DP-2Stage: Adapting Language Models as Differentially Private Tabular Data Generators
作者: Tejumade Afonja, Hui-Po Wang, Raouf Kerkouche, Mario Fritz
分类: cs.LG, cs.CL, cs.CR
发布日期: 2024-12-03 (更新: 2025-04-29)
期刊: Transactions on Machine Learning Research (03/2025)
🔗 代码/项目: GITHUB
💡 一句话要点
提出DP-2Stage:一种用于差分隐私表格数据生成的两阶段语言模型微调框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 差分隐私 表格数据生成 大型语言模型 两阶段微调 数据隐私保护
📋 核心要点
- 现有方法难以在差分隐私约束下利用大型语言模型生成高质量表格数据,因为隐私预算分配不合理,导致模型难以学习表格结构。
- DP-2Stage框架通过两阶段微调解决此问题:首先在伪数据集上进行非私有微调,然后使用差分隐私在私有数据集上微调。
- 实验结果表明,DP-2Stage在各种设置和指标下均优于直接进行差分隐私微调的LLM,提升了表格数据生成的性能。
📝 摘要(中文)
在差分隐私(DP)保护下生成表格数据可以确保理论上的隐私保证,但由于需要在噪声监督信号下捕获复杂的结构,因此给训练机器学习模型带来了挑战。最近,预训练的大型语言模型(LLM),即使是GPT-2这种规模的,也展示了在合成表格数据方面的巨大潜力。然而,它们在DP约束下的应用在很大程度上仍未被探索。在这项工作中,我们通过将DP技术应用于合成表格数据的生成来解决这个问题。我们的研究结果表明,当使用DP进行微调时,LLM在生成连贯文本方面面临困难,因为隐私预算被低效地分配给非隐私元素,如表格结构。为了克服这个问题,我们提出了DP-2Stage,一个用于差分隐私表格数据生成的两阶段微调框架。第一阶段涉及在伪数据集上进行非私有微调,第二阶段涉及在私有数据集上进行DP微调。我们的实验结果表明,与在DP环境中直接微调的LLM相比,这种方法在各种设置和指标下都提高了性能。我们已在https://github.com/tejuafonja/DP-2Stage上发布了我们的代码和设置。
🔬 方法详解
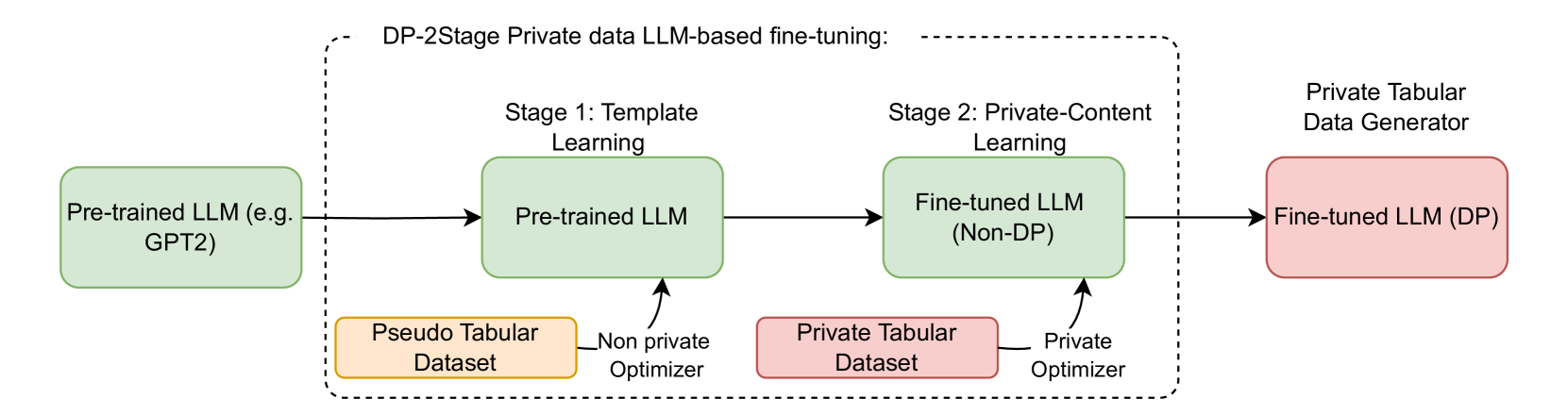
问题定义:论文旨在解决在差分隐私(DP)约束下,如何有效地利用大型语言模型(LLM)生成高质量的合成表格数据的问题。现有的直接在私有数据上进行DP微调的方法,存在隐私预算分配不合理的问题,导致模型难以学习表格数据的结构,生成的数据质量较差。
核心思路:论文的核心思路是将微调过程分为两个阶段。第一阶段,在非私有的伪数据集上进行微调,使LLM能够学习表格数据的基本结构和格式。第二阶段,在私有数据集上进行DP微调,以保证数据的隐私性。通过这种两阶段的方式,可以更有效地利用隐私预算,提高生成数据的质量。
技术框架:DP-2Stage框架包含两个主要阶段: 1. 非私有微调阶段:使用一个与私有数据集结构相似的伪数据集,对LLM进行非私有微调。这一阶段的目标是使LLM学习表格数据的基本结构和格式,例如列名、数据类型等。 2. 差分隐私微调阶段:在私有数据集上,使用差分隐私技术对LLM进行微调。这一阶段的目标是在保证数据隐私的前提下,使LLM学习私有数据集中的特定模式和分布。
关键创新:该方法最重要的创新点在于提出了两阶段微调的框架,将结构学习和隐私保护解耦。通过首先在非私有数据上学习结构,再在私有数据上进行DP微调,可以更有效地利用隐私预算,提高生成数据的质量。与直接进行DP微调的方法相比,DP-2Stage能够生成更符合原始数据分布的合成数据。
关键设计: * 伪数据集生成:伪数据集需要与私有数据集具有相似的结构,例如相同的列名和数据类型。可以使用启发式方法或生成模型来创建伪数据集。 * 差分隐私机制:在DP微调阶段,可以使用各种差分隐私机制,例如Gaussian Mechanism或Laplace Mechanism,来保护数据的隐私性。 * 隐私预算分配:需要合理地分配两个阶段的隐私预算。通常,可以在第一阶段使用较小的隐私预算,而在第二阶段使用较大的隐私预算。
🖼️ 关键图片

📊 实验亮点
论文通过实验验证了DP-2Stage框架的有效性。实验结果表明,与直接进行差分隐私微调的LLM相比,DP-2Stage在各种设置和指标下都提高了性能。具体来说,DP-2Stage能够生成更符合原始数据分布的合成数据,并且在下游任务中表现更好。实验结果表明,该方法在保证数据隐私的同时,能够有效地利用LLM生成高质量的合成表格数据。
🎯 应用场景
该研究成果可应用于医疗、金融等对数据隐私要求高的领域。通过生成具有差分隐私保护的合成表格数据,可以安全地共享和利用这些数据进行模型训练、数据分析等任务,从而促进相关领域的研究和应用,同时保护用户隐私。
📄 摘要(原文)
Generating tabular data under differential privacy (DP) protection ensures theoretical privacy guarantees but poses challenges for training machine learning models, primarily due to the need to capture complex structures under noisy supervision signals. Recently, pre-trained Large Language Models (LLMs) -- even those at the scale of GPT-2 -- have demonstrated great potential in synthesizing tabular data. However, their applications under DP constraints remain largely unexplored. In this work, we address this gap by applying DP techniques to the generation of synthetic tabular data. Our findings shows that LLMs face difficulties in generating coherent text when fine-tuned with DP, as privacy budgets are inefficiently allocated to non-private elements like table structures. To overcome this, we propose DP-2Stage, a two-stage fine-tuning framework for differentially private tabular data generation. The first stage involves non-private fine-tuning on a pseudo dataset, followed by DP fine-tuning on a private dataset. Our empirical results show that this approach improves performance across various settings and metrics compared to directly fine-tuned LLMs in DP contexts. We release our code and setup at https://github.com/tejuafonja/DP-2Stage.