Table Integration in Data Lakes Unleashed: Pairwise Integrability Judgment, Integrable Set Discovery, and Multi-Tuple Conflict Resolution
作者: Daomin Ji, Hui Luo, Zhifeng Bao, Shane Culpepper
分类: cs.DB, cs.IR, cs.LG
发布日期: 2024-11-30 (更新: 2025-04-13)
备注: This paper is accepted by VLDB Journal
💡 一句话要点
提出数据湖中表集成方法,解决可集成性判断、集合发现和冲突消解问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数据湖 表集成 自监督学习 对抗学习 对比学习 社区检测 上下文学习
📋 核心要点
- 现有表集成方法在数据湖场景下面临标记数据稀缺的挑战,难以准确判断元组的可集成性。
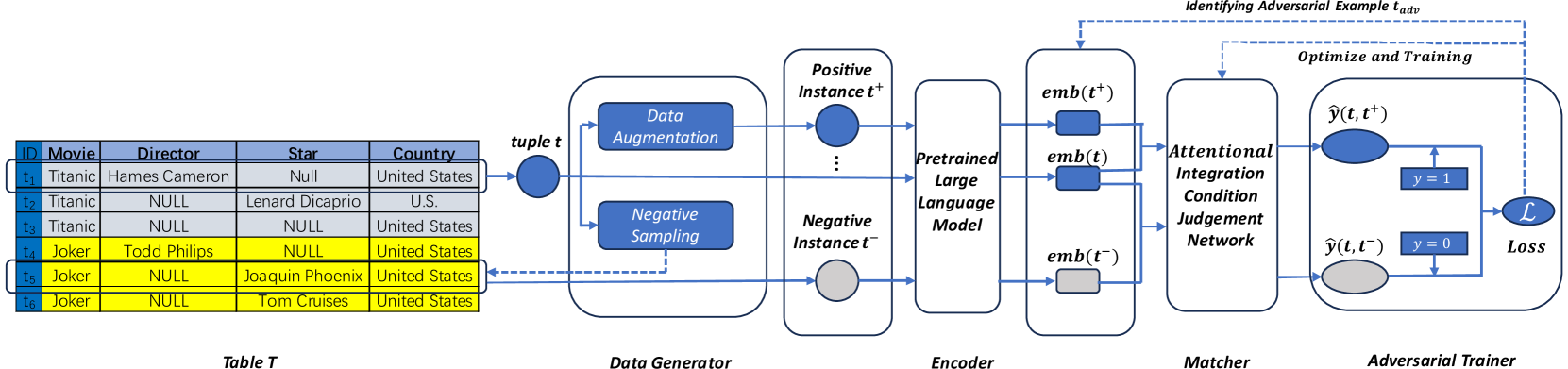
- 提出自监督对抗对比学习方法,利用数据增强和对抗样本自动生成训练数据,提升分类器性能。
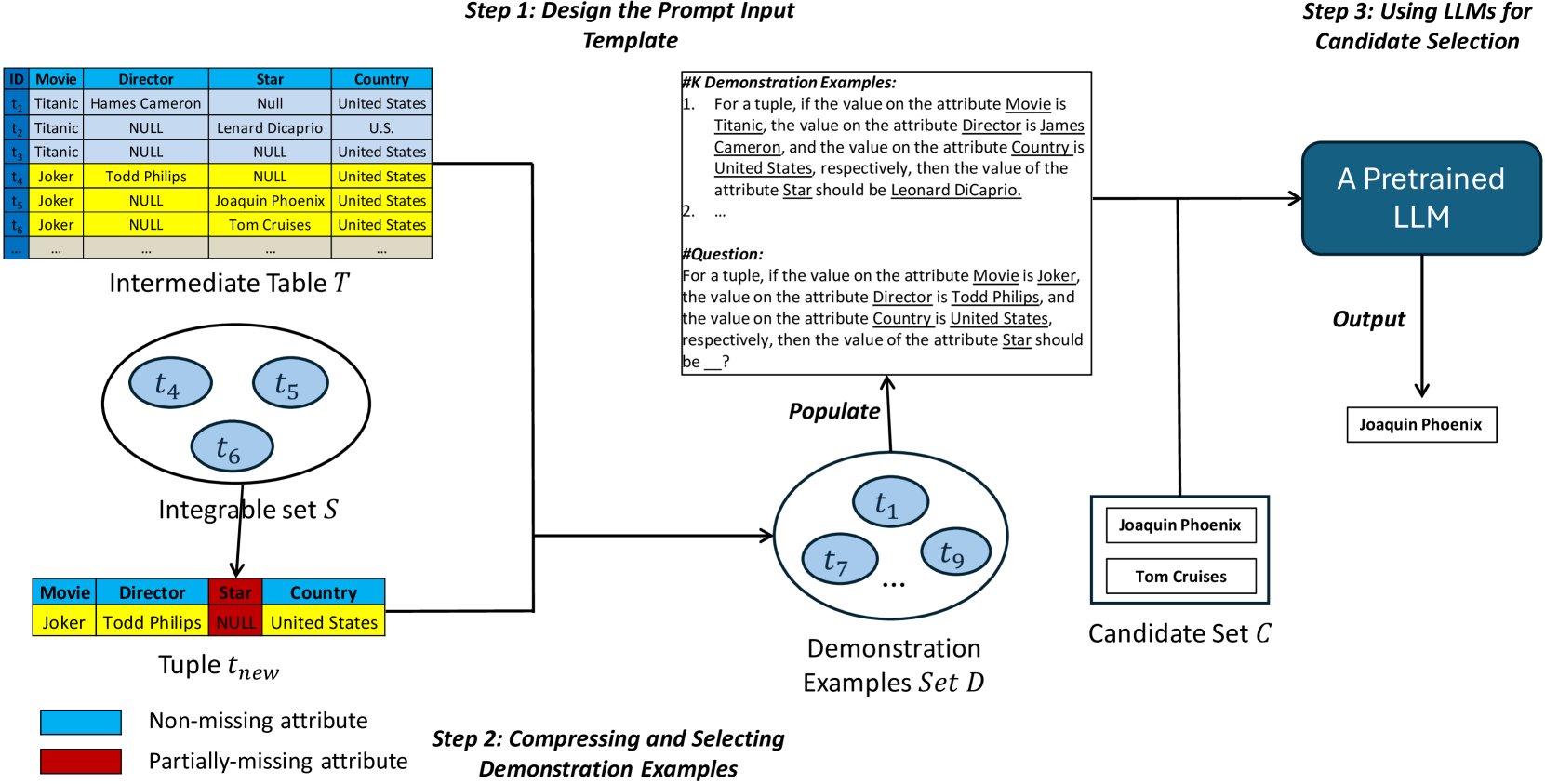
- 利用大型语言模型的上下文学习能力,在少量标注数据下有效解决多元组集成时的冲突消解问题。
📝 摘要(中文)
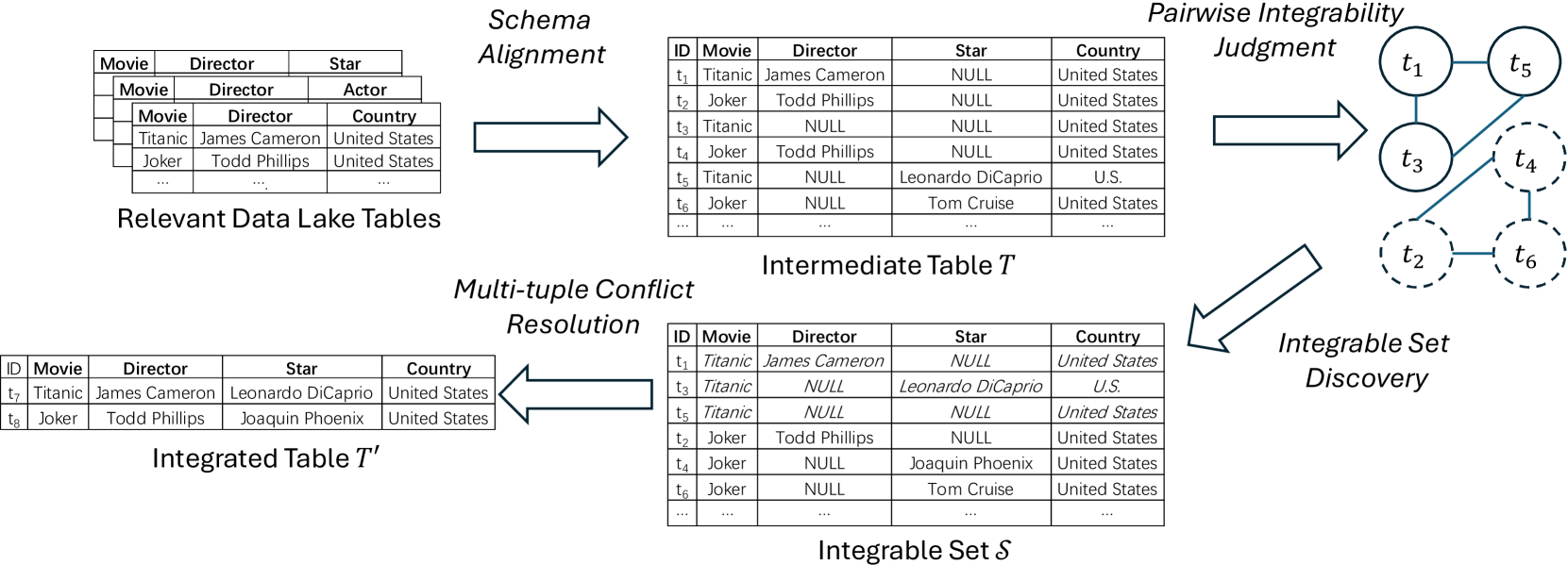
本文研究了数据湖中多表集成的问题,重点关注三个核心任务:1) 成对可集成性判断,确定元组对是否可集成,考虑语义等价和笔误;2) 可集成集合发现,基于成对可集成性判断,识别表中的所有可集成集合;3) 多元组冲突消解,解决集成多个元组时出现的冲突。为此,我们训练了一个二元分类器来解决成对可集成性判断任务。鉴于数据湖中标记数据的稀缺性,我们提出了一种自监督对抗对比学习算法来进行分类,该算法结合了数据增强方法和对抗样本来自动生成新的训练数据。在成对可集成性判断的输出基础上,每个可集成集合可以被视为一个社区,一个密集连接的子图,其中节点和边分别对应于表中的元组及其成对可集成性。我们进而研究了各种社区检测算法来解决可集成集合发现的目标。为了解决多元组冲突消解问题,我们引入了一种创新的上下文学习方法。该方法利用大型语言模型(LLM)中嵌入的知识来有效地解决集成多个元组时出现的冲突。值得注意的是,我们的方法最大限度地减少了对带注释数据的需求,使其特别适用于标记数据集稀缺的场景。
🔬 方法详解
问题定义:论文旨在解决数据湖环境下多表集成的问题。现有方法在数据湖场景下面临数据量大、数据质量参差不齐、缺乏标注数据等挑战,导致无法准确判断哪些元组可以集成,以及集成后可能出现的冲突如何解决。现有方法难以有效利用数据湖中蕴含的丰富信息,且对人工标注数据的依赖性较高。
核心思路:论文的核心思路是将表集成问题分解为三个子问题:成对可集成性判断、可集成集合发现和多元组冲突消解。针对每个子问题,分别设计了相应的解决方案。通过自监督学习和上下文学习,降低了对标注数据的依赖,提高了集成效率和准确性。
技术框架:整体框架包含三个主要模块:1) 成对可集成性判断模块,使用自监督对抗对比学习训练二元分类器;2) 可集成集合发现模块,将可集成集合视为社区,利用社区检测算法进行发现;3) 多元组冲突消解模块,利用大型语言模型的上下文学习能力解决冲突。整个流程首先进行成对判断,然后发现可集成集合,最后解决冲突完成集成。
关键创新:论文的关键创新在于:1) 提出了自监督对抗对比学习方法,有效利用未标注数据进行模型训练,缓解了数据稀缺问题;2) 将社区检测算法应用于可集成集合发现,提供了一种新的视角;3) 引入上下文学习方法,利用大型语言模型的知识进行冲突消解,减少了对标注数据的依赖。
关键设计:在自监督对抗对比学习中,使用了数据增强技术生成正样本对,并使用对抗样本生成负样本对,通过对比学习损失函数优化模型。在社区检测中,选择了合适的社区检测算法,并根据实际情况调整了参数。在上下文学习中,精心设计了提示语(prompt),引导大型语言模型进行冲突消解。
🖼️ 关键图片
📊 实验亮点
论文通过实验验证了所提出方法的有效性。在成对可集成性判断任务中,自监督对抗对比学习方法相比传统方法取得了显著的性能提升。在可集成集合发现任务中,社区检测算法能够有效地识别出可集成集合。在多元组冲突消解任务中,上下文学习方法在少量标注数据下取得了与监督学习方法相近的性能,证明了其在数据稀缺场景下的优势。
🎯 应用场景
该研究成果可应用于企业级数据湖的建设和管理,帮助企业整合来自不同数据源的数据,构建统一的数据视图,提升数据分析和决策能力。例如,可以应用于客户关系管理、供应链管理、金融风控等领域,实现更精准的客户画像、更高效的供应链协同和更有效的风险控制。未来,该技术有望进一步推广到更广泛的数据集成场景,例如开放数据平台、知识图谱构建等。
📄 摘要(原文)
Table integration aims to create a comprehensive table by consolidating tuples containing relevant information. In this work, we investigate the challenge of integrating multiple tables from a data lake, focusing on three core tasks: 1) pairwise integrability judgment, which determines whether a tuple pair is integrable, accounting for any occurrences of semantic equivalence or typographical errors; 2) integrable set discovery, which identifies all integrable sets in a table based on pairwise integrability judgments established in the first task; 3) multi-tuple conflict resolution, which resolves conflicts between multiple tuples during integration. To this end, we train a binary classifier to address the task of pairwise integrability judgment. Given the scarcity of labeled data in data lakes, we propose a self-supervised adversarial contrastive learning algorithm to perform classification, which incorporates data augmentation methods and adversarial examples to autonomously generate new training data. Upon the output of pairwise integrability judgment, each integrable set can be considered as a community, a densely connected sub-graph where nodes and edges correspond to tuples in the table and their pairwise integrability respectively, we proceed to investigate various community detection algorithms to address the integrable set discovery objective. Moving forward to tackle multi-tuple conflict resolution, we introduce an innovative in-context learning methodology. This approach capitalizes on the knowledge embedded within large language models (LLMs) to effectively resolve conflicts that arise when integrating multiple tuples. Notably, our method minimizes the need for annotated data, making it particularly suited for scenarios where labeled datasets are scarce.