属数据集、评估指标等。2) 基准测试生成:用户可以根据需要选择样本池中的样本子集,构建自定义的评估基准。3) 模型评估:使用生成的基准测试评估模型性能,并记录每个样本的评估结果。4) 结果聚合:使用提出的聚合算法,将不同样本的评估结果聚合为模型的整体性能得分。
关键创新:ONEBench最重要的技术创新点在于其开放式评估范式和聚合算法。开放式评估范式允许用户根据需要构建自定义的评估基准,从而更全面地评估模型的开放式能力。聚合算法能够有效处理异构和不完整数据,从而实现可靠的模型排序。与现有方法相比,ONEBench能够更好地评估模型的泛化能力和鲁棒性。
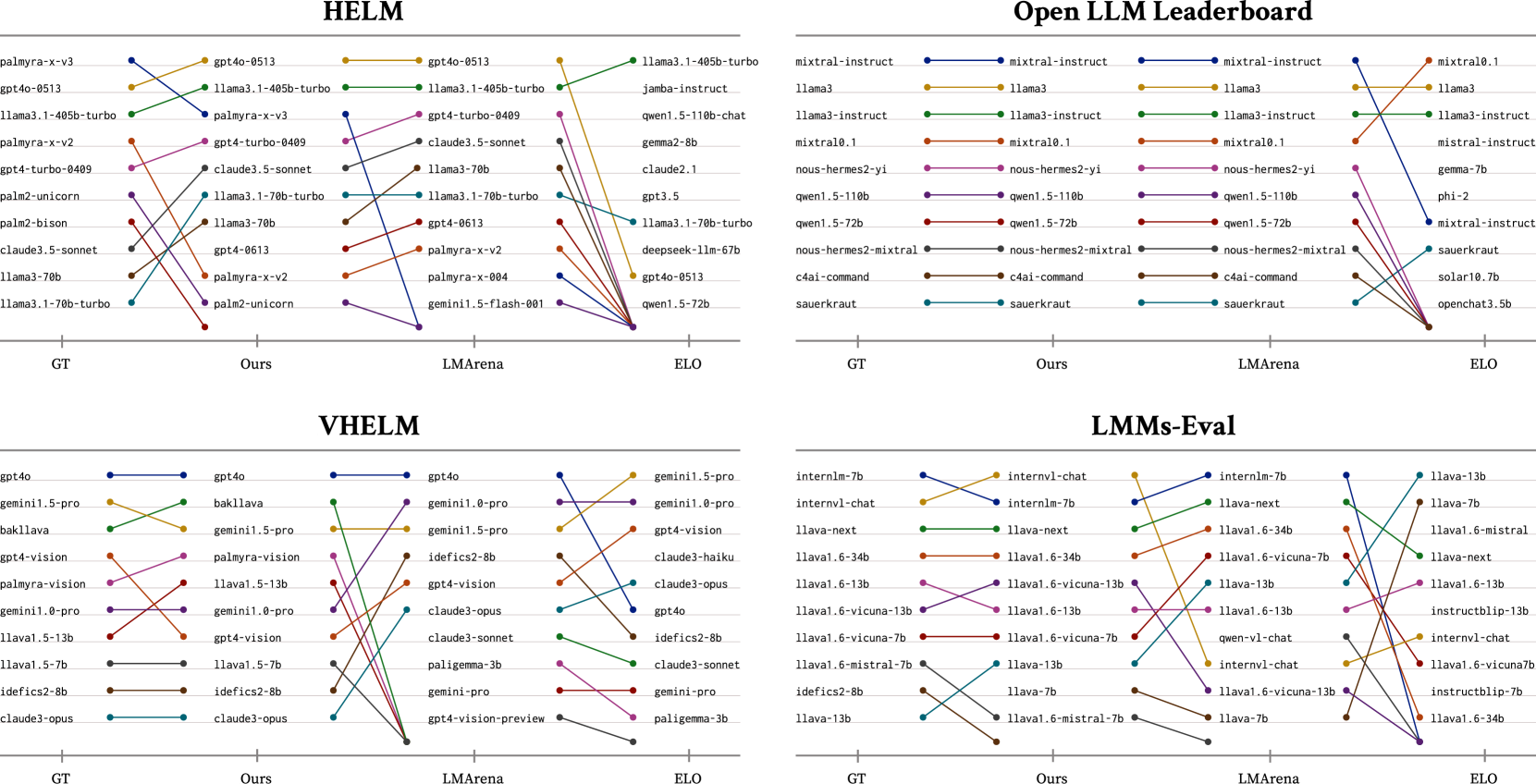
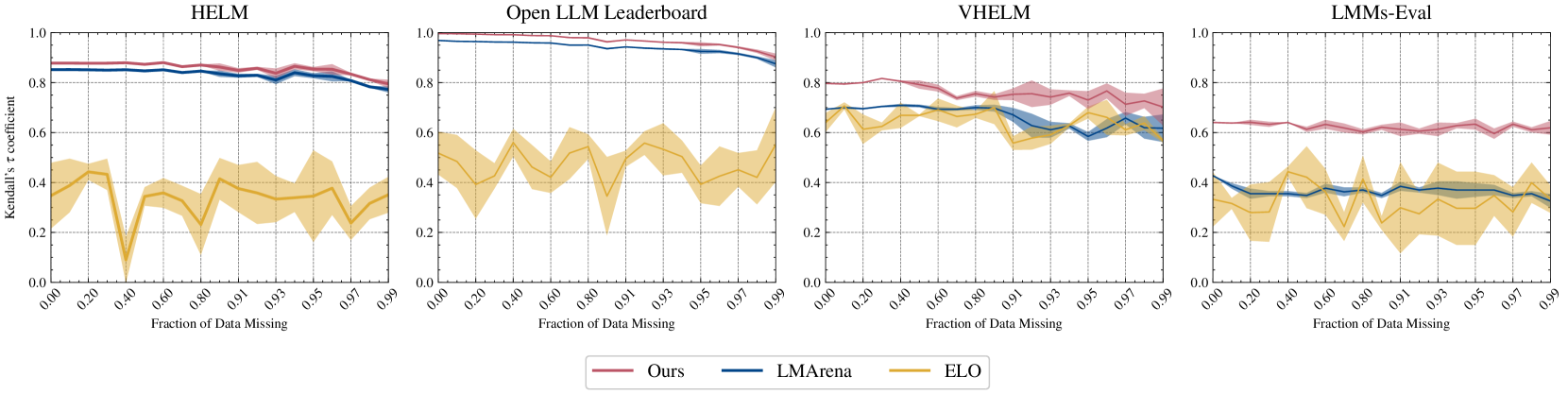
关键设计:ONEBench的聚合算法旨在解决异构性和不完整性问题。具体来说,该算法通过引入可识别性约束,确保能够渐近地恢复模型的真实性能得分。此外,该算法还采用了快速收敛的设计,从而能够以较少的数据实现准确的模型排序。在实验中,作者展示了该算法对高达95%的缺失测量具有鲁棒性,从而显著降低了评估成本。
🖼️ 关键图片

📊 实验亮点
实验结果表明,ONEBench的聚合算法能够有效处理异构和不完整数据,实现可靠的模型排序。在同质数据集上,该算法提供的排名与平均分数产生的排名高度相关。此外,该算法对高达95%的缺失测量具有鲁棒性,从而在模型排名几乎没有变化的情况下,将评估成本降低高达20倍。
🎯 应用场景
ONEBench可应用于各种基础模型的评估,例如语言模型和视觉-语言模型。它可以帮助研究人员和开发者更全面地了解模型的性能,并发现模型的潜在问题。此外,ONEBench还可以用于模型选择和优化,从而提高模型的性能和泛化能力。未来,ONEBench有望成为基础模型评估的标准工具。
📄 摘要(原文)
Traditional fixed test sets fall short in evaluating open-ended capabilities of foundation models. To address this, we propose ONEBench(OpeN-Ended Benchmarking), a new testing paradigm that consolidates individual evaluation datasets into a unified, ever-expanding sample pool. ONEBench allows users to generate custom, open-ended evaluation benchmarks from this pool, corresponding to specific capabilities of interest. By aggregating samples across test sets, ONEBench enables the assessment of diverse capabilities beyond those covered by the original test sets, while mitigating overfitting and dataset bias. Most importantly, it frames model evaluation as a collective process of selecting and aggregating sample-level tests. The shift from task-specific benchmarks to ONEBench introduces two challenges: (1)heterogeneity and (2)incompleteness. Heterogeneity refers to the aggregation over diverse metrics, while incompleteness describes comparing models evaluated on different data subsets. To address these challenges, we explore algorithms to aggregate sparse measurements into reliable model scores. Our aggregation algorithm ensures identifiability(asymptotically recovering ground-truth scores) and rapid convergence, enabling accurate model ranking with less data. On homogenous datasets, we show our aggregation algorithm provides rankings that highly correlate with those produced by average scores. We also demonstrate robustness to ~95% of measurements missing, reducing evaluation cost by up to 20x with little-to-no change in model rankings. We introduce ONEBench-LLM for language models and ONEBench-LMM for vision-language models, unifying evaluations across these domains. Overall, we present a technique for open-ended evaluation, which can aggregate over incomplete, heterogeneous sample-level measurements to continually grow a benchmark alongside the rapidly developing foundation models.