Closed-Loop Supervised Fine-Tuning of Tokenized Traffic Models
作者: Zhejun Zhang, Peter Karkus, Maximilian Igl, Wenhao Ding, Yuxiao Chen, Boris Ivanovic, Marco Pavone
分类: cs.LG
发布日期: 2024-12-05 (更新: 2025-03-14)
备注: CVPR 2025. Project Page: https://zhejz.github.io/catk/
🔗 代码/项目: GITHUB
💡 一句话要点
提出CAT-K闭环微调策略,提升Token化交通模型在交通仿真中的性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 交通仿真 Token化模型 闭环微调 协变量偏移 行为克隆
📋 核心要点
- 现有Token化交通模型通常采用开环行为克隆训练,导致在闭环仿真中出现协变量偏移,影响仿真效果。
- CAT-K通过在Top-K预测结果中选择与真实轨迹最接近的 rollout 进行微调,有效缓解了协变量偏移问题。
- 实验表明,CAT-K微调能显著提升Token化交通模型的性能,甚至超越更大规模的模型,并在Waymo挑战赛中取得领先。
📝 摘要(中文)
本文提出了一种名为Closest Among Top-K (CAT-K) rollouts的闭环微调策略,旨在缓解Token化多智能体交通策略在交通仿真中因开环训练导致的协变量偏移问题。CAT-K微调仅需现有轨迹数据,无需强化学习或生成对抗模仿学习。实验结果表明,一个仅有700万参数的Token化交通仿真策略,通过CAT-K微调,性能超越了同模型族中拥有1.02亿参数的模型,并在Waymo Sim Agent Challenge排行榜上名列前茅。代码已开源。
🔬 方法详解
问题定义:现有交通仿真方法,特别是基于Token化多智能体策略的方法,通常采用开环行为克隆进行训练。这种训练方式忽略了智能体之间的交互以及环境的动态变化,导致在闭环仿真过程中出现协变量偏移,即模型在训练数据上表现良好,但在实际仿真环境中性能下降。现有方法难以有效解决闭环仿真中的长期依赖和误差累积问题。
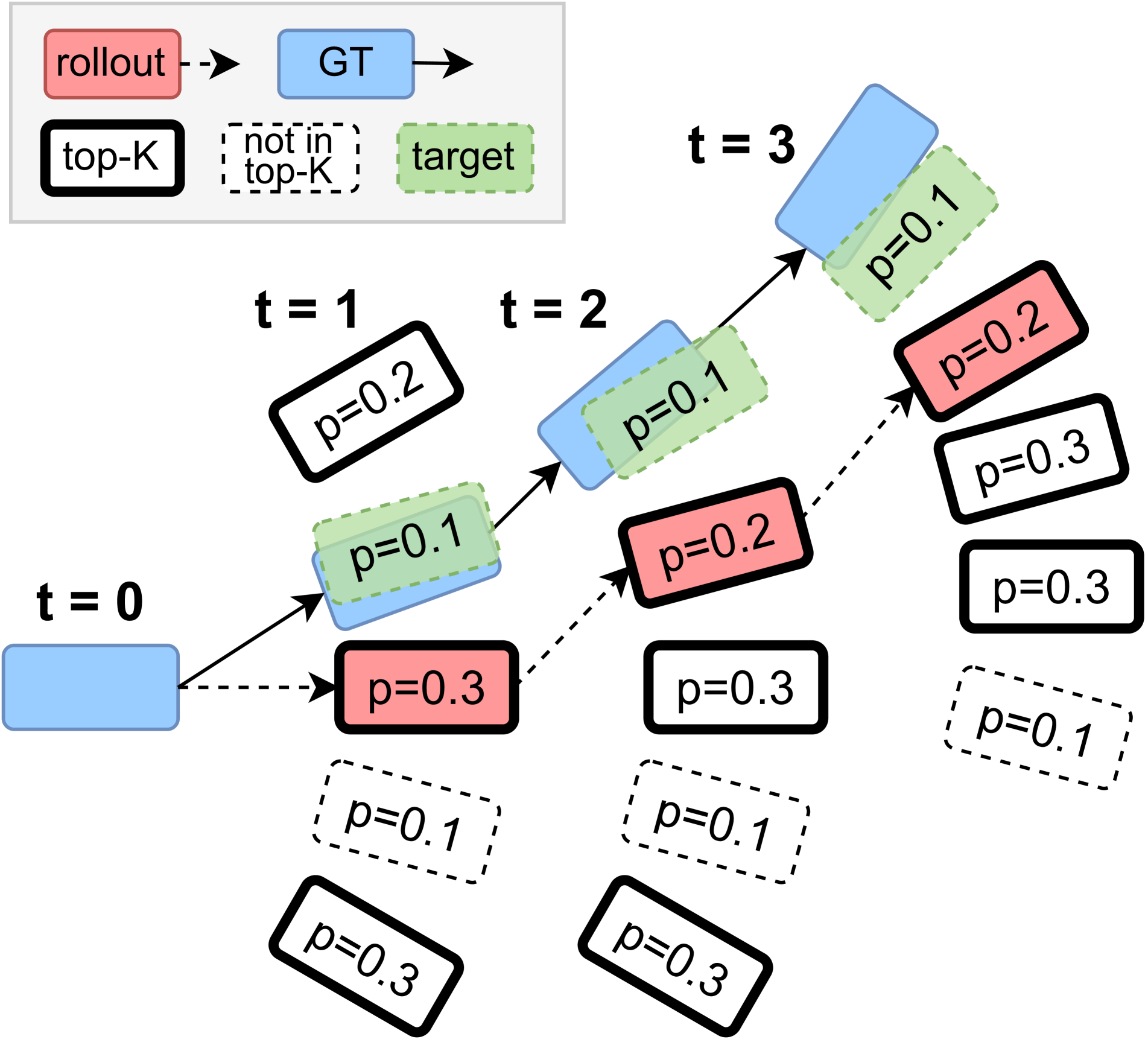
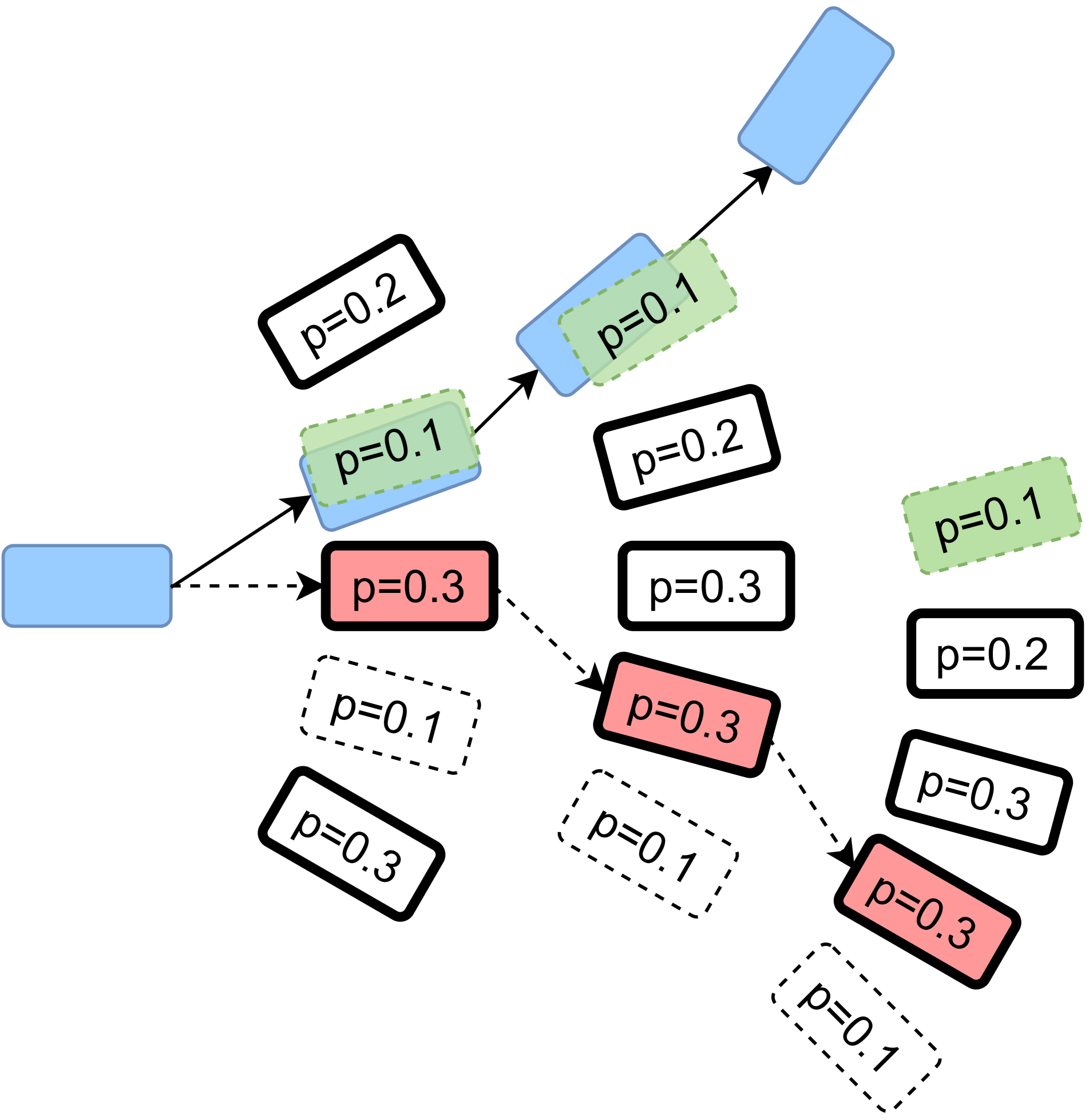
核心思路:CAT-K的核心思路是利用已有的轨迹数据,通过闭环的方式对Token化交通模型进行微调,从而缓解协变量偏移。具体而言,对于每个时间步,模型生成Top-K个可能的轨迹预测,然后选择与真实轨迹最接近的预测进行学习。这种方式使得模型能够更好地适应闭环仿真环境,并减少误差累积。
技术框架:CAT-K微调策略的整体框架如下:1) 使用预训练的Token化交通模型;2) 对于每个交通场景,从初始状态开始,模型进行 rollout,生成Top-K个预测轨迹;3) 计算每个预测轨迹与真实轨迹之间的距离(例如,使用L2距离);4) 选择距离最小的轨迹作为“最佳”轨迹;5) 使用“最佳”轨迹更新模型参数。该过程迭代进行,直到模型收敛。
关键创新:CAT-K的关键创新在于其闭环微调的方式,以及选择“最佳”轨迹的策略。与传统的开环训练相比,CAT-K能够更好地模拟真实交通环境中的智能体交互和环境动态。与强化学习或生成对抗模仿学习相比,CAT-K无需额外的奖励函数或判别器,仅需已有的轨迹数据,实现简单且高效。
关键设计:CAT-K的关键设计包括:1) Top-K的选择:K值的选择会影响模型的探索能力和学习效率。较大的K值可以增加模型的探索范围,但也可能导致学习不稳定。2) 距离度量:距离度量的选择会影响“最佳”轨迹的选取。常用的距离度量包括L2距离、Hausdorff距离等。3) 损失函数:可以使用交叉熵损失或均方误差损失来更新模型参数。4) 模型架构:CAT-K可以应用于各种Token化交通模型,例如Transformer模型。
🖼️ 关键图片

📊 实验亮点
实验结果表明,CAT-K微调策略能够显著提升Token化交通模型的性能。具体而言,一个仅有700万参数的Token化交通仿真策略,通过CAT-K微调,性能超越了同模型族中拥有1.02亿参数的模型,并在Waymo Sim Agent Challenge排行榜上名列前茅。这表明CAT-K是一种高效且有效的闭环微调策略。
🎯 应用场景
该研究成果可广泛应用于自动驾驶仿真测试、交通流量预测与控制、城市交通规划等领域。通过提升交通仿真的真实性和准确性,可以更有效地评估自动驾驶算法的性能,优化交通信号灯配时,并为城市交通规划提供数据支持。该方法有望加速自动驾驶技术的研发和部署,并改善城市交通状况。
📄 摘要(原文)
Traffic simulation aims to learn a policy for traffic agents that, when unrolled in closed-loop, faithfully recovers the joint distribution of trajectories observed in the real world. Inspired by large language models, tokenized multi-agent policies have recently become the state-of-the-art in traffic simulation. However, they are typically trained through open-loop behavior cloning, and thus suffer from covariate shift when executed in closed-loop during simulation. In this work, we present Closest Among Top-K (CAT-K) rollouts, a simple yet effective closed-loop fine-tuning strategy to mitigate covariate shift. CAT-K fine-tuning only requires existing trajectory data, without reinforcement learning or generative adversarial imitation. Concretely, CAT-K fine-tuning enables a small 7M-parameter tokenized traffic simulation policy to outperform a 102M-parameter model from the same model family, achieving the top spot on the Waymo Sim Agent Challenge leaderboard at the time of submission. The code is available at https://github.com/NVlabs/catk.