Scaling Particle Collision Data Analysis
作者: Hengkui Wu, Panpan Chi, Yongfeng Zhu, Liujiang Liu, Shuyang Hu, Yuexin Wang, Chen Zhou, Qihao Wang, Yingsi Xin, Bruce Liu, Dahao Liang, Xinglong Jia, Manqi Ruan
分类: cs.LG, hep-ex, physics.data-an
发布日期: 2024-11-28 (更新: 2024-12-10)
🔗 代码/项目: GITHUB
💡 一句话要点
提出BBT-Neutron,一种用于大规模粒子碰撞数据分析的通用架构。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 高能物理 大型语言模型 二进制分词 射流起源识别 数据分析 Transformer模型 预训练模型
📋 核心要点
- 现有方法在高能物理等领域处理大规模数值数据分析时,面临BPE分词效率低下的挑战。
- BBT-Neutron采用二进制分词方法,支持在文本和大规模数值实验数据的混合数据上进行预训练。
- BBT-Neutron在射流起源识别任务上取得了与最先进模型相当的性能,并展现出良好的数据缩放性。
📝 摘要(中文)
数十年来,研究人员针对不同学科的科学挑战开发了特定任务的模型。最近,大型语言模型(LLM)在处理通用任务方面表现出巨大的能力;然而,这些模型在解决实际科学问题时遇到了困难,特别是在涉及大规模数值数据分析的领域,如实验高能物理。这种限制主要是由于BPE分词在数值数据上的低效性。在本文中,我们提出了一种与任务无关的架构BBT-Neutron,它采用二进制分词方法,以促进在文本和大规模数值实验数据的混合数据上进行预训练。我们展示了BBT-Neutron在射流起源识别(JoI)中的应用,这是一个高能物理中关键的分类挑战,用于区分源自各种夸克或胶子的射流。我们的结果表明,BBT-Neutron达到了与最先进的特定任务JoI模型相当的性能。此外,我们研究了BBT-Neutron的性能随数据量增加的缩放行为,表明BBT-Neutron有可能作为粒子物理数据分析的基础模型,并可能扩展到大型科学实验、工业制造和空间计算等广泛的科学计算应用。
🔬 方法详解
问题定义:论文旨在解决高能物理领域中,现有大型语言模型(LLM)在处理大规模数值数据分析任务时遇到的困难。具体来说,BPE分词方法在处理数值数据时效率低下,导致LLM难以有效应用于粒子碰撞数据的分析,例如射流起源识别(JoI)任务。现有JoI模型通常是特定任务的模型,缺乏通用性和可扩展性。
核心思路:论文的核心思路是设计一种与任务无关的架构,能够有效处理大规模数值数据和文本数据的混合数据,并具备良好的可扩展性。通过采用二进制分词方法,克服了BPE分词在数值数据上的局限性,从而使模型能够更好地理解和分析粒子碰撞数据。
技术框架:BBT-Neutron的整体架构包含一个二进制分词器(Binary Tokenizer)和一个Transformer模型。首先,数值数据被转换为二进制表示,然后通过二进制分词器将其分割成token序列。这些token序列与文本数据一起输入到Transformer模型中进行预训练。预训练后的模型可以应用于各种下游任务,例如射流起源识别。
关键创新:BBT-Neutron最重要的技术创新点在于其二进制分词方法。与传统的BPE分词方法不同,二进制分词能够更有效地处理数值数据,避免了将数值数据转换为文本表示时可能造成的精度损失和信息丢失。这种方法使得模型能够更好地捕捉数值数据中的细微变化和模式。
关键设计:BBT-Neutron的关键设计包括:1) 使用二进制分词器将数值数据转换为token序列;2) 使用Transformer模型作为主干网络,以捕捉数据中的长程依赖关系;3) 在大规模文本和数值数据的混合数据集上进行预训练,以提高模型的泛化能力;4) 针对射流起源识别任务,使用交叉熵损失函数进行微调。
🖼️ 关键图片


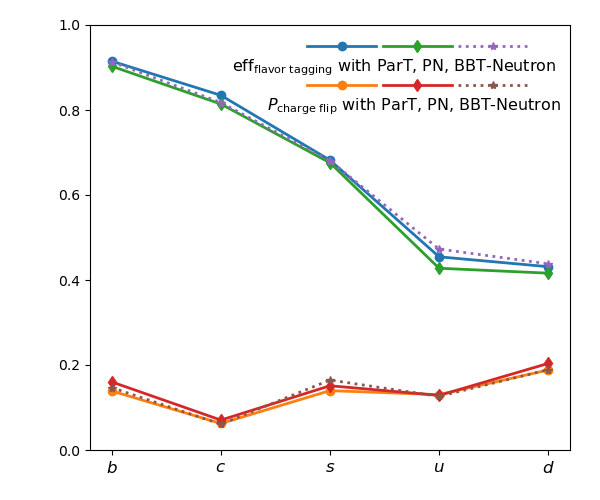
📊 实验亮点
BBT-Neutron在射流起源识别(JoI)任务上取得了与最先进的特定任务模型相当的性能,证明了其有效性。更重要的是,实验结果表明,BBT-Neutron的性能随着数据量的增加而持续提升,展现出良好的可扩展性,这表明它有潜力成为粒子物理数据分析的基础模型。
🎯 应用场景
BBT-Neutron具有广泛的应用前景,不仅可以应用于高能物理领域,例如粒子碰撞数据的分析和模拟,还可以扩展到其他涉及大规模数值数据分析的科学计算领域,如工业制造中的质量控制、空间计算中的环境建模等。该模型有望成为一个通用的基础模型,为各种科学和工程应用提供强大的数据分析能力。
📄 摘要(原文)
For decades, researchers have developed task-specific models to address scientific challenges across diverse disciplines. Recently, large language models (LLMs) have shown enormous capabilities in handling general tasks; however, these models encounter difficulties in addressing real-world scientific problems, particularly in domains involving large-scale numerical data analysis, such as experimental high energy physics. This limitation is primarily due to BPE tokenization's inefficacy with numerical data. In this paper, we propose a task-agnostic architecture, BBT-Neutron, which employs a binary tokenization method to facilitate pretraining on a mixture of textual and large-scale numerical experimental data. We demonstrate the application of BBT-Neutron to Jet Origin Identification (JoI), a critical categorization challenge in high-energy physics that distinguishes jets originating from various quarks or gluons. Our results indicate that BBT-Neutron achieves comparable performance to state-of-the-art task-specific JoI models. Furthermore, we examine the scaling behavior of BBT-Neutron's performance with increasing data volume, suggesting the potential for BBT-Neutron to serve as a foundational model for particle physics data analysis, with possible extensions to a broad spectrum of scientific computing applications for Big Science experiments, industrial manufacturing and spacial computing. The project code is available at https://github.com/supersymmetry-technologies/bbt-neutron.