Multi-Label Contrastive Learning : A Comprehensive Study
作者: Alexandre Audibert, Aurélien Gauffre, Massih-Reza Amini
分类: cs.LG
发布日期: 2024-11-27 (更新: 2025-01-03)
备注: 28 pages, 1 figure
💡 一句话要点
多标签对比学习的综合研究:探索损失函数设计与优化方案
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多标签分类 对比学习 损失函数 深度学习 表示学习
📋 核心要点
- 传统多标签分类损失函数难以捕捉标签间的复杂关系,限制了模型性能。
- 论文研究了将监督对比学习应用于多标签分类,旨在学习更具结构的表示空间。
- 实验表明,对比学习的优势不仅在于考虑标签交互,还在于其鲁棒的优化方案。
📝 摘要(中文)
多标签分类在研究和工业界都已成为一个关键领域,因为它具有广泛的应用。设计有效的损失函数对于优化用于此任务的深度神经网络至关重要,因为它们会显著影响模型性能和效率。传统的损失函数通常在标签独立性的假设下最大化似然,可能难以捕捉复杂的标签关系。最近的研究转向了监督对比学习,这是一种旨在通过将相似实例拉近并将不相似实例推开来创建结构化表示空间的方法。虽然对比学习提供了一种有前途的方法,但将其应用于多标签分类提出了独特的挑战,尤其是在管理标签交互和数据结构方面。本文对不同设置下的多标签分类对比学习损失进行了深入研究,包括标签数量或大或小的数据集,训练数据量不同的数据集,以及计算机视觉和自然语言处理中的应用。
🔬 方法详解
问题定义:多标签分类旨在为一个输入样本分配多个标签。现有方法,特别是基于最大似然估计的方法,通常假设标签之间相互独立,忽略了标签之间的相关性,导致模型无法充分利用标签信息。此外,传统损失函数在处理标签数量较少的数据集时,性能往往不佳。
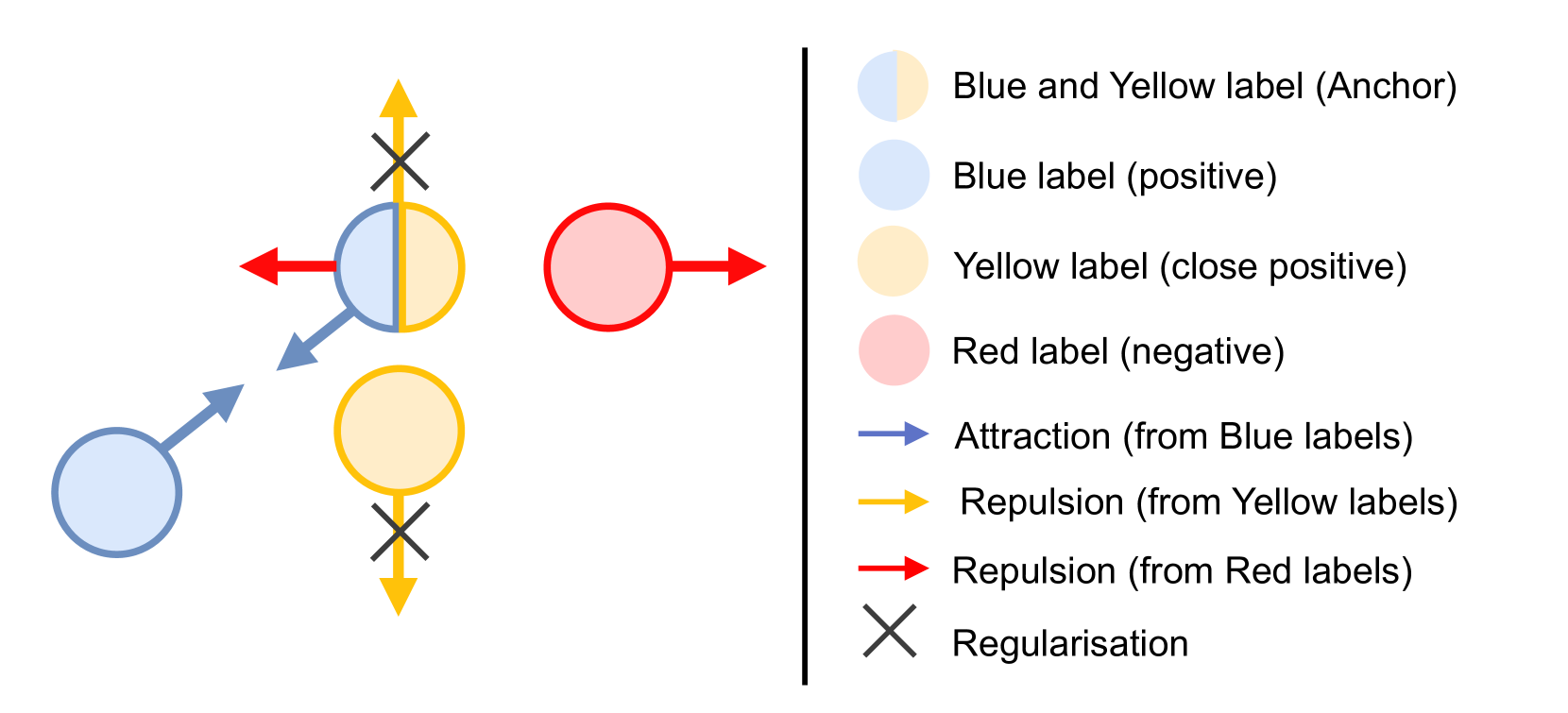
核心思路:论文的核心思路是利用对比学习来学习更具区分性的多标签表示。通过将具有相同标签的样本拉近,将具有不同标签的样本推远,从而在表示空间中建立标签之间的关系,克服了传统方法中标签独立性假设的局限性。对比学习的优化方案也更加鲁棒,有助于提升模型泛化能力。
技术框架:该研究主要关注不同对比学习损失函数在多标签分类任务中的应用。整体框架包括:1) 使用深度神经网络提取输入样本的特征表示;2) 利用对比学习损失函数,基于样本的标签信息,优化特征表示空间;3) 使用优化后的特征表示进行多标签分类。研究中考察了多种对比学习损失函数,并分析了它们在不同数据集上的表现。
关键创新:论文的关键创新在于对对比学习在多标签分类中的应用进行了全面的评估和分析。它不仅验证了对比学习在多标签分类中的有效性,还深入探讨了不同对比学习损失函数在不同数据集上的表现差异,为多标签分类任务中对比学习损失函数的选择提供了指导。
关键设计:论文研究了多种对比学习损失函数,包括但不限于:监督对比损失(Supervised Contrastive Loss)。关键设计在于如何有效地利用标签信息来构建正负样本对。例如,对于一个样本,具有相同标签的样本被认为是正样本,而具有不同标签的样本被认为是负样本。损失函数的具体形式会影响模型的学习效果,需要根据具体任务进行调整。
🖼️ 关键图片
📊 实验亮点
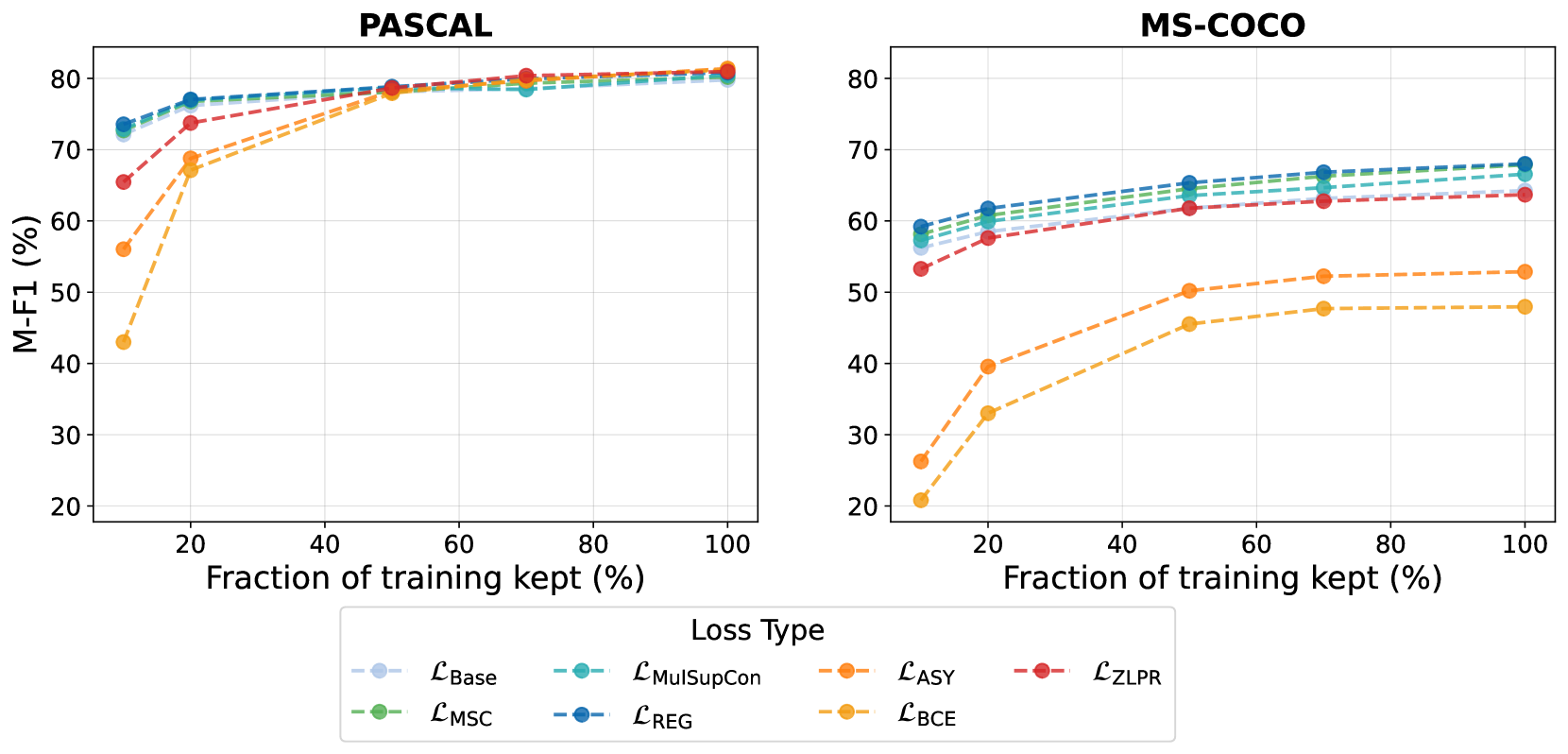
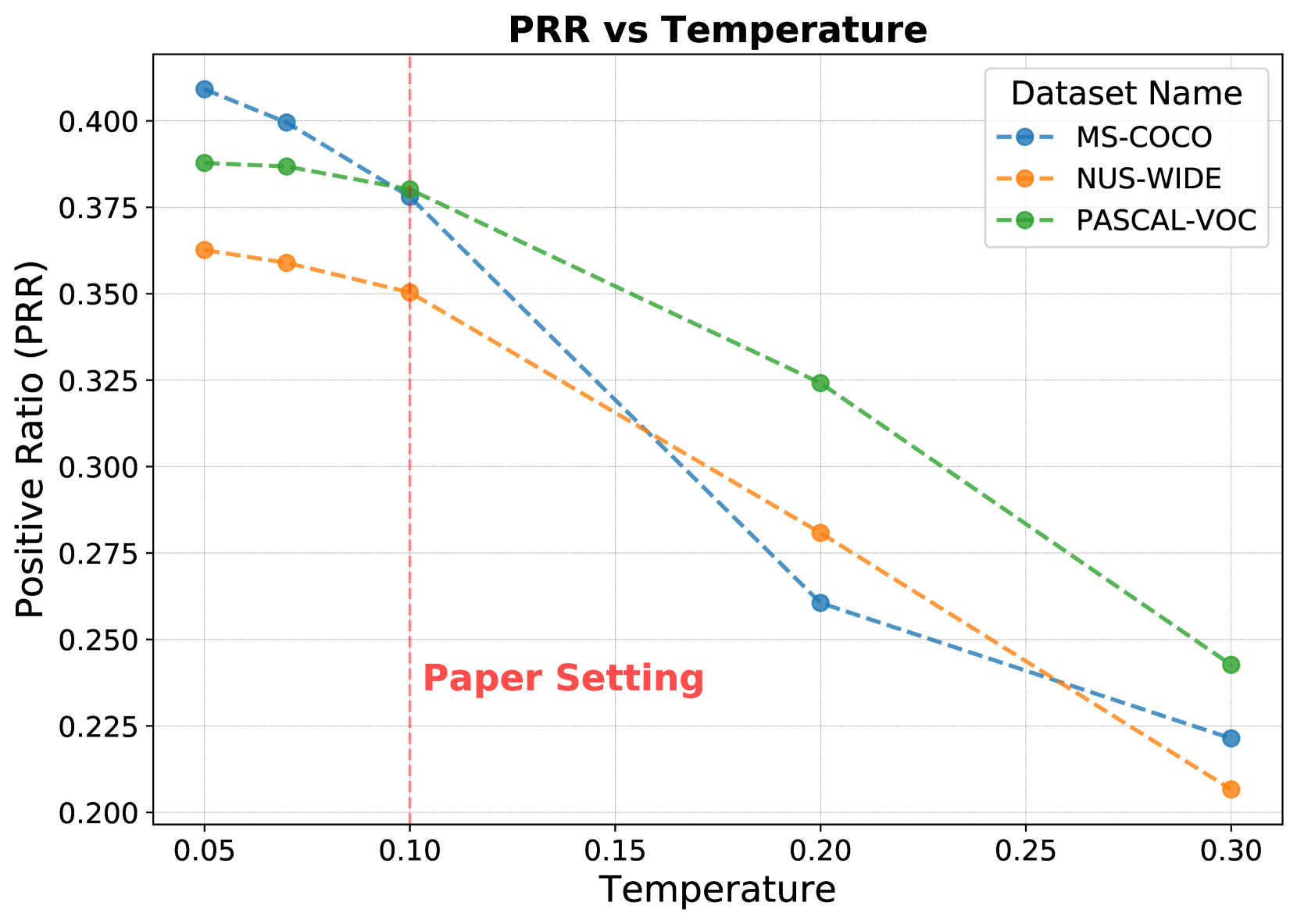
实验结果表明,对比学习方法在多标签分类任务中表现出色,尤其是在标签数量较多的数据集上,Macro-F1指标显著提升。研究发现,对比学习的优势不仅在于考虑了标签之间的关系,还在于其鲁棒的优化方案。然而,在标签数量较少的数据集上,对比学习方法在基于排序的指标上表现不佳。
🎯 应用场景
该研究成果可广泛应用于图像识别、文本分类、生物信息学等领域。例如,在图像识别中,可以用于识别包含多个物体的图像;在文本分类中,可以用于对文档进行多主题分类;在生物信息学中,可以用于预测基因的功能。该研究有助于提升多标签分类模型的性能,从而提高相关应用的准确性和可靠性。
📄 摘要(原文)
Multi-label classification, which involves assigning multiple labels to a single input, has emerged as a key area in both research and industry due to its wide-ranging applications. Designing effective loss functions is crucial for optimizing deep neural networks for this task, as they significantly influence model performance and efficiency. Traditional loss functions, which often maximize likelihood under the assumption of label independence, may struggle to capture complex label relationships. Recent research has turned to supervised contrastive learning, a method that aims to create a structured representation space by bringing similar instances closer together and pushing dissimilar ones apart. Although contrastive learning offers a promising approach, applying it to multi-label classification presents unique challenges, particularly in managing label interactions and data structure. In this paper, we conduct an in-depth study of contrastive learning loss for multi-label classification across diverse settings. These include datasets with both small and large numbers of labels, datasets with varying amounts of training data, and applications in both computer vision and natural language processing. Our empirical results indicate that the promising outcomes of contrastive learning are attributable not only to the consideration of label interactions but also to the robust optimization scheme of the contrastive loss. Furthermore, while the supervised contrastive loss function faces challenges with datasets containing a small number of labels and ranking-based metrics, it demonstrates excellent performance, particularly in terms of Macro-F1, on datasets with a large number of labels.