Action Mapping for Reinforcement Learning in Continuous Environments with Constraints
作者: Mirco Theile, Lukas Dirnberger, Raphael Trumpp, Marco Caccamo, Alberto L. Sangiovanni-Vincentelli
分类: cs.LG, cs.AI, eess.SY
发布日期: 2024-12-05
💡 一句话要点
提出基于动作映射的强化学习方法,提升约束连续动作空间环境下的训练效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 深度强化学习 约束优化 连续动作空间 动作映射 可行性模型
📋 核心要点
- 在约束环境中应用DRL面临样本效率低和收敛慢的挑战,现有方法难以有效利用可行性模型。
- 论文提出动作映射方法,解耦可行动作学习和策略优化,使智能体专注于可行动作集内的选择。
- 实验表明,动作映射在约束连续动作空间环境中显著提升训练性能,即使在可行性模型不完善时也有效。
📝 摘要(中文)
深度强化学习(DRL)在各个领域取得了成功,但将其应用于具有约束的环境仍然具有挑战性,因为其样本效率低且收敛速度慢。最近的研究探索了结合模型知识来缓解这些问题,特别是通过使用评估提议动作可行性的模型。然而,在具有连续动作空间的环境中,将可行性模型有效地集成到DRL流程中并非易事。我们提出了一种新的DRL训练策略,该策略利用动作映射,利用可行性模型来简化学习过程。通过将可行动作的学习与策略优化分离,动作映射允许DRL智能体专注于从缩减的可行动作集中选择最佳动作。通过实验证明,动作映射显著提高了约束连续动作空间环境中的训练性能,尤其是在不完善的可行性模型下。
🔬 方法详解
问题定义:论文旨在解决在具有约束的连续动作空间环境中,深度强化学习训练效率低下的问题。现有方法难以有效利用可行性模型,导致样本效率不高,收敛速度慢。尤其是在可行性模型不完善的情况下,性能会进一步下降。
核心思路:论文的核心思路是将可行动作的学习与策略优化解耦。通过引入动作映射,首先利用可行性模型筛选出可行动作集,然后让DRL智能体专注于从这个缩减的集合中选择最优动作。这样可以减少探索空间,提高样本效率,加速收敛。
技术框架:整体框架包含以下几个主要部分:1) 环境模型:描述环境的状态转移和奖励函数。2) 可行性模型:用于判断给定动作在当前状态下是否可行。3) 动作映射模块:利用可行性模型,将原始动作空间映射到可行动作空间。4) DRL智能体:负责从可行动作空间中选择最优动作,并根据环境反馈更新策略。训练过程分为两个阶段:首先训练或预训练可行性模型(如果可用),然后利用动作映射和DRL智能体进行策略优化。
关键创新:最重要的创新点在于动作映射机制,它将可行性模型与DRL智能体有效结合,实现了可行动作学习与策略优化的解耦。与直接在原始动作空间中进行探索相比,动作映射显著缩小了搜索空间,提高了学习效率。此外,该方法对不完善的可行性模型具有一定的鲁棒性。
关键设计:论文中关键的设计包括:1) 如何构建和训练可行性模型(可以使用监督学习或强化学习)。2) 如何将可行性模型集成到动作映射模块中,例如,可以使用阈值来判断动作是否可行。3) 如何设计DRL智能体的网络结构和损失函数,使其能够有效地从可行动作空间中学习最优策略。具体的参数设置和网络结构可能需要根据具体的环境进行调整。
🖼️ 关键图片


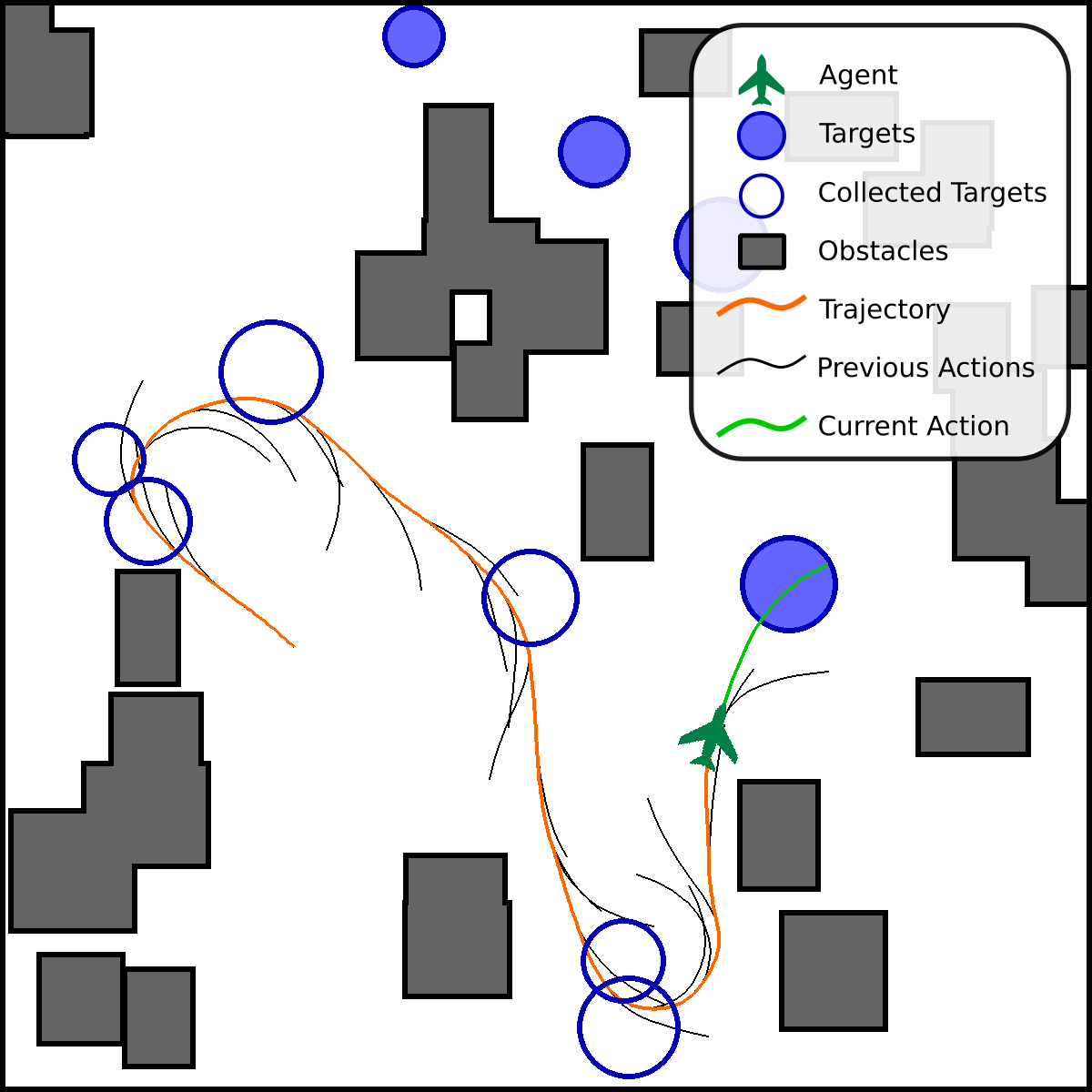
📊 实验亮点
实验结果表明,在约束连续动作空间环境中,所提出的动作映射方法显著提高了DRL的训练性能。与传统DRL方法相比,该方法能够更快地收敛到最优策略,并获得更高的累积奖励。即使在可行性模型不完善的情况下,动作映射仍然能够有效地提升训练效果。
🎯 应用场景
该研究成果可应用于机器人控制、自动驾驶、资源调度等领域,这些领域通常存在复杂的约束条件。通过提高DRL在约束环境下的训练效率,可以降低开发成本,加速智能系统的部署。未来,该方法有望扩展到更复杂的约束类型和动态环境。
📄 摘要(原文)
Deep reinforcement learning (DRL) has had success across various domains, but applying it to environments with constraints remains challenging due to poor sample efficiency and slow convergence. Recent literature explored incorporating model knowledge to mitigate these problems, particularly through the use of models that assess the feasibility of proposed actions. However, integrating feasibility models efficiently into DRL pipelines in environments with continuous action spaces is non-trivial. We propose a novel DRL training strategy utilizing action mapping that leverages feasibility models to streamline the learning process. By decoupling the learning of feasible actions from policy optimization, action mapping allows DRL agents to focus on selecting the optimal action from a reduced feasible action set. We demonstrate through experiments that action mapping significantly improves training performance in constrained environments with continuous action spaces, especially with imperfect feasibility models.