PathletRL++: Optimizing Trajectory Pathlet Extraction and Dictionary Formation via Reinforcement Learning
作者: Gian Alix, Arian Haghparast, Manos Papagelis
分类: cs.LG, cs.AI
发布日期: 2024-12-04
💡 一句话要点
PathletRL++:通过强化学习优化轨迹Pathlet提取和字典构建,提升轨迹数据表示效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 轨迹数据 Pathlet字典 强化学习 深度Q网络 轨迹表示 路径规划 移动性分析
📋 核心要点
- 现有轨迹数据Pathlet字典构建方法内存占用高,且存在大量重叠冗余Pathlet,效率低下。
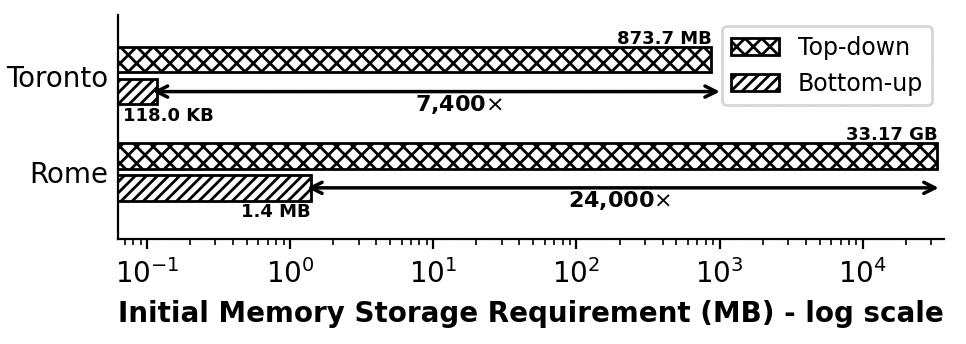
- 提出自底向上的Pathlet字典构建策略,通过强化学习迭代合并Pathlet,优化轨迹损失和可表示性。
- PathletRL++在PathletRL基础上,通过更丰富的状态表示和改进的奖励函数,进一步提升字典构建效率和轨迹表示能力。
📝 摘要(中文)
随着追踪技术的进步,大规模轨迹数据迅速增长。构建紧凑的Pathlet集合(即轨迹Pathlet字典)对于支持移动性相关应用至关重要。现有方法通常采用自顶向下的策略,生成大量候选Pathlet并选择子集,导致高内存占用和重叠Pathlet造成的冗余存储。为了克服这些限制,我们提出了一种自底向上的策略,通过增量合并基本Pathlet来构建字典,与基线方法相比,内存需求最多可减少24000倍。该方法从单位长度的Pathlet开始,迭代地合并它们,同时优化效用,效用由新引入的轨迹损失和可表示性指标定义。我们开发了一个深度强化学习框架PathletRL,它利用深度Q网络(DQN)来近似效用函数,从而产生一个紧凑而高效的Pathlet字典。在合成和真实数据集上的实验表明,我们的方法优于最先进的技术,构建的字典大小最多可减少65.8%。此外,我们的结果表明,只需要一半的字典Pathlet就可以重建85%的原始轨迹数据。在PathletRL的基础上,我们引入了PathletRL++,它通过结合更丰富的状态表示和改进的奖励函数来优化Pathlet合并过程中的决策,从而扩展了原始模型。这些增强功能使智能体能够更细致地理解环境,从而产生更高质量的Pathlet字典。PathletRL++实现了更大的字典大小缩减,超越了PathletRL的性能,同时保持了较高的轨迹可表示性。
🔬 方法详解
问题定义:现有轨迹Pathlet字典构建方法,如自顶向下方法,会生成大量候选Pathlet,导致高内存占用和冗余存储。这些方法没有充分考虑Pathlet之间的关系,容易产生重叠的Pathlet,降低了字典的效率。因此,需要一种更高效的方法来构建紧凑且具有代表性的Pathlet字典。
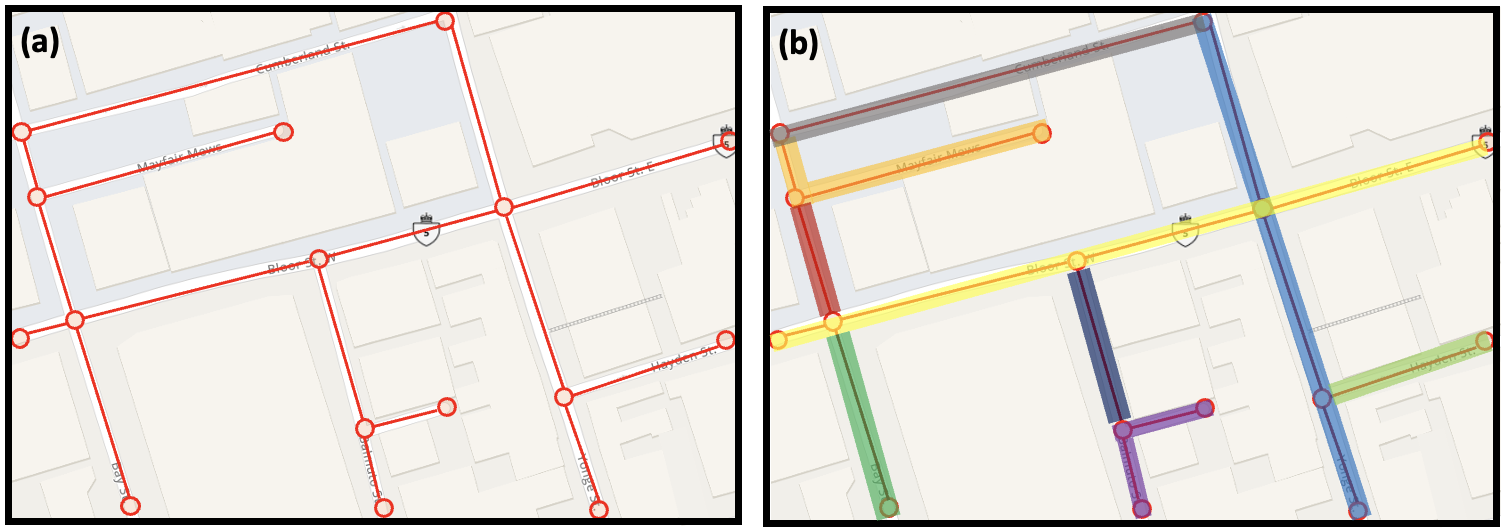
核心思路:论文的核心思路是采用自底向上的策略,从基本的单位长度Pathlet开始,通过迭代合并的方式逐步构建Pathlet字典。在每次合并过程中,利用强化学习来优化合并决策,选择能够最大程度提高字典效用的Pathlet进行合并。这种方法能够避免生成大量候选Pathlet,从而降低内存占用,并减少Pathlet之间的冗余。
技术框架:PathletRL++的整体框架包括以下几个主要阶段:1) 初始化:从单位长度的Pathlet开始构建初始Pathlet集合。2) 状态表示:使用轨迹损失和可表示性等指标来表示当前Pathlet集合的状态。3) 动作选择:利用深度Q网络(DQN)来预测每个可能的合并动作的Q值,并选择具有最高Q值的动作。4) 合并Pathlet:执行选定的合并动作,更新Pathlet集合。5) 奖励计算:根据合并后的Pathlet集合的效用,计算奖励值。6) 网络更新:使用奖励值来更新DQN网络。重复步骤2-6,直到满足停止条件。
关键创新:PathletRL++的关键创新在于:1) 自底向上的Pathlet字典构建策略,避免了生成大量候选Pathlet。2) 利用强化学习来优化Pathlet合并决策,选择能够最大程度提高字典效用的Pathlet进行合并。3) 引入了更丰富的状态表示和改进的奖励函数,使智能体能够更细致地理解环境,从而产生更高质量的Pathlet字典。PathletRL++与PathletRL相比,主要改进在于状态表示和奖励函数的设计。
关键设计:PathletRL++的关键设计包括:1) 状态表示:使用轨迹损失和可表示性等指标来表示当前Pathlet集合的状态,这些指标能够反映Pathlet集合的质量和效率。2) 奖励函数:设计奖励函数来鼓励智能体选择能够提高字典效用的合并动作。奖励函数通常包括轨迹损失的减少和可表示性的提高。3) DQN网络结构:使用深度Q网络(DQN)来近似Q函数,DQN网络通常包括多个卷积层和全连接层,用于提取状态特征并预测Q值。4) 合并策略:设计合并策略来确定哪些Pathlet可以合并,例如,可以限制合并的Pathlet之间的距离或方向。
🖼️ 关键图片

📊 实验亮点
实验结果表明,PathletRL++在合成和真实数据集上均优于现有方法,能够显著减小Pathlet字典的大小,最多可减少65.8%。同时,PathletRL++能够保持较高的轨迹可表示性,仅需一半的字典Pathlet即可重建85%的原始轨迹数据。PathletRL++在字典大小缩减方面超越了PathletRL的性能,证明了其更丰富的状态表示和改进的奖励函数的有效性。
🎯 应用场景
该研究成果可广泛应用于轨迹数据分析、交通流量预测、路径规划、位置服务等领域。通过构建紧凑且具有代表性的Pathlet字典,可以有效降低存储和计算成本,提高相关应用的效率和准确性。未来,该方法有望应用于自动驾驶、智能交通等新兴领域,为智慧城市建设提供有力支持。
📄 摘要(原文)
Advances in tracking technologies have spurred the rapid growth of large-scale trajectory data. Building a compact collection of pathlets, referred to as a trajectory pathlet dictionary, is essential for supporting mobility-related applications. Existing methods typically adopt a top-down approach, generating numerous candidate pathlets and selecting a subset, leading to high memory usage and redundant storage from overlapping pathlets. To overcome these limitations, we propose a bottom-up strategy that incrementally merges basic pathlets to build the dictionary, reducing memory requirements by up to 24,000 times compared to baseline methods. The approach begins with unit-length pathlets and iteratively merges them while optimizing utility, which is defined using newly introduced metrics of trajectory loss and representability. We develop a deep reinforcement learning framework, PathletRL, which utilizes Deep Q-Networks (DQN) to approximate the utility function, resulting in a compact and efficient pathlet dictionary. Experiments on both synthetic and real-world datasets demonstrate that our method outperforms state-of-the-art techniques, reducing the size of the constructed dictionary by up to 65.8%. Additionally, our results show that only half of the dictionary pathlets are needed to reconstruct 85% of the original trajectory data. Building on PathletRL, we introduce PathletRL++, which extends the original model by incorporating a richer state representation and an improved reward function to optimize decision-making during pathlet merging. These enhancements enable the agent to gain a more nuanced understanding of the environment, leading to higher-quality pathlet dictionaries. PathletRL++ achieves even greater dictionary size reduction, surpassing the performance of PathletRL, while maintaining high trajectory representability.