CAREL: Instruction-guided reinforcement learning with cross-modal auxiliary objectives
作者: Armin Saghafian, Amirmohammad Izadi, Negin Hashemi Dijujin, Mahdieh Soleymani Baghshah
分类: cs.LG, cs.AI
发布日期: 2024-11-29 (更新: 2025-09-07)
备注: Accepted to TMLR 2025
💡 一句话要点
CAREL:利用跨模态辅助目标和指令跟踪的指令引导强化学习
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 指令引导 跨模态学习 辅助损失函数 指令跟踪 多模态融合 环境泛化
📋 核心要点
- 现有语言引导的强化学习方法在环境泛化能力上存在不足,难以有效理解指令与环境的关联。
- CAREL框架通过引入跨模态辅助损失函数和指令跟踪机制,提升智能体对指令的理解和环境适应能力。
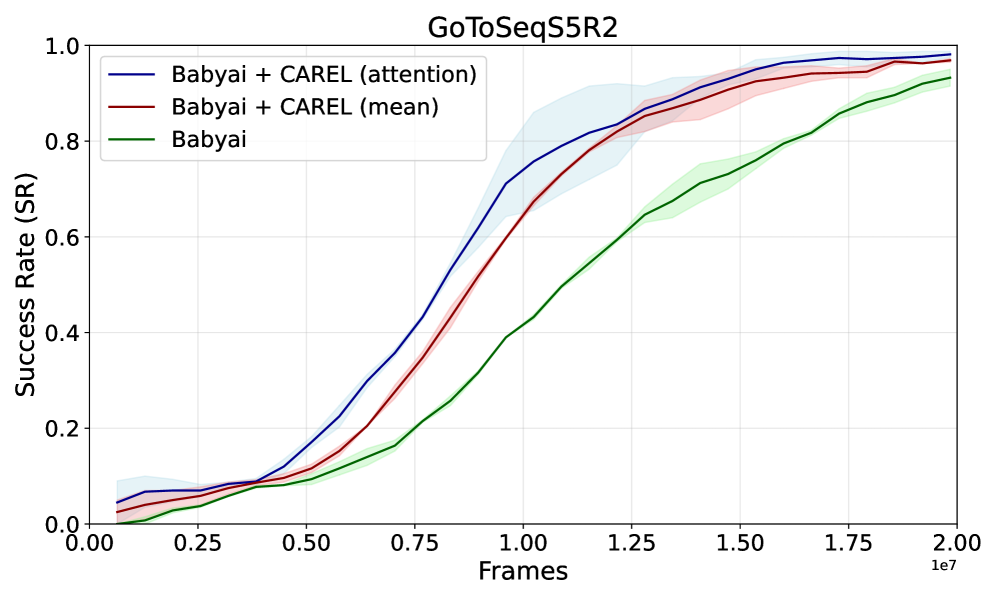
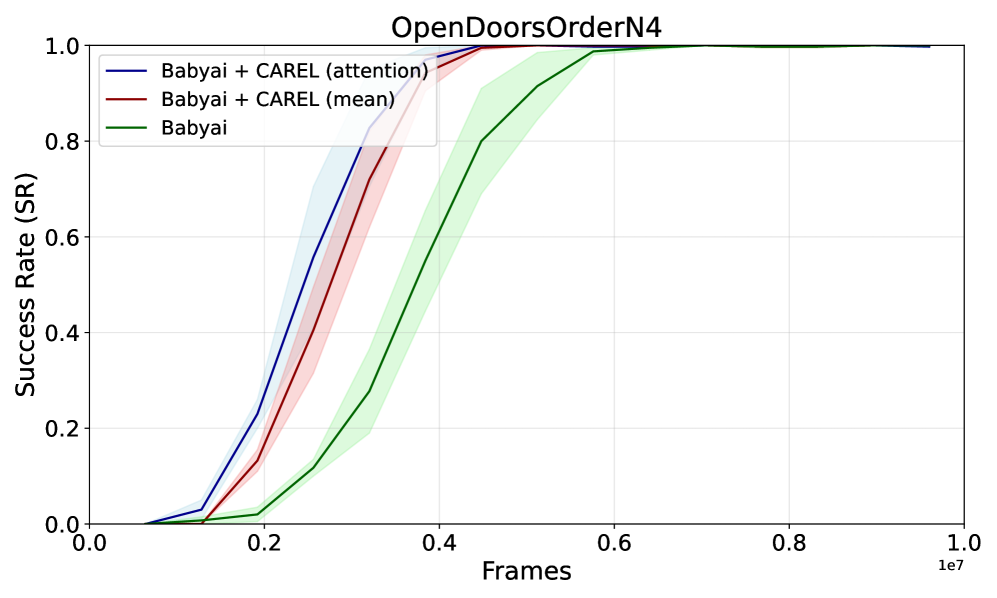
- 实验结果表明,CAREL在多模态强化学习任务中表现出更高的样本效率和更好的系统泛化能力。
📝 摘要(中文)
在语言引导的目标导向强化学习问题中,将指令与环境进行关联是关键步骤。在自动强化学习中,一个主要关注点是增强模型在各种任务和环境中的泛化能力。在目标导向场景中,智能体必须理解环境上下文中指令的不同部分,才能成功完成整体任务。本文提出CAREL(跨模态辅助强化学习)框架,利用视频-文本检索文献中获得的辅助损失函数以及一种名为指令跟踪的新方法来解决这个问题,该方法可以自动跟踪环境中的进度。实验结果表明,该框架在多模态强化学习问题中具有卓越的样本效率和系统泛化能力。代码库已公开。
🔬 方法详解
问题定义:论文旨在解决语言引导的强化学习任务中,智能体难以有效理解指令并将其与环境状态关联的问题。现有方法在复杂环境中泛化能力较弱,无法充分利用指令信息指导智能体行动。
核心思路:CAREL的核心思路是利用跨模态信息,通过辅助损失函数学习指令和环境状态之间的关联,并引入指令跟踪机制来监督智能体的学习过程,使其更好地理解指令的执行进度。
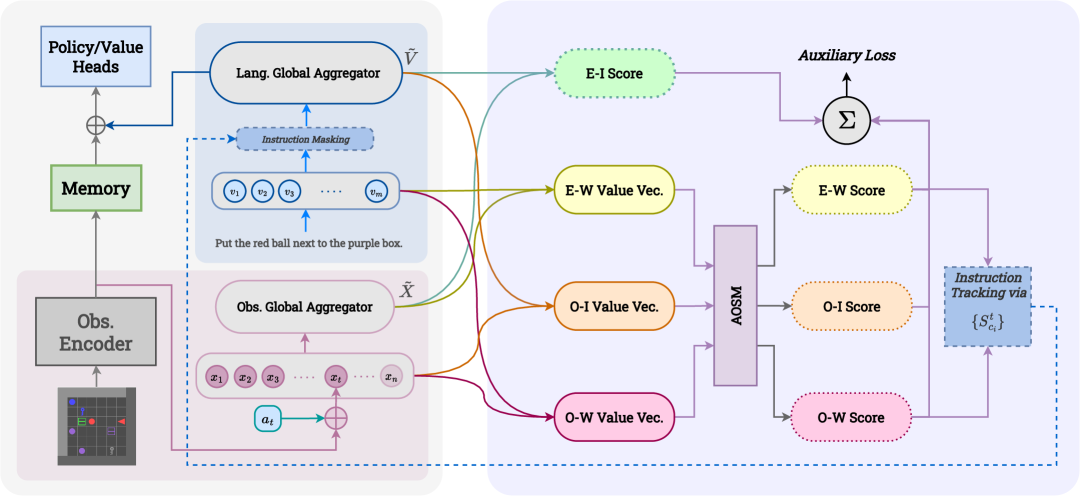
技术框架:CAREL框架包含以下主要模块:1) 强化学习智能体,负责与环境交互并学习策略;2) 跨模态编码器,将指令和环境状态编码为向量表示;3) 辅助损失函数,用于学习指令和状态表示之间的关联;4) 指令跟踪模块,用于监督智能体在环境中的执行进度。整体流程是,智能体根据当前状态和指令选择动作,执行动作后获得新的状态和奖励,然后利用强化学习算法更新策略,同时利用辅助损失函数和指令跟踪模块优化跨模态编码器。
关键创新:CAREL的关键创新在于:1) 引入了受视频-文本检索启发的跨模态辅助损失函数,用于学习指令和环境状态之间的细粒度关联;2) 提出了指令跟踪机制,自动跟踪智能体在环境中的执行进度,并提供额外的监督信号。
关键设计:辅助损失函数包括对比损失和三元组损失,用于拉近相关指令和状态表示之间的距离,并推远不相关表示之间的距离。指令跟踪模块通过预测当前状态下应该执行的指令片段来监督智能体的学习过程。具体的网络结构和参数设置在论文中有详细描述(未知)。
🖼️ 关键图片
📊 实验亮点
实验结果表明,CAREL在多模态强化学习任务中显著优于现有方法,在样本效率和系统泛化能力方面均有提升。具体性能数据和对比基线在论文中有详细展示(未知),但摘要中强调了其superior sample efficiency和systematic generalization。
🎯 应用场景
CAREL框架可应用于机器人导航、游戏AI、自动驾驶等领域,尤其适用于需要理解自然语言指令并与环境交互的复杂任务。该研究有助于提升智能体在真实世界环境中的泛化能力和任务完成效率,具有重要的实际应用价值和广阔的发展前景。
📄 摘要(原文)
Grounding the instruction in the environment is a key step in solving language-guided goal-reaching reinforcement learning problems. In automated reinforcement learning, a key concern is to enhance the model's ability to generalize across various tasks and environments. In goal-reaching scenarios, the agent must comprehend the different parts of the instructions within the environmental context in order to complete the overall task successfully. In this work, we propose CAREL (Cross-modal Auxiliary REinforcement Learning) as a new framework to solve this problem using auxiliary loss functions inspired by video-text retrieval literature and a novel method called instruction tracking, which automatically keeps track of progress in an environment. The results of our experiments suggest superior sample efficiency and systematic generalization for this framework in multi-modal reinforcement learning problems. Our code base is available here.