Enhancing LLMs for Physics Problem-Solving using Reinforcement Learning with Human-AI Feedback
作者: Avinash Anand, Kritarth Prasad, Chhavi Kirtani, Ashwin R Nair, Mohit Gupta, Saloni Garg, Anurag Gautam, Snehal Buldeo, Rajiv Ratn Shah
分类: cs.LG, cs.AI
发布日期: 2024-12-06
💡 一句话要点
提出基于人类-AI反馈强化学习的LLM物理问题求解增强方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 物理问题求解 人类-AI反馈 近端策略优化
📋 核心要点
- 现有LLM在解决需要复杂推理的物理问题时存在不足,尤其是在高级算术和概念理解方面。
- 论文提出了一种基于人类和人工智能反馈的强化学习(RLHAIF)方法,以提升LLM在物理问题求解上的性能。
- 实验结果表明,RLHAIF模型在LLaMA2和Mistral等LLM上表现出显著的改进,尤其是在推理和准确性方面。
📝 摘要(中文)
大型语言模型(LLMs)在基于文本的任务中表现出强大的能力,但在物理问题所需的复杂推理方面存在困难,尤其是在高级算术和概念理解方面。尽管一些研究探索了使用诸如提示工程和检索增强生成(RAG)等技术来增强LLM在物理教育中的应用,但在解决它们在物理推理方面的局限性方面投入的精力还不够。本文提出了一种新颖的方法,利用基于人类和人工智能反馈的强化学习(RLHAIF)来提高LLM在物理问题上的性能。我们评估了几种强化学习方法,包括近端策略优化(PPO)、直接偏好优化(DPO)和Remax优化。选择这些方法是为了研究RL策略在PhyQA数据集上不同设置下的性能,该数据集包含来自高中教科书的具有挑战性的物理问题。我们的RLHAIF模型在LLaMA2和Mistral等领先的LLM上进行了测试,取得了优异的成绩,特别是MISTRAL-PPO模型,在推理和准确性方面表现出显著的改进。它取得了很高的分数,METEOR得分为58.67,推理得分为0.74,使其成为该领域未来物理推理研究的有力范例。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在物理问题求解中存在的推理能力不足的问题,尤其是在处理需要高级算术和概念理解的复杂物理问题时。现有方法,如简单的prompt工程和检索增强生成(RAG),无法有效提升LLM的物理推理能力,导致其在物理问题上的表现不佳。
核心思路:论文的核心思路是利用强化学习(RL)来训练LLM,使其能够更好地进行物理推理。通过引入人类和人工智能的反馈(RLHAIF),可以更有效地指导LLM的学习过程,使其能够学习到更准确、更有效的物理问题求解策略。这种方法旨在克服传统方法在处理复杂推理问题时的局限性。
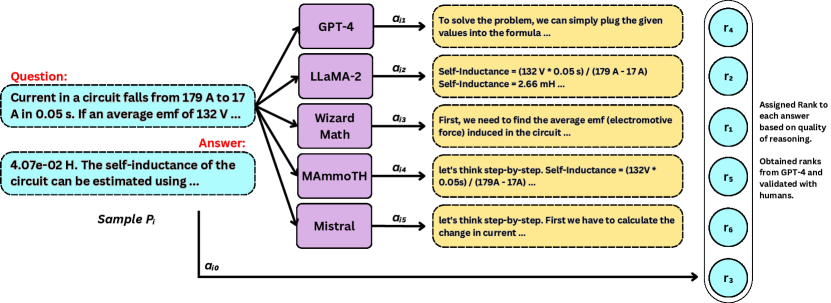
技术框架:整体框架包括以下几个主要模块:1) LLM作为策略网络,负责生成物理问题的解答;2) 强化学习算法(PPO、DPO、Remax)用于优化LLM的策略;3) 人类和人工智能反馈模块,用于提供奖励信号,指导LLM的学习方向;4) PhyQA数据集,包含高中物理问题,用于训练和评估模型。整个流程是:LLM根据问题生成解答,然后根据人类或AI的反馈计算奖励,最后使用强化学习算法更新LLM的参数。
关键创新:该论文的关键创新在于将人类和人工智能反馈融入到强化学习框架中,用于训练LLM解决物理问题。与传统的强化学习方法相比,RLHAIF能够更有效地利用人类的知识和经验,以及AI的计算能力,从而提高LLM的推理能力和准确性。此外,论文还探索了不同的强化学习算法(PPO、DPO、Remax)在物理问题求解中的应用,并比较了它们的性能。
关键设计:论文中关键的设计包括:1) 使用PhyQA数据集作为训练和评估数据;2) 采用不同的强化学习算法(PPO、DPO、Remax)进行实验;3) 设计合适的奖励函数,以反映解答的正确性和推理的合理性;4) 探索不同LLM(LLaMA2、Mistral)在RLHAIF框架下的性能。具体的参数设置和网络结构在论文中可能没有详细描述,属于未知信息。
🖼️ 关键图片

📊 实验亮点
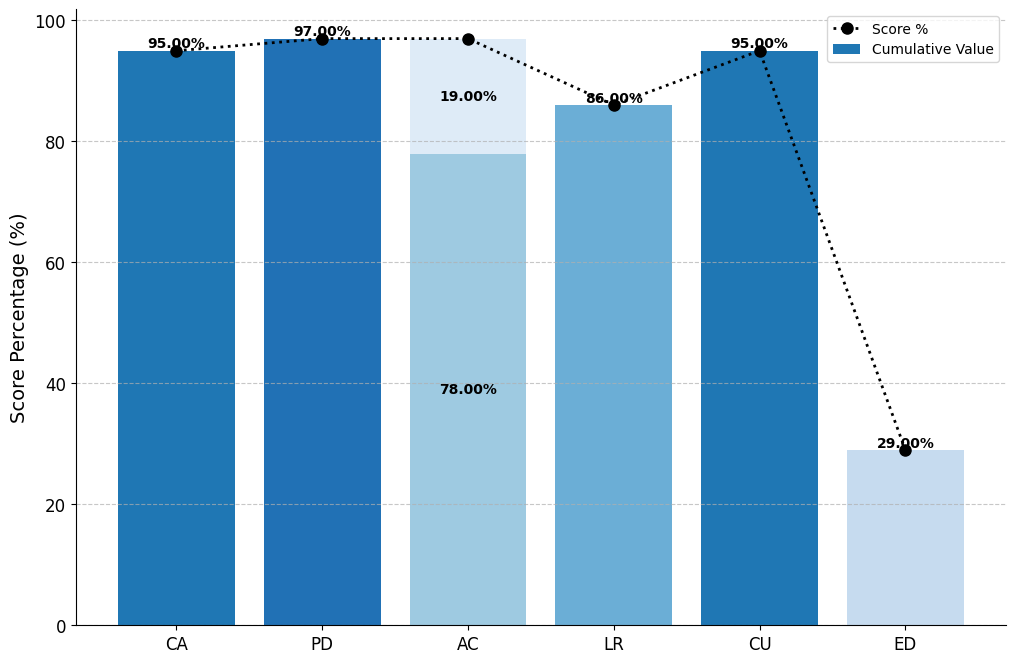
实验结果表明,基于RLHAIF的MISTRAL-PPO模型在PhyQA数据集上取得了显著的性能提升,METEOR得分为58.67,推理得分为0.74。这些结果表明,RLHAIF方法能够有效提高LLM在物理问题求解中的推理能力和准确性。与基线模型相比,该方法在各项指标上均有明显提升,证明了其有效性。
🎯 应用场景
该研究成果可应用于在线教育平台、智能辅导系统和物理学习辅助工具等领域。通过提升LLM在物理问题求解方面的能力,可以为学生提供更个性化、更有效的学习体验,帮助他们更好地理解和掌握物理知识。此外,该方法还可以推广到其他科学领域的教育和研究中,具有广阔的应用前景。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated strong capabilities in text-based tasks but struggle with the complex reasoning required for physics problems, particularly in advanced arithmetic and conceptual understanding. While some research has explored ways to enhance LLMs in physics education using techniques such as prompt engineering and Retrieval Augmentation Generation (RAG), not enough effort has been made in addressing their limitations in physics reasoning. This paper presents a novel approach to improving LLM performance on physics questions using Reinforcement Learning with Human and Artificial Intelligence Feedback (RLHAIF). We evaluate several reinforcement learning methods, including Proximal Policy Optimization (PPO), Direct Preference Optimization (DPO), and Remax optimization. These methods are chosen to investigate RL policy performance with different settings on the PhyQA dataset, which includes challenging physics problems from high school textbooks. Our RLHAIF model, tested on leading LLMs like LLaMA2 and Mistral, achieved superior results, notably with the MISTRAL-PPO model, demonstrating marked improvements in reasoning and accuracy. It achieved high scores, with a 58.67 METEOR score and a 0.74 Reasoning score, making it a strong example for future physics reasoning research in this area.