On the Role of Discrete Representation in Sparse Mixture of Experts
作者: Giang Do, Kha Pham, Hung Le, Truyen Tran
分类: cs.LG
发布日期: 2024-11-28 (更新: 2025-07-27)
备注: 17 pages
💡 一句话要点
提出VQMoE,利用向量量化离散表示解决稀疏专家混合模型中的路由不一致问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 稀疏专家混合模型 向量量化 离散表示 路由算法 大型语言模型
📋 核心要点
- SMoE中的路由模块易导致路由不一致和表示崩溃,是模型性能瓶颈。
- VQMoE通过向量量化学习输入的离散表示,并用该表示间接指向专家,避免直接路由。
- 实验表明,VQMoE在鲁棒性上提升28%,并在微调任务中保持了良好性能。
📝 摘要(中文)
稀疏专家混合模型(SMoE)是扩展模型容量而不增加计算成本的有效方案。SMoE的关键组成部分是路由模块,它负责将输入分配给相关的专家;然而,路由模块也存在主要弱点,导致路由不一致和表示崩溃问题。本文提出了一种替代方案,通过间接方式将专家分配给输入,即利用指向专家的输入的离散表示。这些离散表示通过向量量化学习得到,从而产生一种名为向量量化专家混合模型(VQMoE)的新架构。我们提供了理论支持和经验证据,证明了VQMoE克服传统路由模块中存在的挑战的能力。通过对大型语言模型和视觉任务进行预训练和微调的广泛评估,我们表明,与其他SMoE路由方法相比,VQMoE在鲁棒性方面实现了28%的提升,同时在微调任务中保持了强大的性能。
🔬 方法详解
问题定义:SMoE旨在扩展模型容量,但其路由模块存在路由不一致和表示崩溃的问题。传统的路由方法直接将输入分配给专家,容易导致某些专家过载而其他专家利用不足,从而影响模型的学习效率和泛化能力。
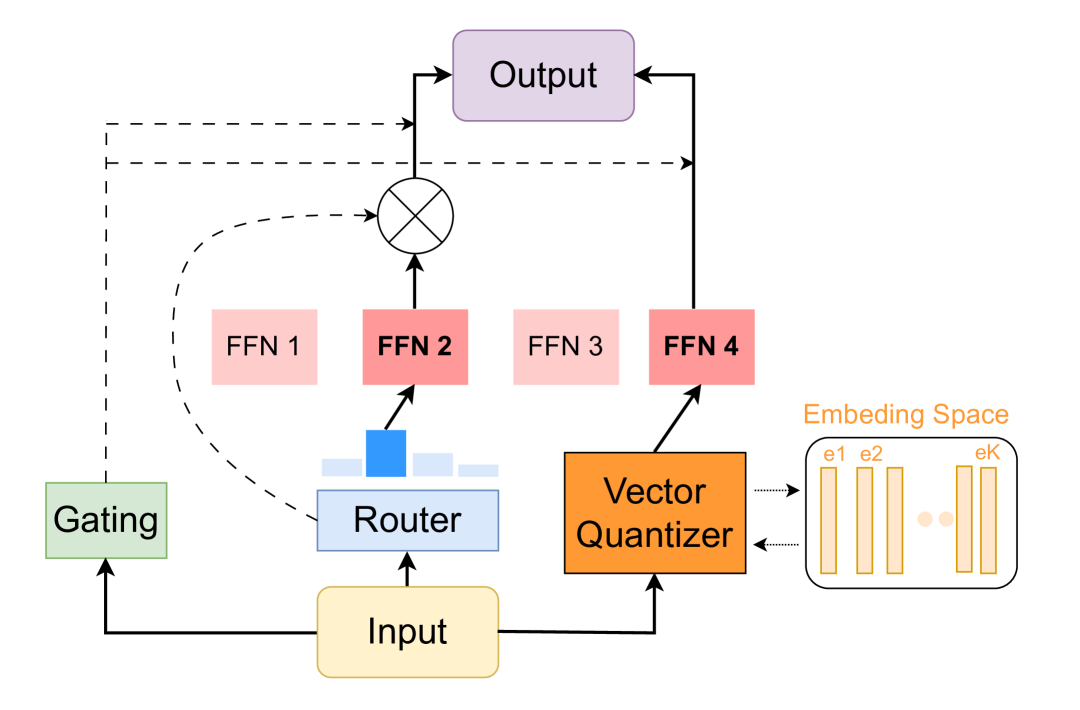
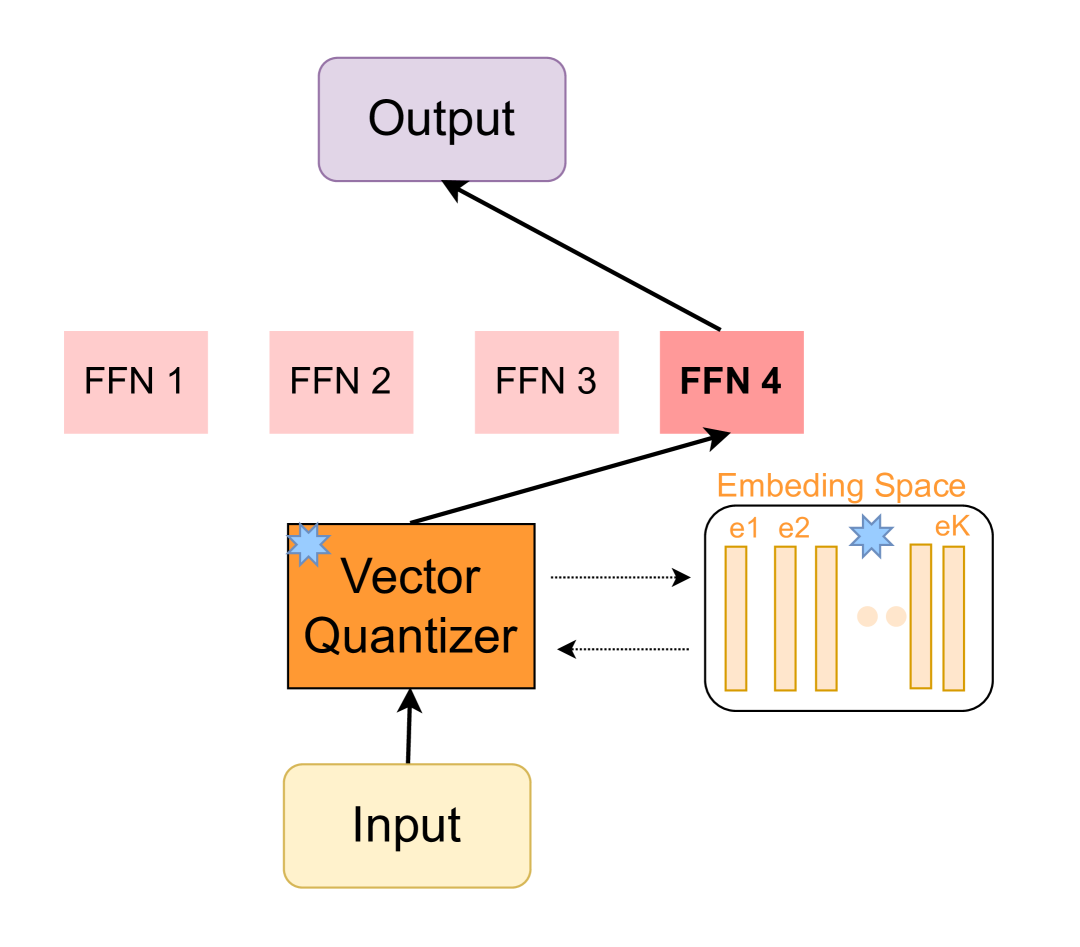
核心思路:VQMoE的核心思路是通过引入离散表示作为输入和专家之间的桥梁,从而避免直接路由。具体来说,VQMoE首先将输入进行向量量化,得到离散的码本索引。然后,使用这些索引来选择相应的专家。这种间接路由的方式可以有效地缓解路由不一致的问题,并促进专家之间的负载均衡。
技术框架:VQMoE的整体架构包括以下几个主要模块:1) 输入编码器:将输入转换为连续的向量表示。2) 向量量化器:将连续向量量化为离散的码本索引。3) 专家网络:一组并行的神经网络,每个网络代表一个专家。4) 专家选择器:根据离散的码本索引选择相应的专家进行计算。5) 输出解码器:将专家的输出进行聚合,得到最终的预测结果。
关键创新:VQMoE最重要的技术创新点在于使用向量量化来学习输入的离散表示,并利用这些离散表示进行专家选择。与传统的路由方法相比,VQMoE的路由过程更加稳定和可控,可以有效地避免路由不一致和表示崩溃的问题。
关键设计:VQMoE的关键设计包括:1) 码本大小的选择:码本大小决定了离散表示的粒度。较大的码本可以提供更精细的表示,但也可能增加计算成本。2) 向量量化的方法:可以使用不同的向量量化方法,如K-means聚类或Gumbel-Softmax。3) 专家网络的结构:专家网络可以是任何类型的神经网络,如MLP、CNN或Transformer。
🖼️ 关键图片
📊 实验亮点
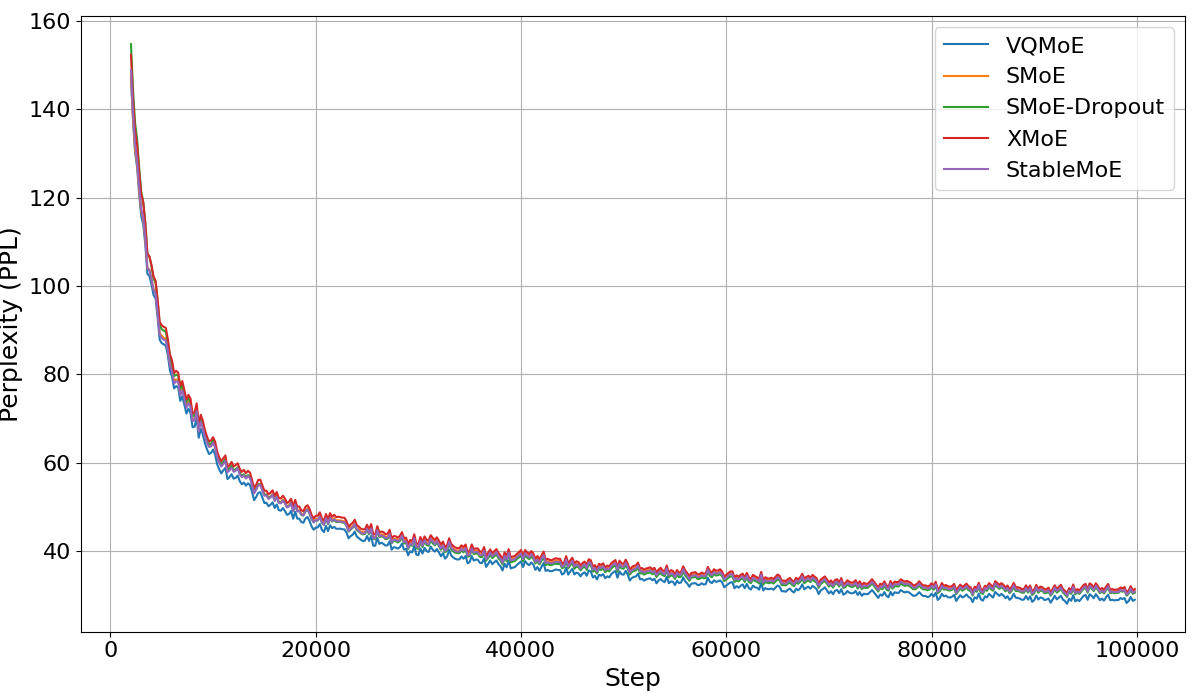
实验结果表明,VQMoE在鲁棒性方面比其他SMoE路由方法提高了28%。此外,VQMoE在大型语言模型和视觉任务的预训练和微调中均取得了良好的性能。这些结果验证了VQMoE在解决路由不一致和表示崩溃问题方面的有效性,并证明了其在扩展模型容量方面的潜力。
🎯 应用场景
VQMoE可应用于各种需要扩展模型容量的场景,如大型语言模型、图像识别、语音识别等。通过有效利用大量专家,VQMoE能够提升模型的性能和泛化能力,尤其是在处理复杂和多样化的数据时。该方法在预训练和微调任务中均表现出色,具有广泛的应用前景。
📄 摘要(原文)
Sparse mixture of experts (SMoE) is an effective solution for scaling up model capacity without increasing the computational costs. A crucial component of SMoE is the router, responsible for directing the input to relevant experts; however, it also presents a major weakness, leading to routing inconsistencies and representation collapse issues. Instead of fixing the router like previous works, we propose an alternative that assigns experts to input via indirection, which employs the discrete representation of input that points to the expert. The discrete representations are learnt via vector quantization, resulting in a new architecture dubbed Vector-Quantized Mixture of Experts (VQMoE). We provide theoretical support and empirical evidence demonstrating the VQMoE's ability to overcome the challenges present in traditional routers. Through extensive evaluations on both large language models and vision tasks for pre-training and fine-tuning, we show that VQMoE achieves a 28% improvement in robustness compared to other SMoE routing methods, while maintaining strong performance in fine-tuning tasks.