Surveying the Effects of Quality, Diversity, and Complexity in Synthetic Data From Large Language Models
作者: Alex Havrilla, Andrew Dai, Laura O'Mahony, Koen Oostermeijer, Vera Zisler, Alon Albalak, Fabrizio Milo, Sharath Chandra Raparthy, Kanishk Gandhi, Baber Abbasi, Duy Phung, Maia Iyer, Dakota Mahan, Chase Blagden, Srishti Gureja, Mohammed Hamdy, Wen-Ding Li, Giovanni Paolini, Pawan Sasanka Ammanamanchi, Elliot Meyerson
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-12-04 (更新: 2024-12-09)
💡 一句话要点
通过评估合成数据的质量、多样性和复杂性,深入分析大语言模型生成合成数据的影响。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 合成数据生成 大型语言模型 数据质量 数据多样性 数据复杂性 模型泛化 质量-多样性权衡
📋 核心要点
- 现有合成数据生成算法缺乏直接比较,难以理解改进来源和瓶颈。
- 通过评估合成数据的质量、多样性和复杂性(QDC)来分析算法。
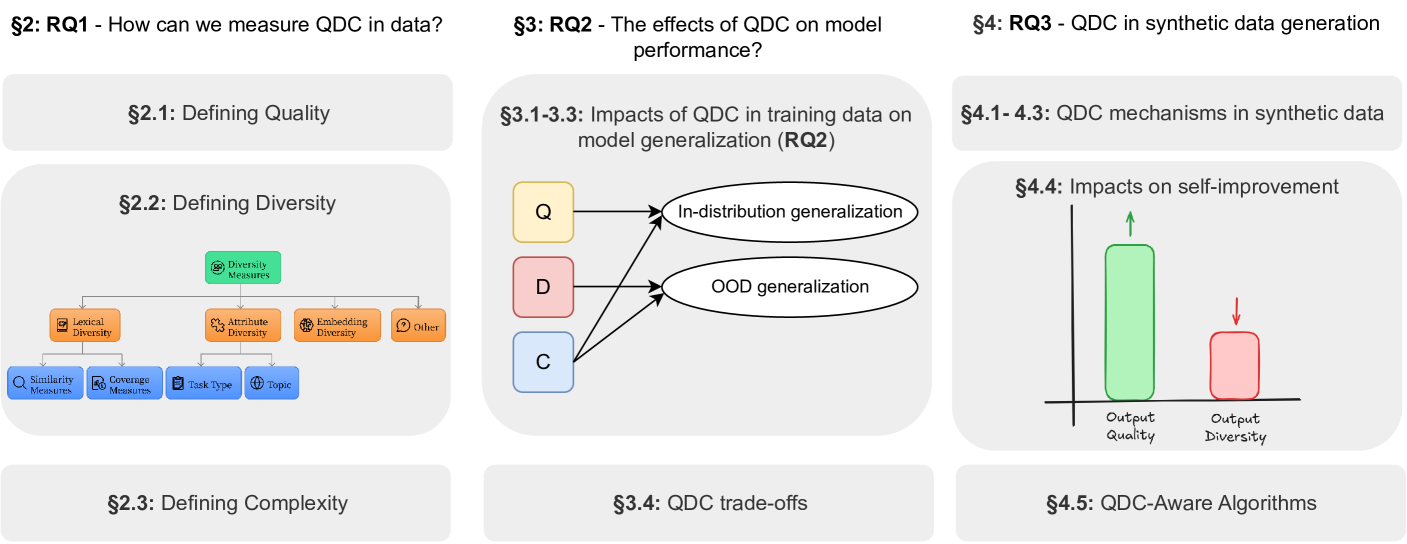
- 研究发现质量对分布内泛化至关重要,多样性对分布外泛化至关重要,复杂性对两者都有益。
📝 摘要(中文)
利用大型语言模型生成合成数据是一种很有前景的范例,几乎可以扩展到无限范围的任务中,以增强自然数据。鉴于这种多样性,对合成数据生成算法的直接比较很少,因此很难理解改进来自哪里以及存在哪些瓶颈。我们建议通过每个算法生成的合成数据在数据质量、多样性和复杂性方面的构成来评估算法。我们选择这三个特征是因为它们在开放过程中具有重要意义,并且每个特征都对下游模型的能力产生影响。我们发现质量对于分布内模型泛化至关重要,多样性对于分布外泛化至关重要,而复杂性对两者都有益。此外,我们强调了训练数据中质量-多样性权衡的存在以及对模型性能的下游影响。然后,我们检查了合成数据管道中各种组件对每个数据特征的影响。这种检查使我们能够通过它们使用的组件以及对数据QDC组成产生的相应影响来对合成数据生成算法进行分类和比较。此分析扩展到讨论平衡合成数据中的QDC对于高效强化学习和自我改进算法的重要性。与训练数据中的QD权衡类似,模型输出质量和输出多样性之间通常存在权衡,这会影响合成数据的组成。我们观察到,许多模型目前仅针对输出质量进行评估和优化,从而限制了输出多样性和自我改进的潜力。我们认为,平衡这些权衡对于未来自我改进算法的开发至关重要,并重点介绍了许多在这方面取得进展的工作。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)生成合成数据时,如何系统性地评估和比较不同合成数据生成算法的问题。现有方法缺乏对合成数据质量、多样性和复杂性(QDC)的综合考量,难以指导算法的改进和选择。
核心思路:论文的核心思路是通过分析合成数据的QDC构成来评估不同的生成算法。作者认为,QDC是影响下游模型性能的关键因素,并且在训练数据中存在质量-多样性权衡。通过理解不同算法在QDC方面的表现,可以更好地指导合成数据的生成和利用。
技术框架:论文构建了一个评估合成数据生成算法的框架,该框架主要包含以下几个阶段: 1. 合成数据生成:使用不同的LLM和生成策略生成合成数据。 2. QDC评估:对生成的合成数据进行质量、多样性和复杂性评估,使用多种指标进行量化。 3. 下游任务评估:将合成数据用于训练下游模型,评估模型在不同任务上的性能。 4. 算法比较与分析:根据QDC评估和下游任务性能,对不同的生成算法进行比较和分析,找出优势和不足。
关键创新:论文的关键创新在于提出了一个基于QDC的合成数据评估框架,并将其应用于分析不同的LLM生成算法。该框架提供了一种系统性的方法来理解合成数据的特性及其对下游模型的影响,为合成数据的生成和利用提供了指导。
关键设计:论文中涉及的关键设计包括: * QDC评估指标的选择:选择合适的指标来量化合成数据的质量、多样性和复杂性,例如使用困惑度评估质量,使用覆盖率评估多样性,使用树深度评估复杂性。 * 下游任务的选择:选择具有代表性的下游任务来评估合成数据的有效性,例如文本分类、问答等。 * 实验设置:设计合理的实验设置,控制变量,确保评估结果的可靠性。
🖼️ 关键图片


📊 实验亮点
论文通过实验验证了QDC对下游模型性能的影响。研究发现,高质量的合成数据对于分布内泛化至关重要,多样化的数据对于分布外泛化至关重要,而复杂性对两者都有益。此外,论文还强调了训练数据中质量-多样性权衡的存在,并分析了不同生成算法在QDC方面的表现。
🎯 应用场景
该研究成果可应用于各种需要合成数据增强的领域,例如自然语言处理、计算机视觉和机器人学习。通过优化合成数据的QDC,可以提高下游模型的性能,降低数据标注成本,并促进模型的泛化能力。该研究对强化学习和自学习算法的开发具有重要意义。
📄 摘要(原文)
Synthetic data generation with Large Language Models is a promising paradigm for augmenting natural data over a nearly infinite range of tasks. Given this variety, direct comparisons among synthetic data generation algorithms are scarce, making it difficult to understand where improvement comes from and what bottlenecks exist. We propose to evaluate algorithms via the makeup of synthetic data generated by each algorithm in terms of data quality, diversity, and complexity. We choose these three characteristics for their significance in open-ended processes and the impact each has on the capabilities of downstream models. We find quality to be essential for in-distribution model generalization, diversity to be essential for out-of-distribution generalization, and complexity to be beneficial for both. Further, we emphasize the existence of Quality-Diversity trade-offs in training data and the downstream effects on model performance. We then examine the effect of various components in the synthetic data pipeline on each data characteristic. This examination allows us to taxonomize and compare synthetic data generation algorithms through the components they utilize and the resulting effects on data QDC composition. This analysis extends into a discussion on the importance of balancing QDC in synthetic data for efficient reinforcement learning and self-improvement algorithms. Analogous to the QD trade-offs in training data, often there exist trade-offs between model output quality and output diversity which impact the composition of synthetic data. We observe that many models are currently evaluated and optimized only for output quality, thereby limiting output diversity and the potential for self-improvement. We argue that balancing these trade-offs is essential to the development of future self-improvement algorithms and highlight a number of works making progress in this direction.