Cluster Specific Representation Learning
作者: Mahalakshmi Sabanayagam, Omar Al-Dabooni, Pascal Esser
分类: cs.LG
发布日期: 2024-12-04
💡 一句话要点
提出聚类特定表示学习框架,提升下游任务的泛化性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 表示学习 聚类 自编码器 对比学习 无监督学习
📋 核心要点
- 现有表示学习方法依赖于特定下游任务的性能评估,缺乏泛化能力,难以适应不同任务需求。
- 论文提出聚类特定表示学习,核心思想是使表示能够反映数据中固有的聚类结构,从而提升表示的通用性。
- 实验表明,该方法在自编码器等多种框架下有效,能提取数据中的聚类结构,并在相关应用中提升性能。
📝 摘要(中文)
表示学习旨在从数据中提取有意义的低维嵌入,即表示。尽管应用广泛,但对于“好的”表示并没有明确的定义。通常,表示的质量是基于其在聚类、去噪等下游任务中的性能来评估的。然而,这种特定于任务的方法存在局限性,即在一个任务中表现良好的表示可能不一定在另一个任务中有效。这突出了对更具普适性的公式的需求,这也是我们工作的重点。我们提出了一种与下游任务无关的公式:当数据中存在固有的聚类时,表示应该特定于每个聚类。基于这个想法,我们开发了一种元算法,该算法联合学习聚类特定的表示和聚类分配。由于我们的方法易于与任何表示学习框架集成,因此我们展示了它在各种设置中的有效性,包括自编码器、变分自编码器、对比学习模型和受限玻尔兹曼机。我们将我们的聚类特定嵌入与标准嵌入以及去噪和聚类等下游任务进行定性比较。虽然我们的方法与标准模型相比略微增加了运行时间和参数,但实验清楚地表明,它提取了数据中固有的聚类结构,从而提高了相关应用中的性能。
🔬 方法详解
问题定义:现有表示学习方法通常针对特定下游任务进行优化,导致学习到的表示在不同任务之间的泛化能力较差。例如,一个为图像分类任务设计的表示可能不适用于图像聚类任务。因此,需要一种与下游任务无关的表示学习方法,能够提取数据中固有的结构信息,从而提高表示的通用性。
核心思路:论文的核心思路是,如果数据中存在固有的聚类结构,那么学习到的表示应该能够反映这些聚类结构。具体来说,对于每个聚类,学习一个特定的表示,使得属于同一聚类的样本在表示空间中更加接近,而属于不同聚类的样本在表示空间中更加远离。这样,学习到的表示就能够更好地反映数据的内在结构,从而提高在不同下游任务中的性能。
技术框架:该方法是一个元算法,可以与任何表示学习框架集成。整体流程如下:1) 使用现有的表示学习框架(如自编码器、对比学习等)学习数据的初始表示;2) 使用聚类算法(如k-means)对初始表示进行聚类,得到聚类分配;3) 根据聚类分配,为每个聚类学习一个特定的表示;4) 联合优化聚类分配和聚类特定表示。
关键创新:该方法最重要的技术创新点在于提出了聚类特定表示学习的思想,即将表示学习与聚类相结合,使得学习到的表示能够反映数据的内在聚类结构。与现有方法的本质区别在于,现有方法通常只关注如何提高在特定下游任务中的性能,而忽略了数据本身的结构信息。
关键设计:该方法的关键设计包括:1) 如何选择合适的聚类算法;2) 如何定义聚类特定表示;3) 如何联合优化聚类分配和聚类特定表示。具体来说,可以使用k-means算法进行聚类,使用线性变换或非线性变换来定义聚类特定表示,使用交叉熵损失函数或对比损失函数来联合优化聚类分配和聚类特定表示。
🖼️ 关键图片

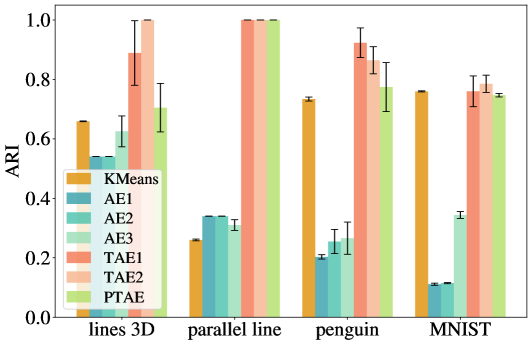

📊 实验亮点
实验结果表明,该方法在多种表示学习框架下均有效,能够提取数据中固有的聚类结构,并在去噪和聚类等下游任务中取得更好的性能。虽然该方法略微增加了运行时间和参数,但性能的提升证明了其有效性。具体性能数据未知,但定性结果显示聚类效果明显优于标准方法。
🎯 应用场景
该研究成果可应用于多种领域,例如图像分类、图像聚类、异常检测、推荐系统等。通过学习聚类特定的表示,可以提高模型在这些任务中的性能和泛化能力。此外,该方法还可以用于发现数据中隐藏的聚类结构,从而为数据分析和挖掘提供新的思路。
📄 摘要(原文)
Representation learning aims to extract meaningful lower-dimensional embeddings from data, known as representations. Despite its widespread application, there is no established definition of a ``good'' representation. Typically, the representation quality is evaluated based on its performance in downstream tasks such as clustering, de-noising, etc. However, this task-specific approach has a limitation where a representation that performs well for one task may not necessarily be effective for another. This highlights the need for a more agnostic formulation, which is the focus of our work. We propose a downstream-agnostic formulation: when inherent clusters exist in the data, the representations should be specific to each cluster. Under this idea, we develop a meta-algorithm that jointly learns cluster-specific representations and cluster assignments. As our approach is easy to integrate with any representation learning framework, we demonstrate its effectiveness in various setups, including Autoencoders, Variational Autoencoders, Contrastive learning models, and Restricted Boltzmann Machines. We qualitatively compare our cluster-specific embeddings to standard embeddings and downstream tasks such as de-noising and clustering. While our method slightly increases runtime and parameters compared to the standard model, the experiments clearly show that it extracts the inherent cluster structures in the data, resulting in improved performance in relevant applications.