IterL2Norm: Fast Iterative L2-Normalization
作者: ChangMin Ye, Yonguk Sim, Youngchae Kim, SeongMin Jin, Doo Seok Jeong
分类: cs.LG
发布日期: 2024-12-06 (更新: 2025-01-17)
备注: Design, Automation & Test in Europe Conference 2025
💡 一句话要点
提出IterL2Norm以解决Transformer模型的层归一化效率问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 层归一化 迭代算法 Transformer模型 深度学习 计算效率 CMOS实现 数据移动
📋 核心要点
- 现有的层归一化方法在数据移动上存在瓶颈,影响了Transformer模型的整体性能。
- 本文提出的IterL2Norm方法通过迭代方式实现L2归一化,确保快速收敛并提高精度。
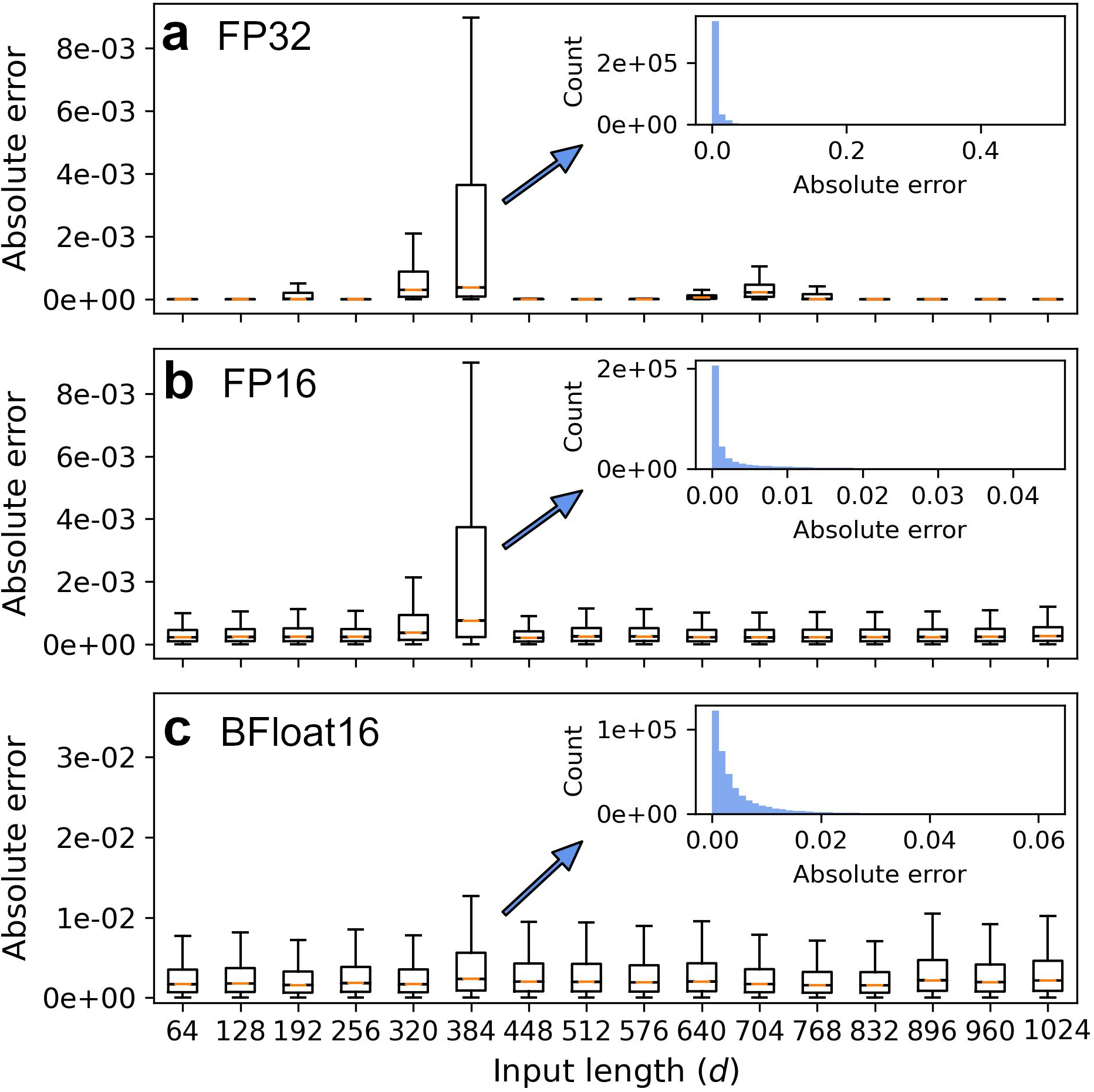
- 实验结果显示,IterL2Norm在FP32和BFloat16精度下,分别在六个和五个案例中超越了快速逆平方根算法。
📝 摘要(中文)
基于Transformer的大型语言模型在操作时受限于内存,数据在主机与加速器之间的移动会显著影响总的计算时间。层归一化是Transformer模型中的关键工作负载之一。为减少数据移动,层归一化需在与矩阵乘法引擎同一芯片上进行。本文提出了一种针对一维输入的迭代L2归一化方法(IterL2Norm),确保在五次迭代内快速收敛至稳态解,并且在精度上超过了快速逆平方根算法。该方法在32/28nm CMOS中实现,能够对$d$维向量进行归一化,延迟为116-227个周期,适用于100MHz/1.05V的工作条件。
🔬 方法详解
问题定义:本文旨在解决Transformer模型中层归一化的效率问题,现有方法在数据移动上存在显著的延迟,影响整体性能。
核心思路:IterL2Norm通过迭代方式对一维输入进行L2归一化,设计上确保在五次迭代内快速收敛到稳态解,从而减少数据移动带来的延迟。
技术框架:该方法的整体架构包括输入数据的预处理、迭代归一化过程以及最终的输出结果。主要模块包括矩阵乘法引擎和归一化模块,二者在同一芯片上协同工作。
关键创新:IterL2Norm的核心创新在于其迭代归一化策略,显著提高了收敛速度和精度,相较于传统的快速逆平方根算法,表现出更优的性能。
关键设计:在设计中,参数设置为$d$维向量,范围为64到1024,延迟控制在116-227个周期,适用于100MHz/1.05V的工作条件。
🖼️ 关键图片


📊 实验亮点
实验结果表明,IterL2Norm在FP32精度下在六个案例中超越了快速逆平方根算法,在BFloat16精度下在五个案例中表现优异,显示出显著的性能提升,验证了其在实际应用中的有效性。
🎯 应用场景
该研究的潜在应用领域包括大型语言模型的加速和优化,尤其是在需要高效层归一化的深度学习任务中。其实际价值在于提高模型的计算效率,降低能耗,未来可能对AI模型的实时应用产生积极影响。
📄 摘要(原文)
Transformer-based large language models are a memory-bound model whose operation is based on a large amount of data that are marginally reused. Thus, the data movement between a host and accelerator likely dictates the total wall-clock time. Layer normalization is one of the key workloads in the transformer model, following each of multi-head attention and feed-forward network blocks. To reduce data movement, layer normalization needs to be performed on the same chip as the matrix-matrix multiplication engine. To this end, we introduce an iterative L2-normalization method for 1D input (IterL2Norm), ensuring fast convergence to the steady-state solution within five iteration steps and high precision, outperforming the fast inverse square root algorithm in six out of nine cases for FP32 and five out of nine for BFloat16 across the embedding lengths used in the OPT models. Implemented in 32/28nm CMOS, the IterL2Norm macro normalizes $d$-dimensional vectors, where $64 \leq d \leq 1024$, with a latency of 116-227 cycles at 100MHz/1.05V.