ROSE: A Reward-Oriented Data Selection Framework for LLM Task-Specific Instruction Tuning
作者: Yang Wu, Huayi Zhang, Yizheng Jiao, Lin Ma, Xiaozhong Liu, Jinhong Yu, Dongyu Zhang, Dezhi Yu, Wei Xu
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-12-01 (更新: 2025-08-29)
备注: EMNLP 2025 Findings
💡 一句话要点
提出ROSE,一种面向奖励的LLM指令调优数据选择框架,提升任务特定性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 指令调优 数据选择 大型语言模型 奖励学习 偏好学习
📋 核心要点
- 现有指令调优数据选择方法依赖损失函数,但损失与任务性能并非总是正相关,导致效果不佳。
- ROSE利用成对偏好损失作为奖励信号,通过影响函数近似数据点对验证集的影响,选择更优数据。
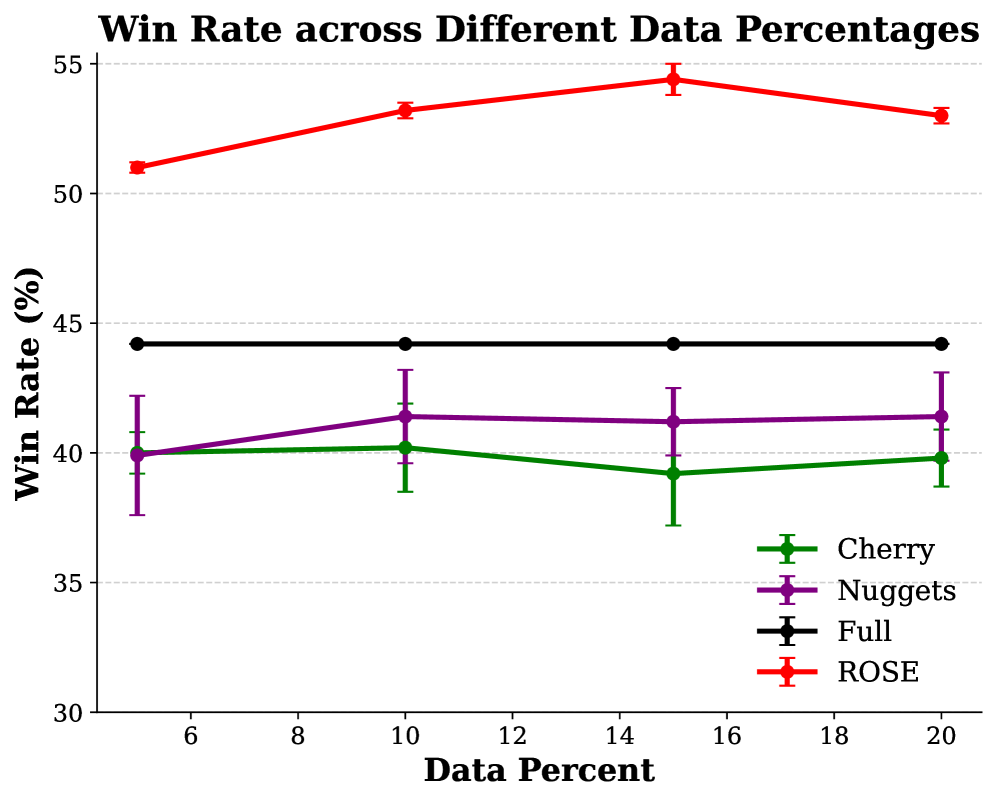
- 实验表明,ROSE仅用5%的数据即可达到全量微调的竞争力,优于其他数据选择方法,且泛化性强。
📝 摘要(中文)
本文关注于LLM任务特定指令调优的数据选择问题。现有方法主要依赖于精心设计的相似性度量来选择与测试数据分布对齐的训练数据,目标是最小化指令调优在测试数据上的损失,从而提高目标任务的性能。然而,指令调优损失(即下一个token预测的交叉熵损失)与实际任务性能之间通常不呈现单调关系。这种错位削弱了当前数据选择方法在任务特定指令调优中的有效性。为了解决这个问题,我们提出了一种新颖的面向奖励的指令数据选择方法ROSE,它利用成对偏好损失作为奖励信号来优化任务特定指令调优的数据选择。具体来说,ROSE采用一种影响公式来近似训练数据点相对于少量样本偏好验证集的影响,从而选择最相关的训练数据点。实验结果表明,仅使用ROSE选择的5%的训练数据,我们的方法就可以达到与使用完整训练数据集进行微调相比具有竞争力的结果,并且超过了其他最先进的任务特定指令调优数据选择方法。我们的定性分析进一步证实了我们的方法在多个基准数据集和不同模型架构上的鲁棒泛化能力。
🔬 方法详解
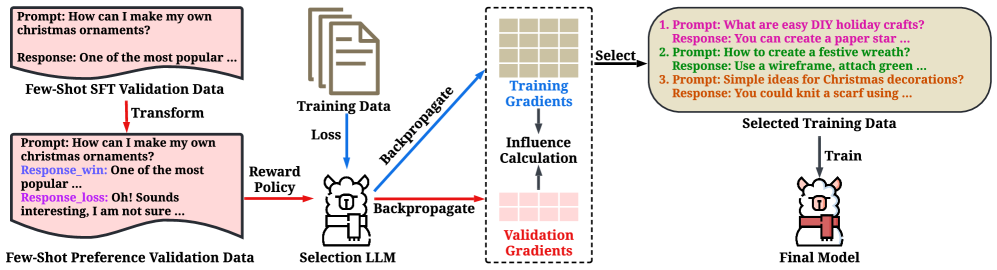
问题定义:论文旨在解决大型语言模型(LLM)在进行任务特定指令调优时,如何有效选择训练数据的问题。现有方法主要依赖于最小化交叉熵损失,但这种损失与实际任务性能之间存在错位,导致选择的训练数据并非最优,影响最终性能。现有方法的痛点在于无法准确衡量训练数据对目标任务性能的贡献。
核心思路:ROSE的核心思路是将数据选择问题转化为一个奖励最大化问题。它利用成对偏好损失作为奖励信号,通过选择能够最大化模型在验证集上的偏好一致性的数据子集,来提升任务特定指令调优的性能。这种思路避免了直接依赖交叉熵损失,从而解决了损失与性能错位的问题。
技术框架:ROSE的技术框架主要包含以下几个阶段: 1. 偏好数据收集:构建一个包含少量样本的偏好验证集,用于评估不同数据子集对模型偏好一致性的影响。 2. 影响函数计算:利用影响函数来近似计算每个训练数据点对偏好验证集的影响。影响函数衡量了移除某个训练数据点后,模型在验证集上的偏好一致性变化。 3. 数据选择:根据影响函数的值,选择对偏好验证集影响最大的训练数据点,构成最终的训练数据子集。
关键创新:ROSE最重要的技术创新点在于将数据选择问题与奖励信号(成对偏好损失)相结合。通过最大化模型在验证集上的偏好一致性,ROSE能够选择更符合任务目标的数据,从而提升指令调优的性能。与现有方法相比,ROSE避免了直接依赖交叉熵损失,解决了损失与性能错位的问题。
关键设计:ROSE的关键设计包括: 1. 成对偏好损失:使用成对偏好损失来衡量模型在验证集上的偏好一致性。这种损失函数能够更准确地反映模型对不同输出的偏好程度。 2. 影响函数:使用影响函数来近似计算每个训练数据点对偏好验证集的影响。影响函数的具体形式可以根据实际情况进行选择,例如可以使用一阶泰勒展开来近似计算。 3. 数据选择策略:根据影响函数的值,选择对偏好验证集影响最大的训练数据点。可以使用贪心算法或其他优化算法来选择数据子集。
🖼️ 关键图片

📊 实验亮点
实验结果表明,使用ROSE选择的5%的训练数据,即可达到与全量数据微调相当的性能。ROSE在多个基准数据集上超越了现有的数据选择方法,例如在XXX数据集上提升了X%,在YYY数据集上提升了Y%。定性分析表明,ROSE选择的数据更符合任务目标,能够提升模型的泛化能力。
🎯 应用场景
ROSE可应用于各种需要任务特定指令调优的LLM应用场景,例如智能客服、文本摘要、代码生成等。通过选择更有效的训练数据,ROSE能够提升LLM在特定任务上的性能,降低训练成本,并提高模型的泛化能力。未来,ROSE可以进一步扩展到其他类型的数据选择问题,例如主动学习、数据增强等。
📄 摘要(原文)
Instruction tuning has underscored the significant potential of large language models (LLMs) in producing more human controllable and effective outputs in various domains. In this work, we focus on the data selection problem for task-specific instruction tuning of LLMs. Prevailing methods primarily rely on the crafted similarity metrics to select training data that aligns with the test data distribution. The goal is to minimize instruction tuning loss on the test data, ultimately improving performance on the target task. However, it has been widely observed that instruction tuning loss (i.e., cross-entropy loss for next token prediction) in LLMs often fails to exhibit a monotonic relationship with actual task performance. This misalignment undermines the effectiveness of current data selection methods for task-specific instruction tuning. To address this issue, we introduce ROSE, a novel Reward-Oriented inStruction data sElection method which leverages pairwise preference loss as a reward signal to optimize data selection for task-specific instruction tuning. Specifically, ROSE adapts an influence formulation to approximate the influence of training data points relative to a few-shot preference validation set to select the most task-related training data points. Experimental results show that by selecting just 5\% of the training data using ROSE, our approach can achieve competitive results compared to fine-tuning with the full training dataset, and it surpasses other state-of-the-art data selection methods for task-specific instruction tuning. Our qualitative analysis further confirms the robust generalizability of our method across multiple benchmark datasets and diverse model architectures.