Rank It, Then Ask It: Input Reranking for Maximizing the Performance of LLMs on Symmetric Tasks
作者: Mohsen Dehghankar, Abolfazl Asudeh
分类: cs.LG, cs.DB, cs.IR
发布日期: 2024-11-30
💡 一句话要点
提出基于输入重排序的方法,提升LLM在对称任务上的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 输入重排序 对称任务 辅助LLM 相关性评估
📋 核心要点
- LLM在处理大量无序数据时,容易忽略部分信息,导致在对称任务中表现不佳。
- 通过对输入进行重排序,将重要信息置于LLM更关注的位置,提高模型准确率。
- 实验表明,该重排序方法显著提升了LLM在对称任务上的性能,接近最优上限。
📝 摘要(中文)
大型语言模型(LLM)已迅速成为实用且通用的工具,为广泛领域提供新的解决方案。本文研究了LLM在对称任务中的应用,即对(无序)元素集合进行查询。这类任务的例子包括回答数据库表上的聚合查询。通常,当集合包含大量元素时,LLM倾向于忽略某些元素,从而导致生成准确响应的挑战。LLM接收的输入是有序序列。然而,针对这类问题,我们利用对称输入是无序的这一事实,即重新排序不应影响LLM的响应。观察到LLM不太可能错过输入中特定位置的元素,我们提出了LLM输入重排序问题:找到一种输入排序,在不显式假设查询的情况下,最大化LLM对给定查询的准确性。找到最优排序需要识别(i)每个输入元素对于回答查询的相关性,以及(ii)每个排序位置对于LLM注意力的重要性。我们开发了算法,利用辅助LLM有效地估计这些值。我们在不同的合成和真实数据集上进行了全面的实验,以验证我们的提议并评估我们提出的算法的有效性。实验证实,我们的重排序方法将LLM在对称任务上的准确性提高了高达99%,接近最优上限。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在处理对称任务时,由于输入元素过多且无序,容易忽略部分元素,导致回答准确率下降的问题。现有方法没有充分利用输入数据的对称性,即输入顺序不应影响结果,因此存在性能瓶颈。
核心思路:论文的核心思路是利用输入数据的对称性,通过对输入元素进行重排序,将更重要的元素放置在LLM更关注的位置,从而提高LLM的准确率。这种方法的核心假设是LLM对输入序列的不同位置的关注度不同。
技术框架:该方法主要包含以下几个阶段:1. 元素相关性评估:使用辅助LLM评估每个输入元素与查询的相关性。2. 位置重要性评估:使用辅助LLM评估输入序列中每个位置对于LLM注意力的重要性。3. 排序优化:基于元素相关性和位置重要性,设计算法对输入元素进行排序,目标是最大化LLM的准确率。
关键创新:该方法最重要的创新点在于提出了LLM输入重排序问题,并利用辅助LLM来估计元素相关性和位置重要性。与现有方法相比,该方法充分利用了输入数据的对称性,并针对LLM的特性进行了优化。
关键设计:论文设计了具体的算法来估计元素相关性和位置重要性。具体来说,使用辅助LLM对每个元素进行评估,并根据其对查询的贡献程度进行排序。同时,通过实验分析LLM对输入序列不同位置的关注度,并据此调整排序策略。论文还定义了优化目标,即最大化LLM的准确率,并设计了相应的优化算法。
🖼️ 关键图片

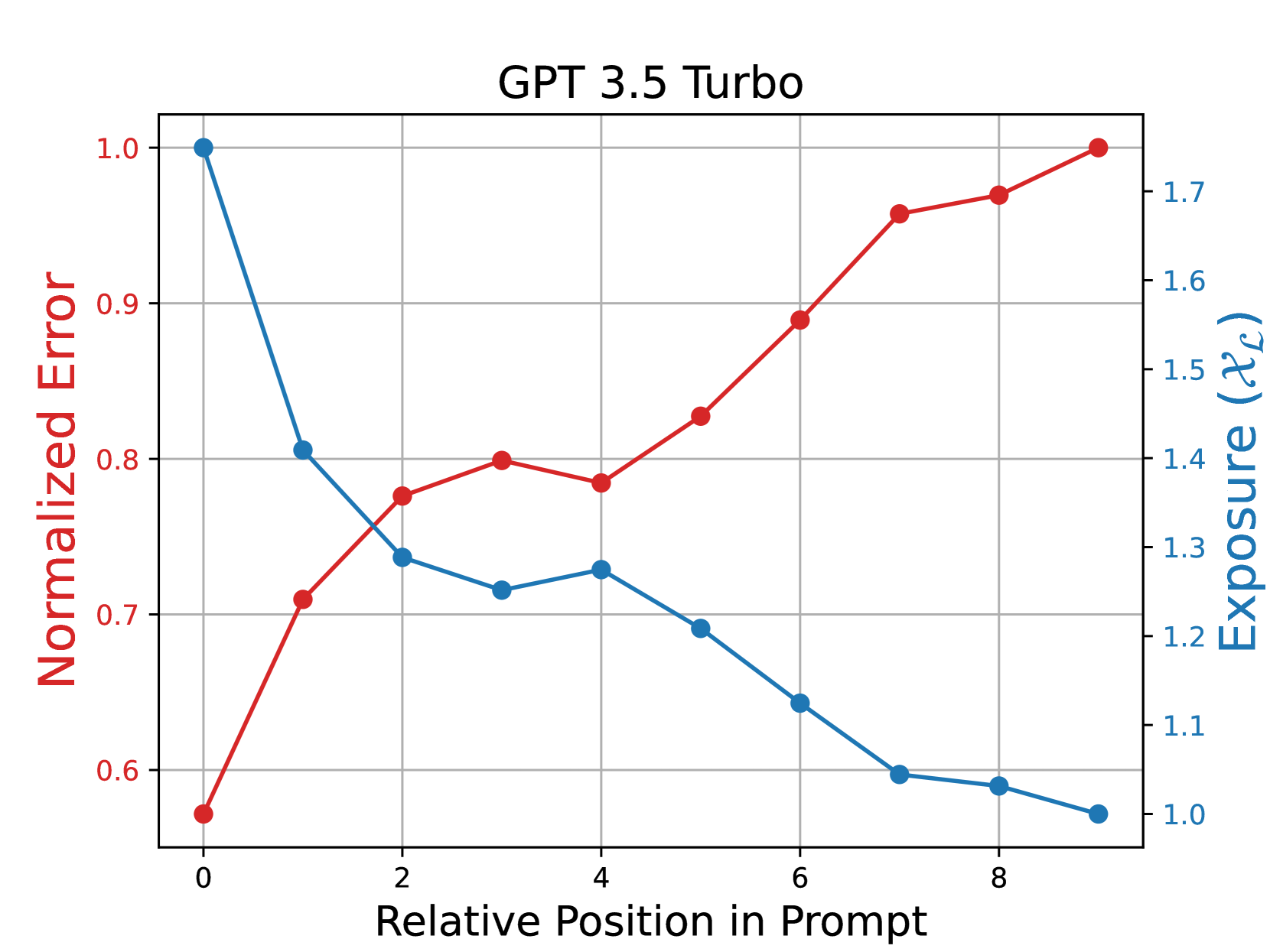

📊 实验亮点
实验结果表明,该重排序方法在不同的合成和真实数据集上均取得了显著的性能提升。具体来说,该方法将LLM在对称任务上的准确性提高了高达99%,接近最优上限。与没有进行重排序的基线方法相比,该方法取得了显著的性能提升,验证了其有效性。
🎯 应用场景
该研究成果可应用于各种需要处理无序数据集合的场景,例如数据库查询优化、信息检索、推荐系统等。通过对输入数据进行重排序,可以显著提高LLM在这些任务中的性能,提升用户体验,并降低计算成本。未来,该方法可以进一步扩展到其他类型的任务和模型。
📄 摘要(原文)
Large language models (LLMs) have quickly emerged as practical and versatile tools that provide new solutions for a wide range of domains. In this paper, we consider the application of LLMs on symmetric tasks where a query is asked on an (unordered) bag of elements. Examples of such tasks include answering aggregate queries on a database table. In general, when the bag contains a large number of elements, LLMs tend to overlook some elements, leading to challenges in generating accurate responses to the query. LLMs receive their inputs as ordered sequences. However, in this problem, we leverage the fact that the symmetric input is not ordered, and reordering should not affect the LLM's response. Observing that LLMs are less likely to miss elements at certain positions of the input, we introduce the problem of LLM input reranking: to find a ranking of the input that maximizes the LLM's accuracy for the given query without making explicit assumptions about the query. Finding the optimal ranking requires identifying (i) the relevance of each input element for answering the query and (ii) the importance of each rank position for the LLM's attention. We develop algorithms for estimating these values efficiently utilizing a helper LLM. We conduct comprehensive experiments on different synthetic and real datasets to validate our proposal and to evaluate the effectiveness of our proposed algorithms. Our experiments confirm that our reranking approach improves the accuracy of the LLMs on symmetric tasks by up to $99\%$ proximity to the optimum upper bound.