TAROT: Targeted Data Selection via Optimal Transport
作者: Lan Feng, Fan Nie, Yuejiang Liu, Alexandre Alahi
分类: cs.LG, cs.CV, stat.ML
发布日期: 2024-11-30 (更新: 2025-07-02)
🔗 代码/项目: GITHUB
💡 一句话要点
提出TAROT,通过最优传输实现面向复杂目标域的数据选择。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数据选择 最优传输 领域自适应 深度学习 特征白化
📋 核心要点
- 现有基于影响力的贪婪算法在处理复杂、多模态目标数据时,由于无法捕捉多个内在模式而表现不佳。
- TAROT通过引入白化特征距离来缓解主导特征的偏差,并利用最优传输理论最小化选择数据与目标域的距离。
- 实验结果表明,TAROT在语义分割、运动预测和指令调优等任务中均优于现有最优方法,展现了其通用性。
📝 摘要(中文)
我们提出了TAROT,一个基于最优传输理论的有目标数据选择框架。以往的有目标数据选择方法主要依赖于基于影响力的贪婪启发式算法来提升特定领域的性能。虽然这些方法在有限的、单峰数据(即遵循单一模式的数据)上有效,但随着目标数据复杂性的增加,它们会遇到困难。具体来说,在多峰分布中,这些启发式算法无法解释多个内在模式,导致次优的数据选择。这项工作确定了导致这种限制的两个主要因素:(i)高维影响估计中,主导特征成分的不成比例的影响;(ii)贪婪选择策略中固有的限制性线性加性假设。为了解决这些挑战,TAROT结合了白化特征距离来减轻主导特征偏差,从而提供更可靠的数据影响度量。在此基础上,TAROT使用白化特征距离来量化和最小化所选数据和目标域之间的最优传输距离。值得注意的是,这种最小化也有助于估计最佳选择比例。我们在包括语义分割、运动预测和指令调优在内的多个任务中评估了TAROT。结果始终表明,TAROT优于最先进的方法,突显了其在各种深度学习任务中的通用性。
🔬 方法详解
问题定义:论文旨在解决有目标数据选择问题,即如何从源数据集中选择最具代表性的子集,以优化模型在特定目标域上的性能。现有方法,特别是基于影响力的贪婪算法,在高维数据和多模态分布下表现不佳,因为它们容易受到主导特征的影响,并且假设数据影响是线性可加的,这在复杂数据集中并不成立。
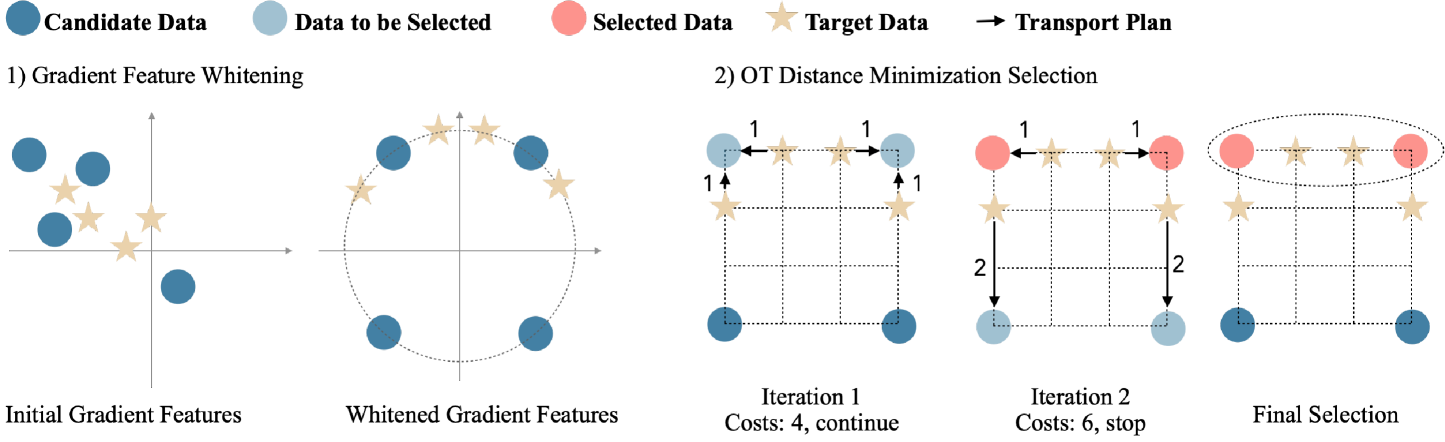
核心思路:TAROT的核心思路是利用最优传输理论来衡量源数据和目标数据之间的距离,并选择能够最小化这种距离的源数据子集。通过最小化最优传输距离,TAROT能够选择与目标域分布更接近的数据,从而提高模型在目标域上的泛化能力。此外,TAROT还引入了白化特征距离,以减少主导特征的影响,使距离度量更加公平。
技术框架:TAROT的整体框架包括以下几个主要步骤:1) 特征提取:从源数据和目标数据中提取特征表示。2) 白化特征距离计算:使用白化特征距离来衡量数据点之间的相似度,降低主导特征的影响。3) 最优传输距离最小化:构建最优传输问题,目标是找到一个从源数据到目标数据的最优传输方案,使得传输成本最小。4) 数据选择:根据最优传输方案,选择源数据集中与目标数据最相关的子集。
关键创新:TAROT的关键创新在于以下几点:1) 使用最优传输理论进行数据选择,能够更好地捕捉数据分布的整体结构,避免了贪婪算法的局部最优问题。2) 引入白化特征距离,降低了主导特征的影响,使得距离度量更加公平和鲁棒。3) 能够自动估计最佳选择比例,无需手动调整。
关键设计:TAROT的关键设计包括:1) 白化特征距离的计算方式,具体如何进行白化操作以消除特征之间的相关性。2) 最优传输问题的具体形式,包括传输成本的定义和约束条件。3) 如何利用最优传输方案进行数据选择,例如,选择传输量最大的数据点。
🖼️ 关键图片


📊 实验亮点
实验结果表明,TAROT在语义分割、运动预测和指令调优等任务中均优于现有最优方法。例如,在语义分割任务中,TAROT相比于基线方法取得了显著的性能提升。这些结果表明,TAROT能够有效地选择与目标域相关的数据,从而提高模型在目标域上的性能。
🎯 应用场景
TAROT可应用于各种需要数据选择的深度学习任务,例如,在数据标注成本高昂的情况下,可以选择最具代表性的数据进行标注,以降低成本并提高模型性能。此外,TAROT还可以用于领域自适应学习,选择与目标域最相似的源数据进行训练,以提高模型在目标域上的泛化能力。该方法在自动驾驶、医疗影像分析等领域具有广泛的应用前景。
📄 摘要(原文)
We propose TAROT, a targeted data selection framework grounded in optimal transport theory. Previous targeted data selection methods primarily rely on influence-based greedy heuristics to enhance domain-specific performance. While effective on limited, unimodal data (i.e., data following a single pattern), these methods struggle as target data complexity increases. Specifically, in multimodal distributions, these heuristics fail to account for multiple inherent patterns, leading to suboptimal data selection. This work identifies two primary factors contributing to this limitation: (i) the disproportionate impact of dominant feature components in high-dimensional influence estimation, and (ii) the restrictive linear additive assumptions inherent in greedy selection strategies. To address these challenges, TAROT incorporates whitened feature distance to mitigate dominant feature bias, providing a more reliable measure of data influence. Building on this, TAROT uses whitened feature distance to quantify and minimize the optimal transport distance between the selected data and target domains. Notably, this minimization also facilitates the estimation of optimal selection ratios. We evaluate TAROT across multiple tasks, including semantic segmentation, motion prediction, and instruction tuning. Results consistently show that TAROT outperforms state-of-the-art methods, highlighting its versatility across various deep learning tasks. Code is available at https://github.com/vita-epfl/TAROT.