Revisiting Federated Fine-Tuning: A Single Communication Round is Enough for Foundation Models
作者: Ziyao Wang, Bowei Tian, Yexiao He, Zheyu Shen, Guoheng Sun, Yuhan Liu, Luyang Liu, Meng Liu, Ang Li
分类: cs.LG, cs.DC
发布日期: 2024-12-05 (更新: 2025-11-06)
💡 一句话要点
针对大模型联邦微调,提出单轮通信即可达到多轮通信性能的方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 基础模型 联邦微调 单轮聚合 通信效率 数据隐私 异步聚合
📋 核心要点
- 现有联邦微调方法因大模型参数量和多轮通信导致通信成本过高,限制了其应用。
- 论文提出单轮联邦微调方法,通过一次聚合即可达到多轮聚合的性能,大幅降低通信成本。
- 实验证明单轮联邦微调在文本生成和文图生成任务上与多轮方法性能相当,并能实现异步聚合。
📝 摘要(中文)
随着基础模型(FMs)的快速发展,对大规模跨领域数据集上进行微调的需求日益增长。联邦微调应运而生,它允许在多个设备的分布式数据集上微调FMs,同时确保数据隐私。然而,庞大的参数规模和联邦学习算法中的多轮通信导致极高的通信成本,对联邦微调的实用性提出了挑战。本文通过理论和实证分析发现,传统的多轮聚合算法对于大型FMs的联邦微调可能并非必要。实验表明,单轮聚合(即一次性联邦微调)产生的全局模型性能与多轮聚合相当。通过严格的数学和实证分析,证明了大型FMs由于其广泛的参数规模和在通用任务上的预训练,在一次性联邦微调中实现了比小型模型显著更低的训练损失。大量实验表明,一次性联邦微调显著降低了通信成本,并有可能实现异步聚合,增强隐私,并在文本生成和文本到图像生成任务中保持与多轮联邦微调的性能一致性。研究结果为彻底改变联邦微调的实践提供了见解,提高了效率,降低了成本,并扩大了FMs的可访问性。
🔬 方法详解
问题定义:论文旨在解决大型基础模型(FMs)在联邦学习场景下微调时,由于模型参数量巨大和传统联邦学习算法需要多轮通信而导致的通信成本过高的问题。现有方法的痛点在于,多轮通信不仅耗时,而且对网络带宽要求高,限制了联邦微调的实际应用。
核心思路:论文的核心思路是,对于大型预训练模型,由于其参数量巨大且已经在通用任务上进行了预训练,因此在联邦微调过程中,一次聚合后的模型已经能够很好地适应新的数据集,无需进行多轮迭代。这种一次性联邦微调(One-shot Federated Fine-tuning)可以显著降低通信成本,同时保持模型性能。
技术框架:整体框架采用标准的联邦学习流程,但关键在于只进行一轮全局模型聚合。具体流程如下: 1. 本地训练:每个客户端使用本地数据对预训练的基础模型进行微调。 2. 参数上传:客户端将微调后的模型参数上传到服务器。 3. 全局聚合:服务器对所有客户端上传的参数进行聚合,得到全局模型。 4. 模型分发:服务器将全局模型分发给所有客户端(可选,取决于具体应用场景)。
关键创新:最重要的技术创新点在于发现并验证了大型预训练模型在联邦微调中单轮聚合的有效性。与传统联邦学习算法需要多轮迭代不同,该方法仅需一轮通信即可达到相当甚至更好的性能。这极大地降低了通信成本,并为异步联邦学习提供了可能。
关键设计:论文没有特别强调关键的参数设置或网络结构,而是侧重于证明单轮聚合的有效性。关键在于使用大型预训练模型作为基础,并采用标准的联邦平均算法进行参数聚合。损失函数和优化器等超参数的选择可以根据具体任务进行调整。
🖼️ 关键图片
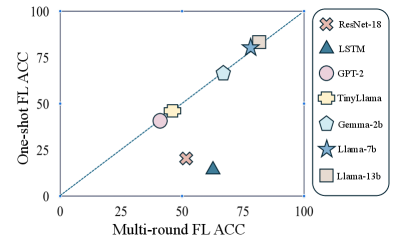
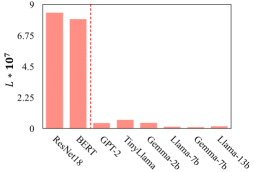
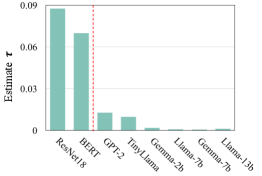
📊 实验亮点
实验结果表明,在文本生成和文本到图像生成任务上,单轮联邦微调的性能与多轮联邦微调相当,甚至在某些情况下略有提升。例如,在特定数据集上,单轮微调的性能仅比多轮微调低不到1%,但通信成本却大幅降低。这验证了单轮联邦微调在降低通信成本的同时保持模型性能的有效性。
🎯 应用场景
该研究成果可广泛应用于需要保护用户数据隐私的大模型微调场景,例如医疗健康、金融服务等领域。通过降低通信成本,使得在资源受限的环境下进行联邦微调成为可能,从而加速大模型在各行业的应用和普及。未来,该方法有望与差分隐私等技术结合,进一步提升数据安全性。
📄 摘要(原文)
The recent advancement of foundation models (FMs) has increased the demand for fine-tuning these models on large-scale cross-domain datasets. To address this, federated fine-tuning has emerged, allowing FMs to be fine-tuned on distributed datasets across multiple devices while ensuring data privacy. However, the substantial parameter size and the multi-round communication in federated learning algorithms result in prohibitively high communication costs, challenging the practicality of federated fine-tuning. In this paper, we identify and analyze, both theoretically and empirically, that the traditional multi-round aggregation algorithms may not be necessary for federated fine-tuning large FMs. Our experiments reveal that a single round of aggregation (i.e., one-shot federated fine-tuning) yields a global model performance comparable to that achieved through multiple rounds of aggregation. Through rigorous mathematical and empirical analyses, we demonstrate that large FMs, due to their extensive parameter sizes and pre-training on general tasks, achieve significantly lower training loss in one-shot federated fine-tuning compared to smaller models. Our extensive experiments show that one-shot federated fine-tuning significantly reduces communication costs. It also has the potential to enable asynchronous aggregation, enhances privacy, and maintains performance consistency with multi-round federated fine-tuning on both text generation and text-to-image generation tasks. Our findings provide insights to revolutionize federated fine-tuning in practice, enhancing efficiency, reducing costs, and expanding accessibility for FMs.