Energy-Efficient Split Learning for Fine-Tuning Large Language Models in Edge Networks
作者: Zuguang Li, Shaohua Wu, Liang Li, Songge Zhang
分类: cs.LG, cs.CL, cs.DC
发布日期: 2024-11-27 (更新: 2025-01-14)
备注: 5 pages, 6 figures
💡 一句话要点
提出一种节能的分割学习框架,用于在边缘网络中微调大型语言模型。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 分割学习 边缘计算 大型语言模型 模型微调 资源分配
📋 核心要点
- 现有边缘计算场景下微调LLM面临设备异构和信道动态带来的训练延迟和能耗挑战。
- 提出一种分割学习框架,通过优化模型分割点和资源分配,降低训练延迟和能耗。
- CARD算法在仿真中验证了有效性,显著降低了训练延迟和服务器能耗。
📝 摘要(中文)
本文提出了一种节能的分割学习(SL)框架,用于在网络边缘使用地理分布式个人数据微调大型语言模型(LLM)。该框架将LLM分割并在海量移动设备和边缘服务器之间交替部署。考虑到边缘网络中设备异构性和信道动态性,开发了一种切割层和计算资源决策(CARD)算法,以最小化训练延迟和能量消耗。仿真结果表明,与基准方法相比,所提出的方法分别降低了平均训练延迟和服务器的能量消耗70.8%和53.1%。
🔬 方法详解
问题定义:论文旨在解决边缘网络中,由于设备异构性和信道动态性,使用分割学习微调大型语言模型时,训练延迟高和能量消耗大的问题。现有方法没有充分考虑这些因素,导致效率低下。
核心思路:论文的核心思路是根据设备的计算能力和信道状况,动态地决定模型分割的位置(Cut Layer),并合理分配计算资源,从而在保证模型微调效果的同时,最小化训练延迟和能量消耗。
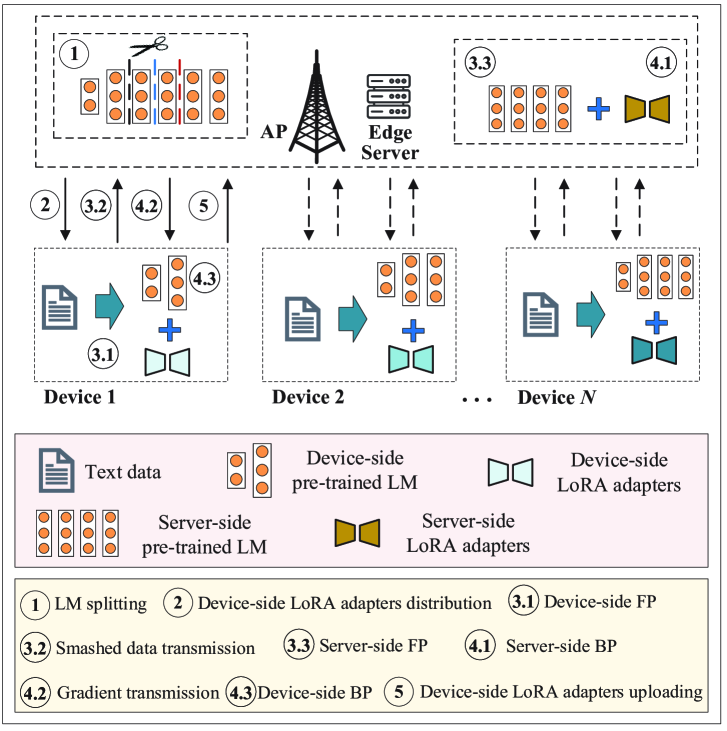
技术框架:该框架包含多个移动设备和一个边缘服务器。LLM被分割成两部分,一部分部署在移动设备上,另一部分部署在边缘服务器上。移动设备使用本地数据进行前向传播,并将中间结果发送到边缘服务器。边缘服务器完成剩余的前向传播和反向传播,并将梯度发送回移动设备。移动设备根据梯度更新模型参数。CARD算法用于决定最佳分割层和计算资源分配。
关键创新:关键创新在于CARD算法,它是一种联合优化模型分割层和计算资源分配的算法。该算法能够根据设备的计算能力和信道状况,动态地调整模型分割的位置,从而实现训练延迟和能量消耗的最小化。
关键设计:CARD算法的关键设计包括:1) 考虑设备异构性和信道动态性的延迟和能量消耗模型;2) 基于该模型,设计了一种启发式搜索算法,用于寻找最佳的分割层和计算资源分配方案;3) 目标函数是最小化训练延迟和服务器能量消耗的加权和。
🖼️ 关键图片

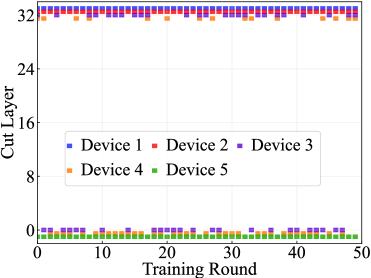
📊 实验亮点
仿真结果表明,与基准方法相比,所提出的CARD算法能够显著降低平均训练延迟和服务器的能量消耗。具体而言,平均训练延迟降低了70.8%,服务器的能量消耗降低了53.1%。这些结果验证了该方法在边缘网络中微调LLM的有效性和节能性。
🎯 应用场景
该研究成果可应用于各种边缘计算场景,例如智能家居、自动驾驶、物联网等,在这些场景中,需要在边缘设备上对大型语言模型进行个性化定制。通过降低训练延迟和能量消耗,该方法可以促进LLM在资源受限的边缘设备上的广泛应用,并提升用户体验。
📄 摘要(原文)
In this letter, we propose an energy-efficient split learning (SL) framework for fine-tuning large language models (LLMs) using geo-distributed personal data at the network edge, where LLMs are split and alternately across massive mobile devices and an edge server. Considering the device heterogeneity and channel dynamics in edge networks, a \underline{C}ut l\underline{A}yer and computing \underline{R}esource \underline{D}ecision (CARD) algorithm is developed to minimize training delay and energy consumption. Simulation results demonstrate that the proposed approach reduces the average training delay and server's energy consumption by 70.8% and 53.1%, compared to the benchmarks, respectively.