ICLERB: In-Context Learning Embedding and Reranker Benchmark
作者: Marie Al Ghossein, Emile Contal, Alexandre Robicquet
分类: cs.LG, cs.IR
发布日期: 2024-11-28
💡 一句话要点
提出ICLERB基准测试与RLRAIF算法,优化上下文学习的检索增强生成。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 上下文学习 检索增强生成 强化学习 排序学习 基准测试
📋 核心要点
- 现有检索方法侧重于语义相关性,将检索视为搜索问题,忽略了文档在上下文学习中的实际效用。
- 论文将检索重新定义为推荐问题,目标是选择能最大化LLM在ICL任务中表现的文档。
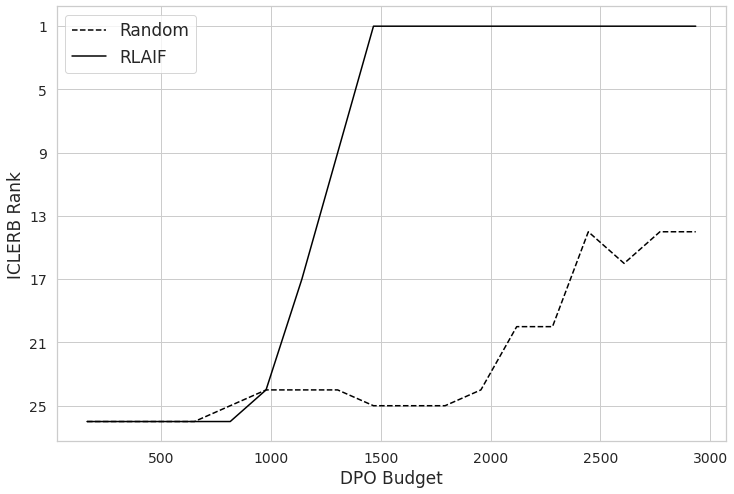
- 提出的ICLERB基准测试和RLRAIF算法,实验证明小模型通过RLRAIF微调后性能超越大型模型。
📝 摘要(中文)
本文针对上下文学习(ICL)中检索增强生成(RAG)的检索问题,提出了一种新的视角,将检索视为推荐问题,旨在选择能够最大化ICL任务效用的文档。为此,我们引入了上下文学习嵌入和重排序基准(ICLERB),这是一个评估检索器在增强LLM在ICL设置中准确性的能力的新框架。此外,我们提出了一种新的基于强化学习的AI反馈排序算法(RLRAIF),旨在利用来自LLM的少量反馈来微调检索模型。实验结果表明,ICLERB与现有基准存在显著差异,并且使用我们的RLRAIF算法微调的小模型优于大型最先进的检索模型。这些发现突出了现有评估方法的局限性,以及针对ICL的专门基准和训练策略的需求。
🔬 方法详解
问题定义:现有检索方法主要关注语义相关性,即检索与查询在语义上最相关的文档。然而,在上下文学习(ICL)场景下,仅仅语义相关并不足以保证检索到的文档能够有效提升大型语言模型(LLM)的性能。现有方法缺乏对检索文档在ICL任务中实际效用的评估和优化。
核心思路:论文的核心思路是将检索问题重新定义为推荐问题。不再仅仅关注文档与查询的语义相关性,而是关注检索到的文档能否最大化LLM在ICL任务中的表现。这意味着需要学习一种能够预测文档在特定ICL任务中效用的检索策略。
技术框架:整体框架包含两个主要部分:ICLERB基准测试和RLRAIF算法。ICLERB用于评估不同的检索器在ICL任务中的表现,提供了一个标准化的评估平台。RLRAIF算法则是一种利用强化学习来微调检索模型的方法,其目标是最大化LLM在ICL任务中的准确率。该算法使用LLM的反馈作为奖励信号,指导检索模型的训练。
关键创新:最重要的技术创新点在于将检索问题重新定义为推荐问题,并提出了相应的RLRAIF算法。与传统的基于语义相关性的检索方法不同,RLRAIF算法直接优化检索器在ICL任务中的表现,从而能够更好地适应ICL场景的需求。
关键设计:RLRAIF算法的关键设计包括:(1) 使用LLM的输出作为奖励信号,直接评估检索到的文档对LLM性能的影响;(2) 使用强化学习算法(具体算法未知)来优化检索模型的参数,使其能够更好地选择能够提升LLM性能的文档;(3) 设计了一种高效的训练策略,能够利用少量的LLM反馈来快速微调检索模型。具体参数设置和网络结构等细节未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,提出的ICLERB基准测试能够有效区分不同检索器在ICL任务中的表现。更重要的是,使用RLRAIF算法微调的小型检索模型,在ICLERB基准测试上超越了大型最先进的检索模型。这表明,针对ICL任务进行专门优化可以显著提升检索性能,即使是小型模型也能取得优异表现。具体性能提升数据未知。
🎯 应用场景
该研究成果可应用于各种需要利用大型语言模型进行上下文学习的场景,例如问答系统、文本摘要、代码生成等。通过优化检索策略,可以显著提升LLM在这些任务中的性能,提高用户体验。未来,该方法有望推广到更多复杂的ICL任务中,并与其他技术相结合,进一步提升LLM的应用价值。
📄 摘要(原文)
In-Context Learning (ICL) enables Large Language Models (LLMs) to perform new tasks by conditioning on prompts with relevant information. Retrieval-Augmented Generation (RAG) enhances ICL by incorporating retrieved documents into the LLM's context at query time. However, traditional retrieval methods focus on semantic relevance, treating retrieval as a search problem. In this paper, we propose reframing retrieval for ICL as a recommendation problem, aiming to select documents that maximize utility in ICL tasks. We introduce the In-Context Learning Embedding and Reranker Benchmark (ICLERB), a novel evaluation framework that compares retrievers based on their ability to enhance LLM accuracy in ICL settings. Additionally, we propose a novel Reinforcement Learning-to-Rank from AI Feedback (RLRAIF) algorithm, designed to fine-tune retrieval models using minimal feedback from the LLM. Our experimental results reveal notable differences between ICLERB and existing benchmarks, and demonstrate that small models fine-tuned with our RLRAIF algorithm outperform large state-of-the-art retrieval models. These findings highlight the limitations of existing evaluation methods and the need for specialized benchmarks and training strategies adapted to ICL.