Puzzle: Distillation-Based NAS for Inference-Optimized LLMs
作者: Akhiad Bercovich, Tomer Ronen, Talor Abramovich, Nir Ailon, Nave Assaf, Mohammad Dabbah, Ido Galil, Amnon Geifman, Yonatan Geifman, Izhak Golan, Netanel Haber, Ehud Karpas, Roi Koren, Itay Levy, Pavlo Molchanov, Shahar Mor, Zach Moshe, Najeeb Nabwani, Omri Puny, Ran Rubin, Itamar Schen, Ido Shahaf, Oren Tropp, Omer Ullman Argov, Ran Zilberstein, Ran El-Yaniv
分类: cs.LG
发布日期: 2024-11-28 (更新: 2025-06-03)
💡 一句话要点
Puzzle:基于蒸馏的NAS优化LLM推理,实现单H100 GPU部署
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 神经架构搜索 知识蒸馏 硬件感知 推理优化
📋 核心要点
- 现有LLM推理成本高昂,限制了其广泛应用,单纯增加参数虽能提升精度,但部署难度也随之增加。
- Puzzle框架通过硬件感知的神经架构搜索和块状局部知识蒸馏,在保持模型能力的同时,显著加速LLM推理。
- 实验表明,优化后的模型在单H100 GPU上实现了2.17倍的推理加速,同时保留了98.4%的原始模型精度。
📝 摘要(中文)
大型语言模型(LLMs)功能强大,但其高昂的推理成本限制了更广泛的应用。增加参数数量虽然提高了准确性,但也扩大了最先进能力与实际可部署性之间的差距。我们提出了Puzzle,这是一个硬件感知的框架,可以加速LLMs的推理,同时保留其能力。通过大规模的神经架构搜索(NAS),Puzzle优化了具有数百亿参数的模型。我们的方法利用块状局部知识蒸馏(BLD)进行并行架构探索,并采用混合整数规划进行精确的约束优化。我们通过Llama-3.1-Nemotron-51B-Instruct (Nemotron-51B) 和 Llama-3.3-Nemotron-49B展示了我们框架的影响,这两个公开可用的模型都源自Llama-70B-Instruct。这两个模型都实现了2.17倍的推理吞吐量加速,适合单个NVIDIA H100 GPU,同时保留了原始模型98.4%的基准精度。尽管最多在45B tokens上进行训练,远少于训练Llama-70B所用的15T,但这些模型是支持大批量单H100 GPU推理的最准确模型。最后,我们表明,对这些派生模型进行轻量级对齐可以使它们在特定能力上超越父模型。我们的工作表明,强大的LLM模型可以被优化以实现高效部署,而质量损失可以忽略不计,这强调了推理性能,而不仅仅是参数数量,应该指导模型选择。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)推理成本高昂,难以高效部署的问题。现有方法通常侧重于增加模型参数以提高准确性,但忽略了推理效率,导致模型难以在资源受限的硬件上运行。因此,如何在保持模型性能的同时,降低推理成本,是本研究要解决的关键问题。
核心思路:论文的核心思路是利用神经架构搜索(NAS)和知识蒸馏,自动搜索并优化LLM的架构,使其在特定硬件上实现更高的推理效率。通过硬件感知的NAS,可以找到在给定硬件约束下性能最佳的模型结构。知识蒸馏则用于将大型模型的知识迁移到小型模型,从而在减少模型大小的同时,尽可能保留原始模型的性能。
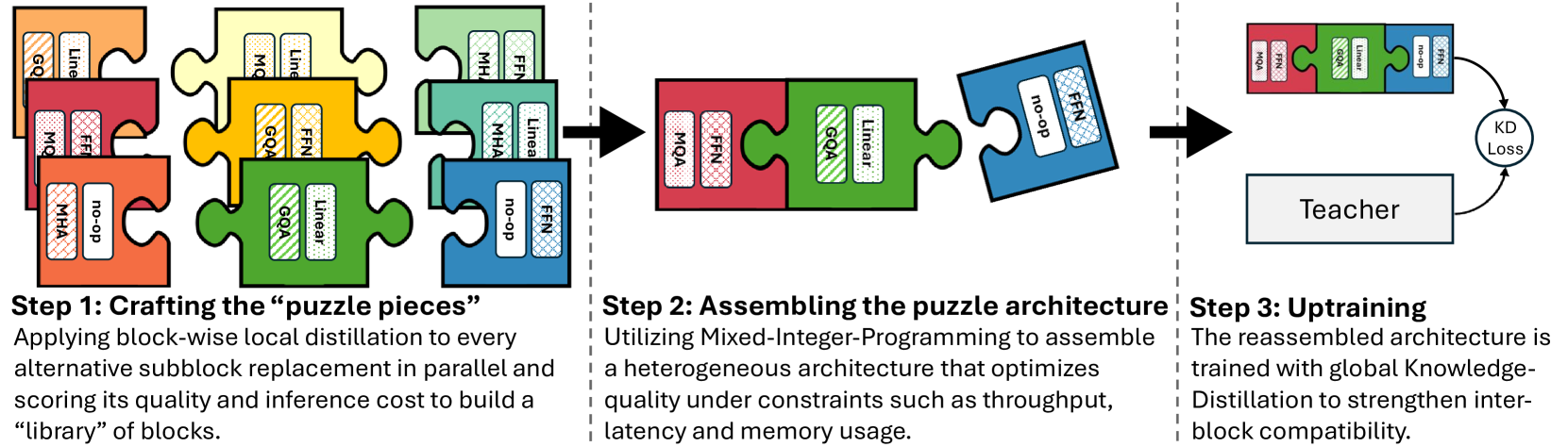
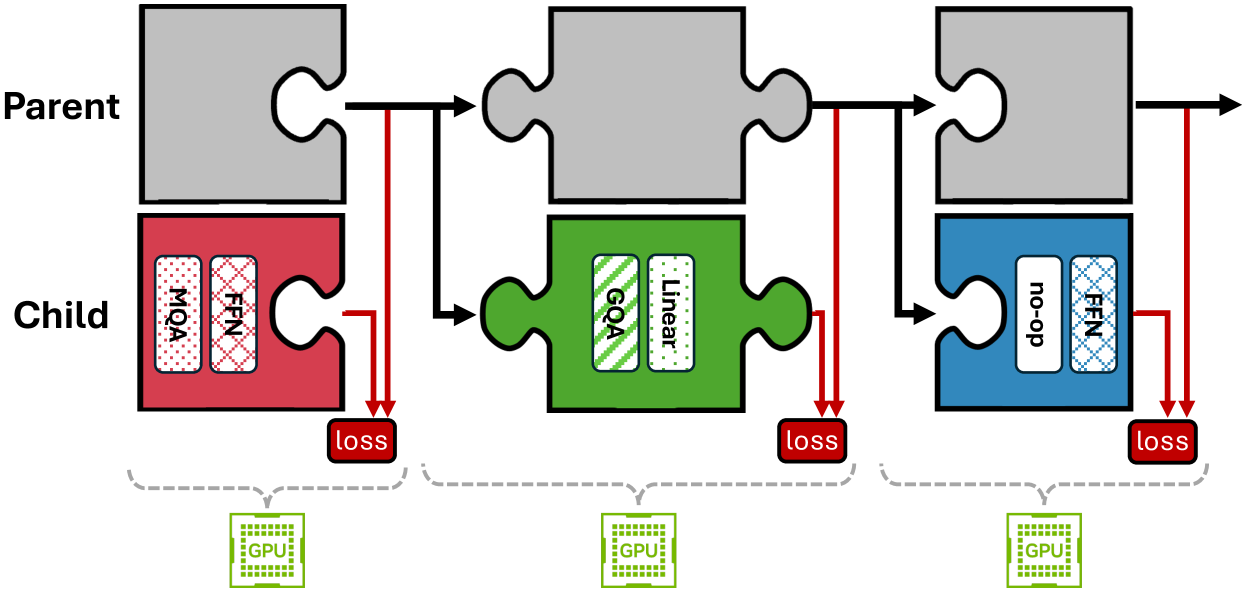
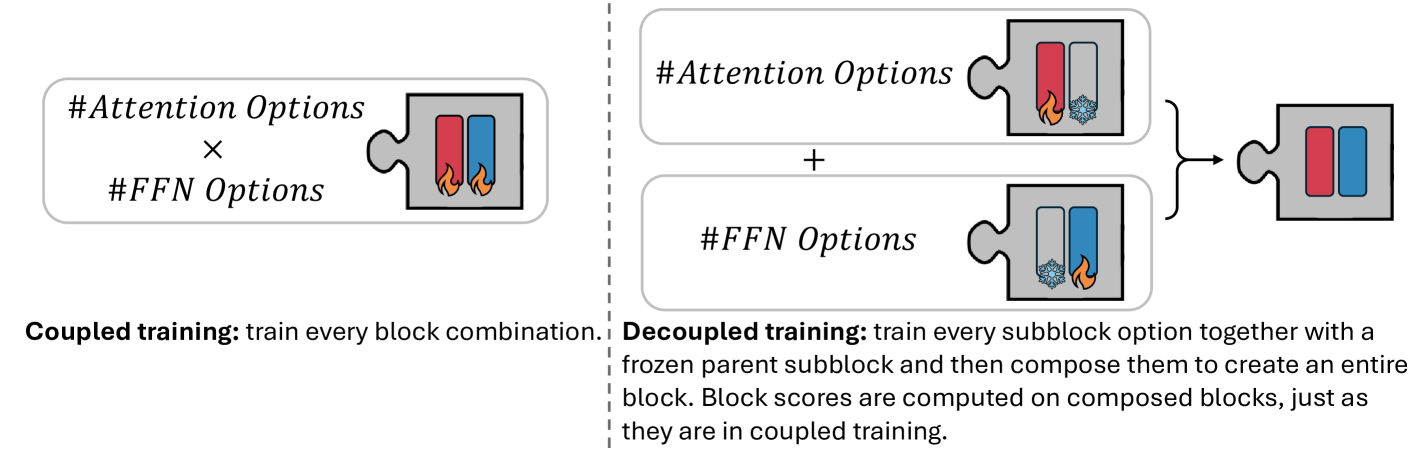
技术框架:Puzzle框架包含以下主要模块:1) 块状局部知识蒸馏(BLD):将大型模型分解为多个块,并对每个块进行独立的知识蒸馏,从而实现并行架构探索。2) 神经架构搜索(NAS):使用NAS算法搜索每个块的最佳架构,以最大化推理效率和模型性能。3) 混合整数规划(MIP):使用MIP优化模型整体的硬件约束,例如模型大小和内存占用。4) 轻量级对齐:对优化后的模型进行轻量级对齐,以进一步提升其在特定任务上的性能。
关键创新:最重要的技术创新点在于结合了块状局部知识蒸馏和硬件感知的神经架构搜索。传统的知识蒸馏通常针对整个模型进行,而BLD允许对模型的不同部分进行独立优化,从而提高了搜索效率和灵活性。此外,硬件感知的NAS能够直接优化模型在特定硬件上的推理性能,从而更好地满足实际部署的需求。
关键设计:在BLD中,模型被划分为多个块,每个块包含多个Transformer层。NAS算法搜索每个块中Transformer层的数量、隐藏层大小和注意力头数等参数。损失函数包括知识蒸馏损失(例如,KL散度)和任务相关的损失。混合整数规划用于约束模型的总参数量和内存占用,以确保模型能够在目标硬件上运行。轻量级对齐使用少量数据对模型进行微调,以提升其在特定任务上的性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Puzzle框架能够将Llama-3.1-Nemotron-51B-Instruct和Llama-3.3-Nemotron-49B的推理吞吐量提高2.17倍,同时保留98.4%的原始模型精度。优化后的模型可以在单个NVIDIA H100 GPU上运行,并且在大批量推理场景下表现出色。此外,轻量级对齐能够进一步提升优化后模型在特定任务上的性能,使其超越原始模型。
🎯 应用场景
该研究成果可广泛应用于需要高效LLM推理的场景,例如移动设备上的智能助手、边缘计算设备上的自然语言处理应用、以及对延迟敏感的在线服务。通过优化LLM的推理效率,可以降低部署成本,并使更多用户能够体验到LLM带来的便利。
📄 摘要(原文)
Large language models (LLMs) offer remarkable capabilities, yet their high inference costs restrict wider adoption. While increasing parameter counts improves accuracy, it also broadens the gap between state-of-the-art capabilities and practical deployability. We present Puzzle, a hardware-aware framework that accelerates the inference of LLMs while preserving their capabilities. Using neural architecture search (NAS) at a large-scale, Puzzle optimizes models with tens of billions of parameters. Our approach utilizes blockwise local knowledge distillation (BLD) for parallel architecture exploration and employs mixed-integer programming for precise constraint optimization. We showcase our framework's impact via Llama-3.1-Nemotron-51B-Instruct (Nemotron-51B) and Llama-3.3-Nemotron-49B, two publicly available models derived from Llama-70B-Instruct. Both models achieve a 2.17x inference throughput speedup, fitting on a single NVIDIA H100 GPU while retaining 98.4% of the original model's benchmark accuracies. These are the most accurate models supporting single H100 GPU inference with large batch sizes, despite training on 45B tokens at most, far fewer than the 15T used to train Llama-70B. Lastly, we show that lightweight alignment on these derived models allows them to surpass the parent model in specific capabilities. Our work establishes that powerful LLM models can be optimized for efficient deployment with only negligible loss in quality, underscoring that inference performance, not parameter count alone, should guide model selection.