Dynamic Logistic Ensembles with Recursive Probability and Automatic Subset Splitting for Enhanced Binary Classification
作者: Mohammad Zubair Khan, David Li
分类: cs.LG, cs.AI
发布日期: 2024-11-27
备注: 8 Pages, 2024 IEEE 15th Annual Ubiquitous Computing, Electronics \& Mobile Communication Conference (UEMCON)}. Published in the Proceedings of UEMCON 2024, \c{opyright}2024 IEEE
DOI: 10.1109/UEMCON62879.2024.10754761
🔗 代码/项目: GITHUB
💡 一句话要点
提出动态Logistic集成模型,通过递归概率和自动子集划分增强二分类性能
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 动态集成 Logistic回归 二分类 递归概率 自动子集划分 机器学习 模型可解释性
📋 核心要点
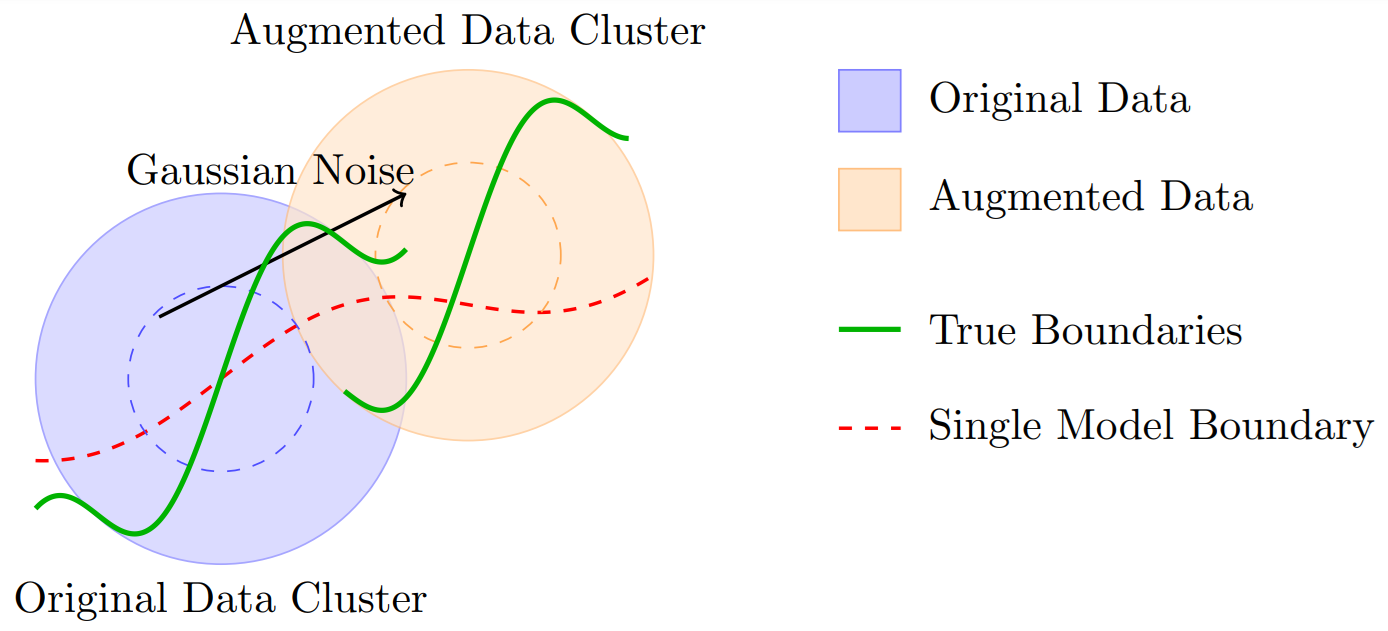
- 现有二分类方法难以有效处理包含内在集群但缺乏显式特征分离的数据集。
- 提出动态Logistic集成模型,通过递归概率计算和自动子集划分构建模型集成。
- 在模拟数据集上验证,结果表明该方法在性能上优于传统集成方法,并保持了模型的可解释性。
📝 摘要(中文)
本文提出了一种使用动态Logistic集成模型进行二分类的新方法。该方法旨在解决包含缺乏显式特征分离的内在集群的数据集所带来的挑战。通过扩展传统的Logistic回归,我们开发了一种算法,该算法自动将数据集划分为多个子集,构建Logistic模型集成以提高分类精度。这项工作的一个关键创新是递归概率计算,通过代数操作和数学归纳推导得出,从而实现可扩展和高效的模型构建。与Bagging和Boosting等传统集成方法相比,我们的方法在保持可解释性的同时提供了具有竞争力的性能。此外,我们系统地采用最大似然和成本函数来促进递归梯度的分析推导,作为集成深度的函数。该方法在通过引入噪声和移动数据来模拟组结构的自定义数据集上进行了验证,从而在使用层时获得了显著的性能提升。该工作使用Python实现,在计算效率和理论严谨性之间取得了平衡,为复杂的分类任务提供了一个稳健且可解释的解决方案,对机器学习应用具有广泛的意义。
🔬 方法详解
问题定义:论文旨在解决二分类问题中,当数据集包含内在集群且这些集群缺乏明显的特征区分时,传统Logistic回归模型性能下降的问题。现有方法,如单一的Logistic回归模型,无法有效捕捉数据集中不同集群的特性,导致分类精度不高。集成学习方法,如Bagging和Boosting,虽然可以提高性能,但通常牺牲了模型的可解释性。
核心思路:论文的核心思路是将数据集自动划分为多个子集,每个子集训练一个Logistic回归模型,形成一个集成。通过递归地计算每个样本属于不同子集的概率,并利用这些概率对各个模型的预测结果进行加权融合,从而提高分类精度。这种动态集成的方式允许模型根据数据的内在结构进行自适应调整。
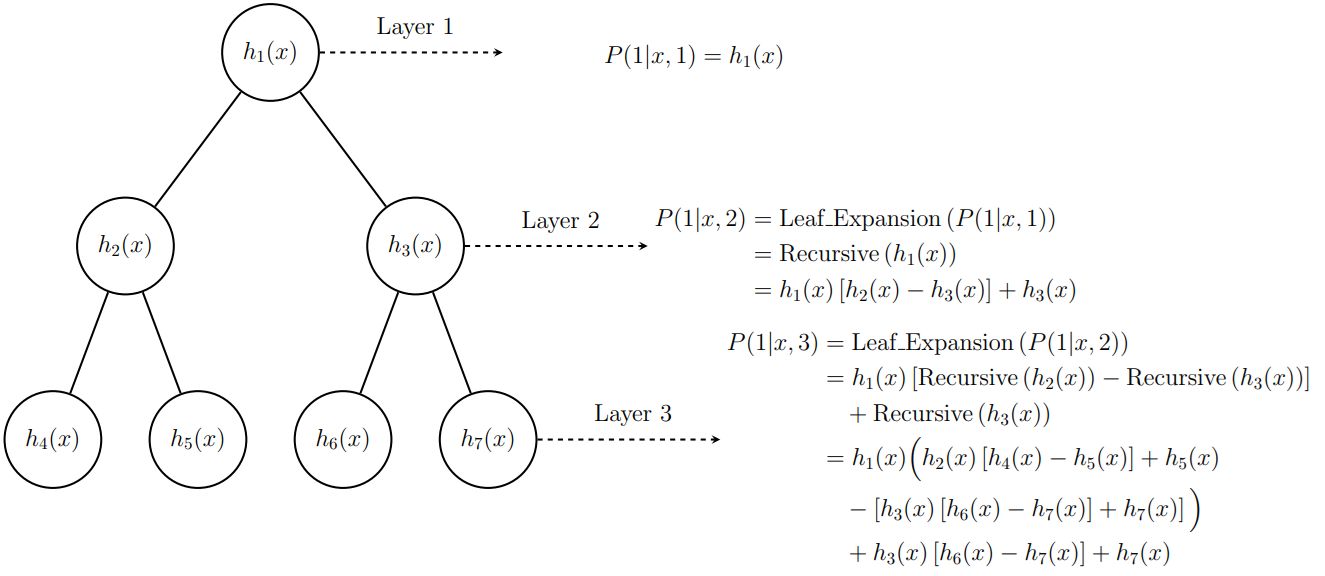
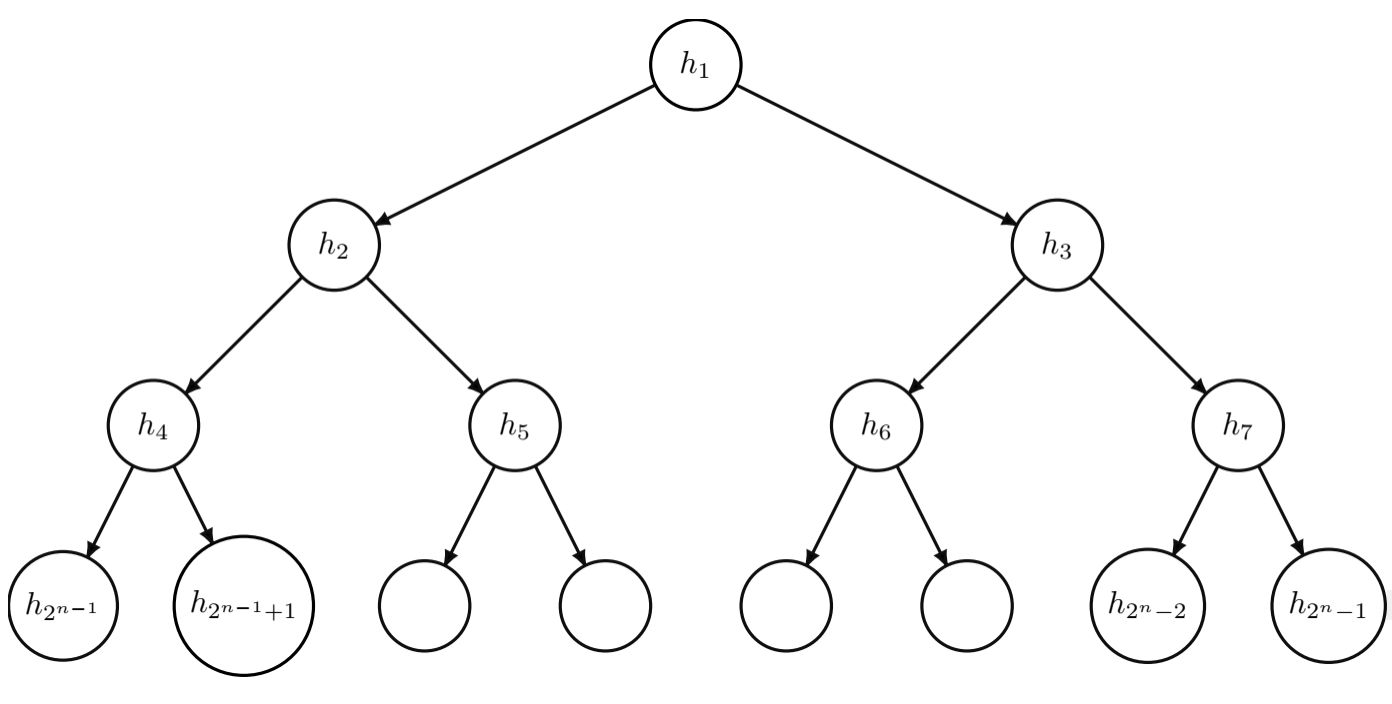
技术框架:该方法主要包含以下几个阶段:1) 数据集自动划分:算法自动将数据集划分为多个子集,每个子集代表一个潜在的集群。2) Logistic模型训练:在每个子集上训练一个Logistic回归模型。3) 递归概率计算:利用代数操作和数学归纳法,递归地计算每个样本属于不同子集的概率。4) 集成预测:将各个Logistic模型的预测结果根据递归概率进行加权融合,得到最终的分类结果。
关键创新:该方法最重要的技术创新点在于递归概率计算。传统的集成方法通常采用固定的权重或基于特征的划分,而该方法通过递归地计算概率,使得每个样本的权重可以根据其在不同子集中的概率动态调整。这种动态调整能够更好地适应数据的内在结构,提高分类精度。此外,该方法还通过最大似然估计和成本函数,推导出递归梯度的解析表达式,从而提高了模型的训练效率。
关键设计:论文采用最大似然估计来训练每个Logistic回归模型,并使用交叉熵损失函数来衡量模型的预测误差。递归概率的计算涉及到一些关键的参数,例如子集划分的阈值和递归的深度。这些参数需要根据具体的数据集进行调整,以达到最佳的性能。此外,论文还详细描述了如何通过代数操作和数学归纳法推导出递归梯度的解析表达式,这对于模型的优化至关重要。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在模拟的具有内在集群结构的数据集上,该方法显著优于传统的Logistic回归模型和一些常用的集成学习方法。通过引入噪声和移动数据来模拟组结构,该方法在分类精度上取得了明显的提升,尤其是在使用多层结构时。具体的性能数据和对比基线在论文中进行了详细的展示。
🎯 应用场景
该研究成果可应用于各种需要处理具有内在集群结构数据的二分类问题,例如:客户行为分析、欺诈检测、医学诊断等。通过自动识别和建模不同的数据子集,该方法能够提高分类精度,并为决策提供更可靠的依据。此外,该方法的可解释性使其在需要理解模型决策过程的场景中具有优势,例如金融风控和医疗诊断。
📄 摘要(原文)
This paper presents a novel approach to binary classification using dynamic logistic ensemble models. The proposed method addresses the challenges posed by datasets containing inherent internal clusters that lack explicit feature-based separations. By extending traditional logistic regression, we develop an algorithm that automatically partitions the dataset into multiple subsets, constructing an ensemble of logistic models to enhance classification accuracy. A key innovation in this work is the recursive probability calculation, derived through algebraic manipulation and mathematical induction, which enables scalable and efficient model construction. Compared to traditional ensemble methods such as Bagging and Boosting, our approach maintains interpretability while offering competitive performance. Furthermore, we systematically employ maximum likelihood and cost functions to facilitate the analytical derivation of recursive gradients as functions of ensemble depth. The effectiveness of the proposed approach is validated on a custom dataset created by introducing noise and shifting data to simulate group structures, resulting in significant performance improvements with layers. Implemented in Python, this work balances computational efficiency with theoretical rigor, providing a robust and interpretable solution for complex classification tasks with broad implications for machine learning applications. Code at https://github.com/ensemble-art/Dynamic-Logistic-Ensembles