I Don't Know: Explicit Modeling of Uncertainty with an [IDK] Token
作者: Roi Cohen, Konstantin Dobler, Eden Biran, Gerard de Melo
分类: cs.LG, cs.CL
发布日期: 2024-12-09
备注: Published at NeurIPS 2024
💡 一句话要点
提出基于[IDK] Token的校准方法,显式建模语言模型的不确定性,抑制幻觉。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 不确定性建模 幻觉抑制 知识校准 [IDK] Token 自然语言处理 问答系统
📋 核心要点
- 大型语言模型易产生幻觉,输出错误信息,降低了其可靠性。
- 引入[IDK] token,并设计目标函数,使模型能显式表达不确定性,避免错误输出。
- 实验表明,该方法能有效抑制幻觉,同时知识损失较小,提升模型可靠性。
📝 摘要(中文)
大型语言模型能够捕捉现实世界的知识,并在许多下游任务中表现出色。然而,这些模型仍然容易产生幻觉,输出不准确的文本。本文提出了一种新的校准方法来对抗幻觉。该方法在模型的词汇表中添加一个特殊的[IDK](“我不知道”)token,并引入一个目标函数,将不正确预测的概率质量转移到[IDK] token上。这使得模型能够显式地表达输出中的不确定性。我们在多个模型架构和事实性下游任务上评估了该方法。结果表明,使用该方法训练的模型能够在之前容易出错的地方表达不确定性,同时仅损失少量编码知识。我们还对该方法的多个变体进行了广泛的消融研究,并提供了该方法在精确率-召回率权衡方面的详细分析。
🔬 方法详解
问题定义:大型语言模型虽然在很多任务上表现出色,但容易产生“幻觉”,即生成不真实或不准确的信息。现有的方法难以有效抑制这种幻觉,导致模型在需要高可靠性的场景中应用受限。
核心思路:核心思想是让模型能够显式地表达“我不知道”的状态,而不是被迫输出一个可能错误的答案。通过引入一个特殊的[IDK] token,并训练模型在不确定时输出该token,从而避免生成虚假信息。
技术框架:该方法主要包含以下几个步骤:1) 在模型的词汇表中添加[IDK] token;2) 修改训练目标,对于模型预测错误的情况,增加[IDK] token的概率;3) 在推理阶段,如果[IDK] token的概率超过一定阈值,则认为模型不确定,拒绝回答。
关键创新:关键创新在于显式地建模了模型的不确定性。与以往隐式地通过调整模型参数来抑制幻觉的方法不同,该方法直接让模型学会表达“不知道”,从而更有效地避免了错误信息的生成。
关键设计:目标函数的设计是关键。论文设计了一个损失函数,该函数鼓励模型在预测错误时将概率质量转移到[IDK] token上。具体来说,该损失函数可以表示为 L = L_original + λ * L_IDK,其中L_original是原始的损失函数,L_IDK是鼓励输出[IDK] token的损失函数,λ是一个超参数,用于控制[IDK] token损失的权重。此外,[IDK] token的概率阈值也是一个重要的参数,需要根据具体的任务和数据集进行调整。
🖼️ 关键图片

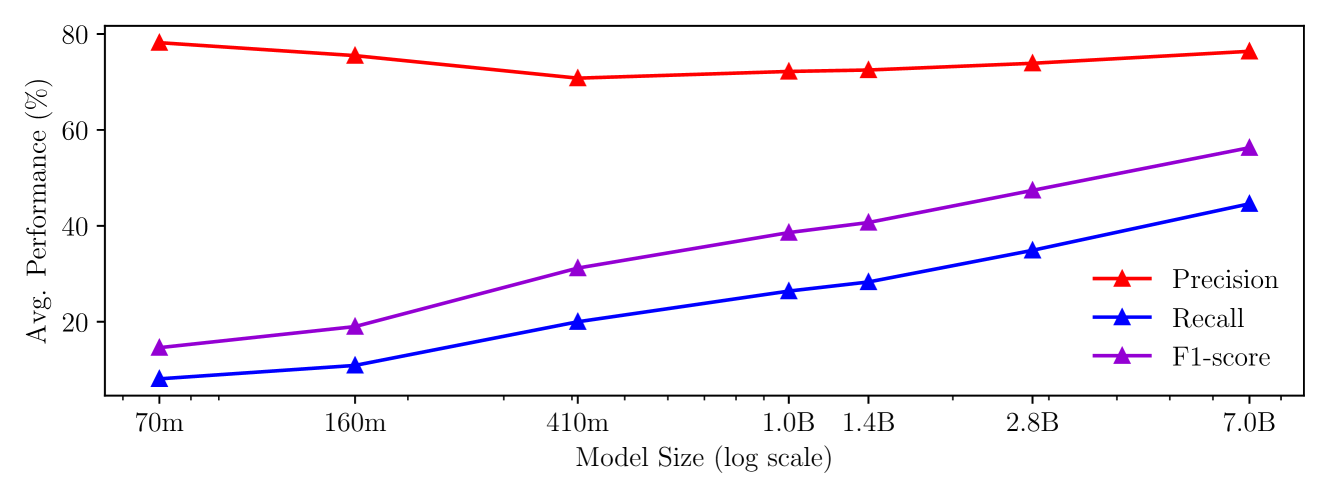
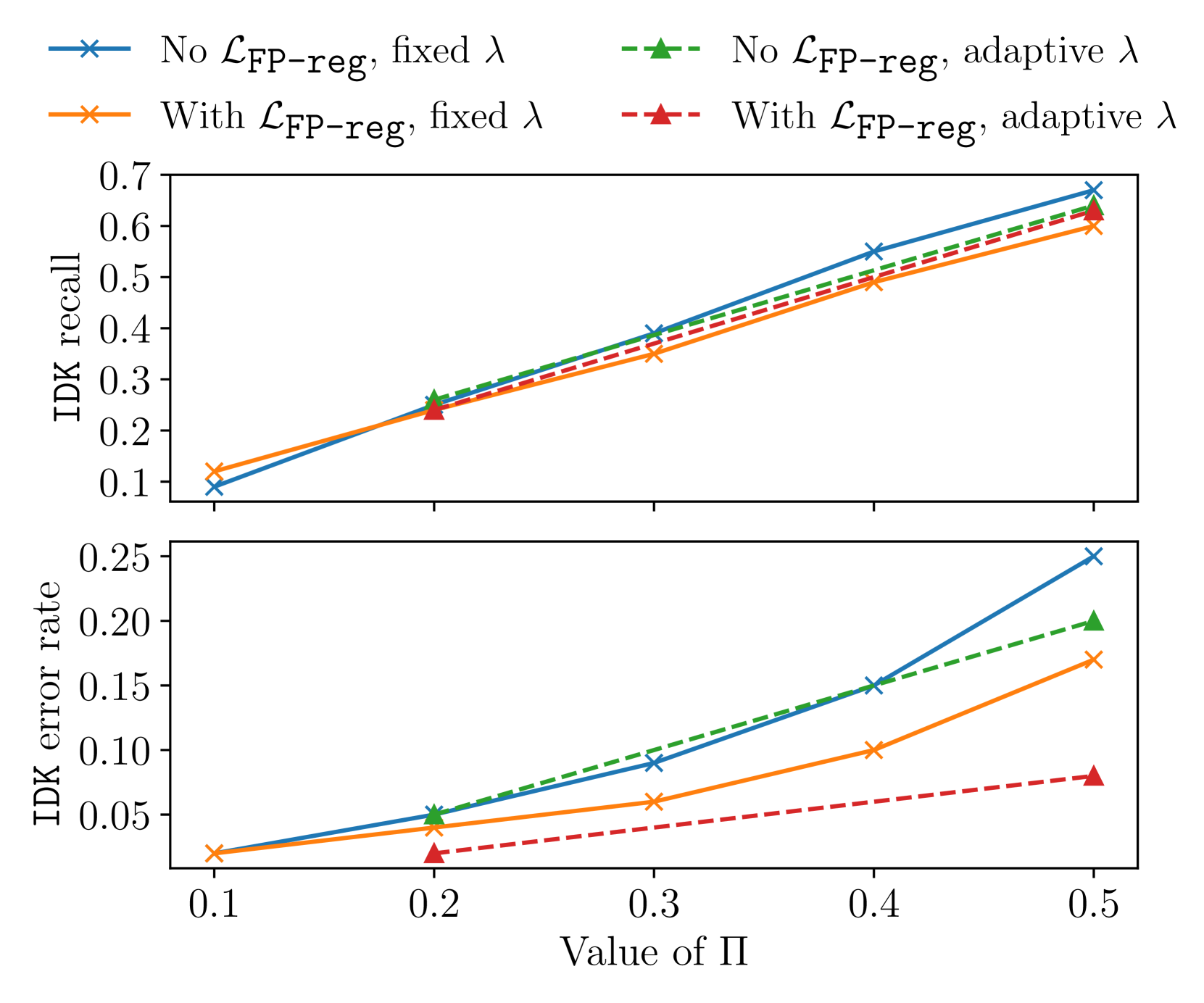
📊 实验亮点
实验结果表明,使用该方法训练的模型能够在多个事实性下游任务上有效抑制幻觉,同时仅损失少量编码知识。具体来说,模型在生成错误信息方面的比例显著降低,并且在需要高可靠性的场景中表现出更好的性能。消融实验表明,[IDK] token的损失权重λ和概率阈值的选择对模型的性能有重要影响。
🎯 应用场景
该研究成果可应用于需要高可靠性的自然语言处理任务中,例如问答系统、信息检索、对话系统等。通过显式地建模模型的不确定性,可以有效避免模型生成虚假信息,提高系统的可靠性和用户体验。未来,该方法还可以扩展到其他类型的模型和任务中,例如图像识别、语音识别等。
📄 摘要(原文)
Large Language Models are known to capture real-world knowledge, allowing them to excel in many downstream tasks. Despite recent advances, these models are still prone to what are commonly known as hallucinations, causing them to emit unwanted and factually incorrect text. In this work, we propose a novel calibration method that can be used to combat hallucinations. We add a special [IDK] ("I don't know") token to the model's vocabulary and introduce an objective function that shifts probability mass to the [IDK] token for incorrect predictions. This approach allows the model to express uncertainty in its output explicitly. We evaluate our proposed method across multiple model architectures and factual downstream tasks. We find that models trained with our method are able to express uncertainty in places where they would previously make mistakes while suffering only a small loss of encoded knowledge. We further perform extensive ablation studies of multiple variations of our approach and provide a detailed analysis of the precision-recall tradeoff of our method.