Multi-Objective Alignment of Large Language Models Through Hypervolume Maximization
作者: Subhojyoti Mukherjee, Anusha Lalitha, Sailik Sengupta, Aniket Deshmukh, Branislav Kveton
分类: cs.LG
发布日期: 2024-12-06
💡 一句话要点
提出HaM算法,通过最大化超体积实现大语言模型的多目标对齐
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多目标优化 大语言模型 人类反馈 超体积最大化 策略学习
📋 核心要点
- 人类偏好的复杂性和冲突性使得大语言模型的多目标对齐极具挑战,现有方法依赖于预先定义的人类偏好。
- HaM算法通过最大化超体积来学习多样化的LLM策略,旨在覆盖帕累托前沿,无需预先了解人类偏好。
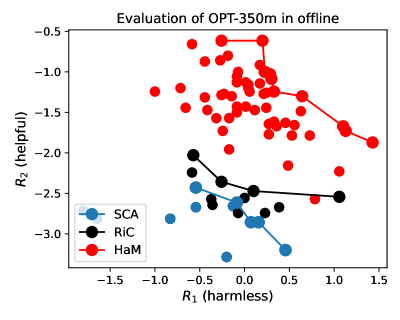
- 实验结果表明,HaM算法在多个目标(如无害性、有用性等)上优于现有方法,且计算和空间效率更高。
📝 摘要(中文)
大语言模型(LLM)中来自人类反馈的多目标对齐(MOAHF)是一个具有挑战性的问题,因为人类偏好是复杂、多方面的且常常相互冲突的。最近关于MOAHF的工作考虑了先验多目标优化(MOO),其中人类偏好在训练或推理时已知。相比之下,当人类偏好未知或难以量化时,一个自然的方法是通过多个不同的解决方案来覆盖帕累托前沿。我们提出了一种名为HaM的算法,用于学习多样化的LLM策略,该算法最大化它们的超体积。这是后验MOO首次应用于MOAHF。HaM在计算和空间上是高效的,并且在各种数据集上,在诸如无害性、有用性、幽默性、忠实性和幻觉等目标上,经验性地优于现有方法。
🔬 方法详解
问题定义:论文旨在解决大语言模型中多目标对齐(MOAHF)问题,特别是当人类偏好未知或难以量化时。现有方法通常依赖于预先定义的人类偏好,这限制了模型的泛化能力和适应性。这些方法无法有效地探索和覆盖帕累托前沿,导致模型在多个目标上的表现不均衡。
核心思路:论文的核心思路是采用后验多目标优化(MOO)方法,通过最大化超体积来学习多样化的LLM策略。超体积代表了帕累托前沿所覆盖的空间大小,最大化超体积意味着模型能够生成更多样化且高质量的解决方案,从而更好地满足不同用户的需求和偏好。这种方法无需预先了解人类偏好,而是通过探索帕累托前沿来发现潜在的优化方向。
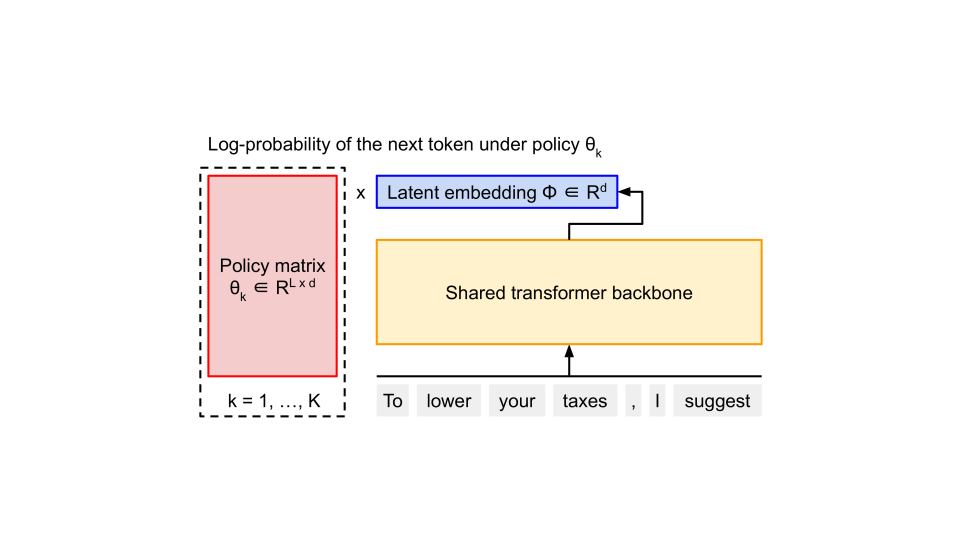
技术框架:HaM算法的整体框架包括以下几个主要阶段:1)策略初始化:初始化一组LLM策略,这些策略代表了不同的行为模式。2)策略评估:使用一组预定义的评估指标(例如,无害性、有用性、幽默性等)来评估每个策略的性能。3)超体积计算:计算当前策略集合的超体积,超体积越大,表示策略的多样性和质量越高。4)策略更新:使用优化算法(例如,梯度下降)来更新策略,目标是最大化超体积。这个过程迭代进行,直到超体积达到收敛或达到预定的迭代次数。
关键创新:该论文的关键创新在于将后验多目标优化(MOO)方法应用于大语言模型的多目标对齐(MOAHF)问题。与现有方法相比,HaM算法无需预先定义人类偏好,而是通过最大化超体积来学习多样化的LLM策略,从而更好地覆盖帕累托前沿。这是后验MOO首次应用于MOAHF,为解决人类偏好未知或难以量化的问题提供了一种新的思路。
关键设计:HaM算法的关键设计包括:1)超体积计算方法:采用高效的超体积计算方法,以降低计算复杂度。2)策略更新策略:使用梯度下降等优化算法来更新策略,并引入正则化项以防止过拟合。3)评估指标选择:选择一组具有代表性的评估指标,以全面评估策略的性能。4)超参数设置:通过实验调整超参数,例如学习率、正则化系数等,以获得最佳的性能。
🖼️ 关键图片

📊 实验亮点
实验结果表明,HaM算法在多个目标(如无害性、有用性、幽默性、忠实性和幻觉)上优于现有方法。具体而言,HaM算法在超体积指标上取得了显著提升,表明其能够生成更多样化且高质量的解决方案。此外,HaM算法在计算和空间效率方面也表现出色,使其能够应用于更大规模的模型和数据集。
🎯 应用场景
该研究成果可应用于各种需要平衡多个目标的大语言模型应用场景,例如智能客服、内容生成、对话系统等。通过学习多样化的策略,模型可以更好地适应不同用户的需求和偏好,提高用户满意度和体验。此外,该方法还可以用于探索新的优化方向,发现潜在的创新点,推动大语言模型的发展。
📄 摘要(原文)
Multi-objective alignment from human feedback (MOAHF) in large language models (LLMs) is a challenging problem as human preferences are complex, multifaceted, and often conflicting. Recent works on MOAHF considered a-priori multi-objective optimization (MOO), where human preferences are known at training or inference time. In contrast, when human preferences are unknown or difficult to quantify, a natural approach is to cover the Pareto front by multiple diverse solutions. We propose an algorithm HaM for learning diverse LLM policies that maximizes their hypervolume. This is the first application of a-posteriori MOO to MOAHF. HaM is computationally and space efficient, and empirically superior across objectives such as harmlessness, helpfulness, humor, faithfulness, and hallucination, on various datasets.