FastSwitch: Optimizing Context Switching Efficiency in Fairness-aware Large Language Model Serving
作者: Ao Shen, Zhiyao Li, Mingyu Gao
分类: cs.LG, cs.DC
发布日期: 2024-11-27
💡 一句话要点
FastSwitch:优化公平感知大语言模型服务中的上下文切换效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型服务 上下文切换 公平性调度 KV缓存优化 GPU利用率
📋 核心要点
- 现有LLM服务系统在追求高吞吐量的同时,忽略了抢占式调度带来的上下文切换开销,影响了公平性。
- FastSwitch通过优化KV缓存内存管理,减少I/O传输和GPU空闲,从而降低上下文切换开销。
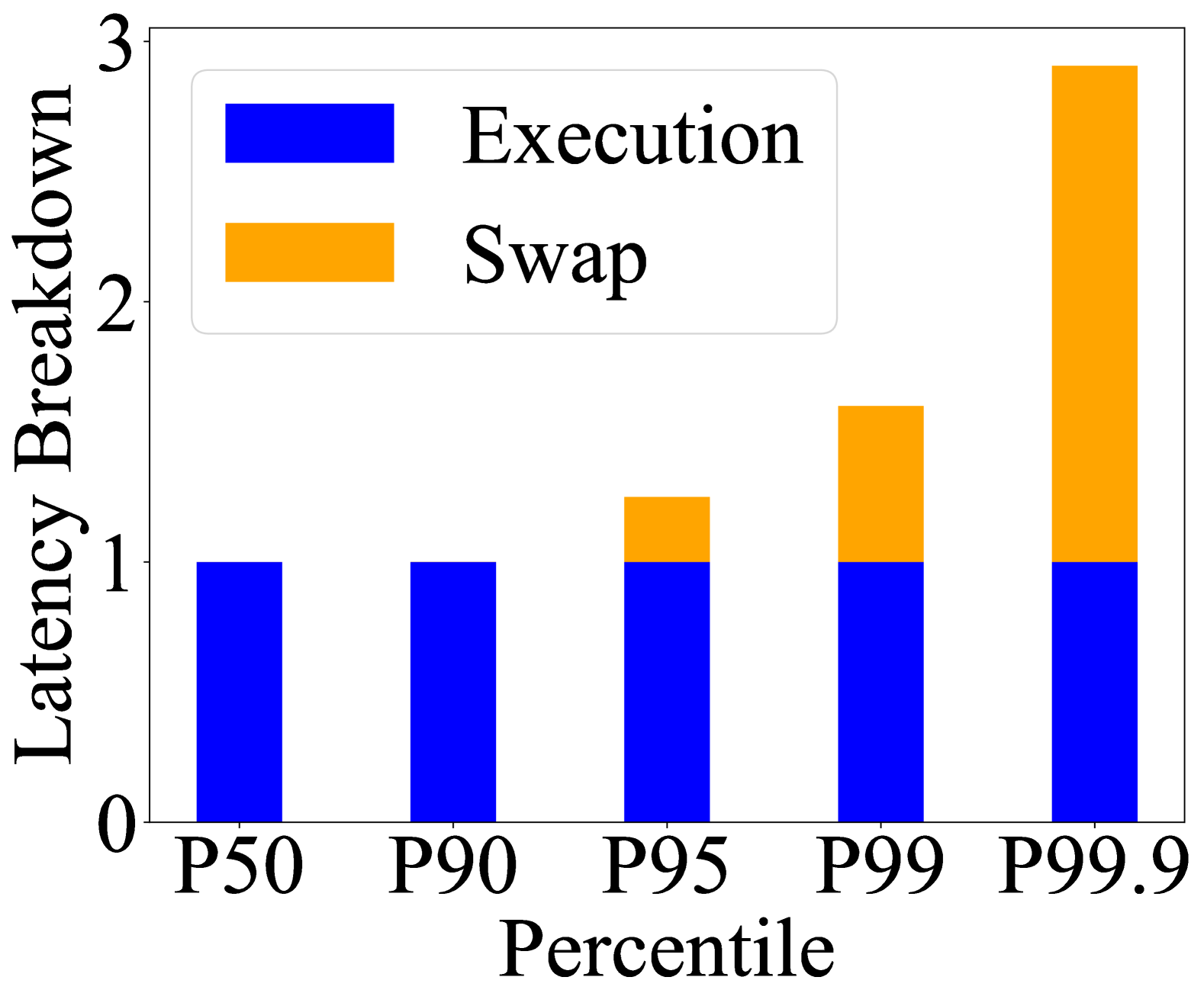
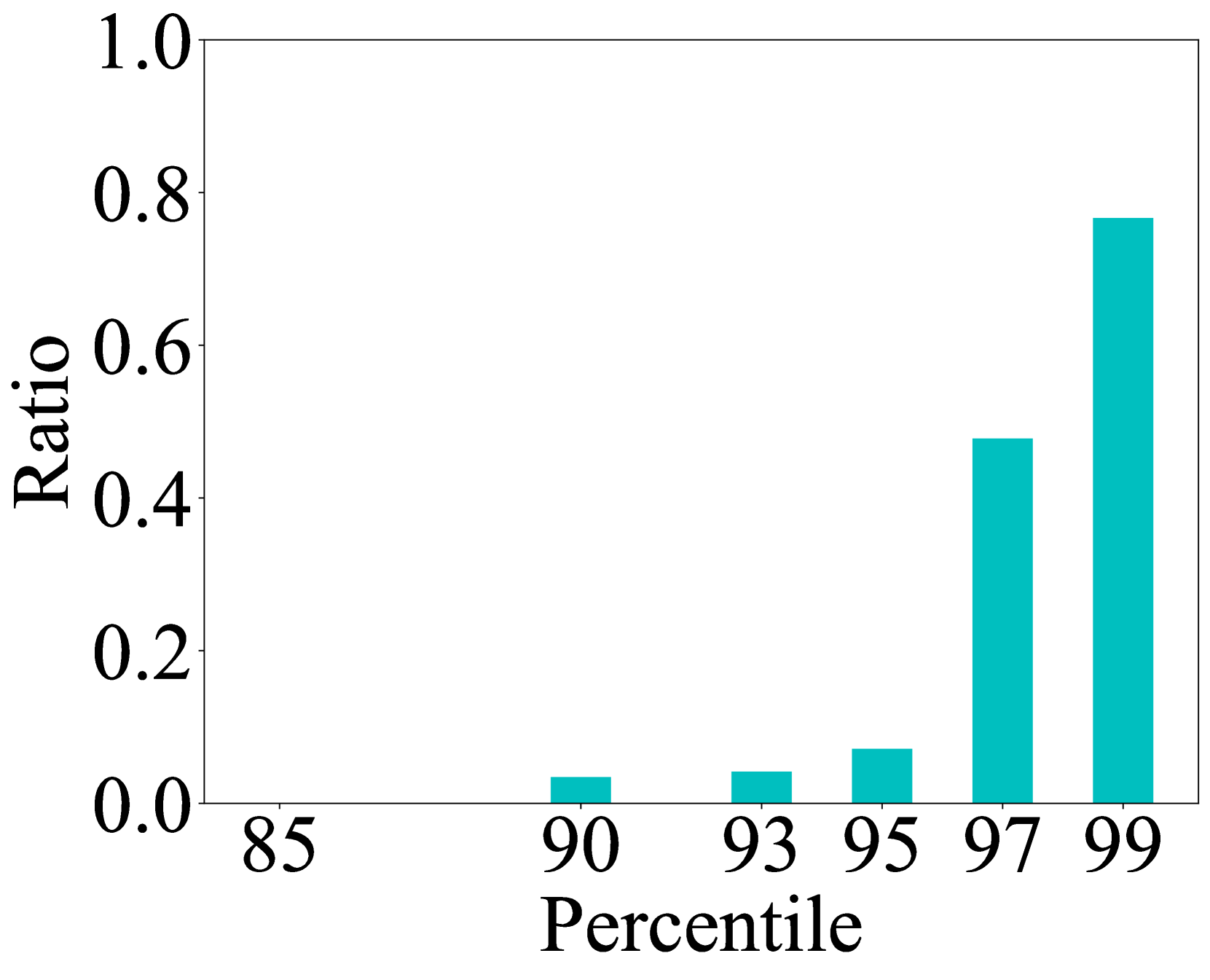
- 实验结果表明,FastSwitch在不同TTFT和TBT指标下,相比vLLM有显著的性能提升,加速比达到1.4-11.2倍。
📝 摘要(中文)
在大语言模型(LLM)服务系统中,同时服务大量用户和请求需要良好的公平性。这确保了在相同成本下,系统能够满足更多用户的服务水平目标(SLO),例如首个token生成时间(TTFT)和token间时间(TBT),而不是让少数用户体验到远超SLO的性能。为了实现更好的公平性,基于抢占的调度策略动态调整每个请求的优先级,以在运行时保持平衡。然而,现有系统往往过度优先考虑吞吐量,而忽略了由抢占引起的上下文切换所带来的开销,这对于通过优先级调整来维持公平性至关重要。本文指出了导致这种开销的三个主要挑战:1) I/O利用率不足;2) GPU空闲;3) 多轮对话期间不必要的I/O传输。我们的关键见解是,现有系统中基于块的KV缓存内存策略虽然实现了接近零的内存浪费,但导致了KV缓存内存的不连续性和粒度不足。为了解决这个问题,我们引入了FastSwitch,一个公平感知服务系统,它不仅与现有的KV缓存内存分配策略保持一致,而且减轻了上下文切换开销。评估表明,FastSwitch在不同的尾部TTFT和TBT下,性能优于最先进的LLM服务系统vLLM,加速比为1.4-11.2倍。
🔬 方法详解
问题定义:论文旨在解决在公平感知的大语言模型服务中,由于频繁的上下文切换导致的性能瓶颈问题。现有方法,如vLLM,虽然在吞吐量上表现良好,但基于抢占的调度策略引入了大量的上下文切换开销,尤其是在I/O利用率、GPU空闲和多轮对话的KV缓存管理方面存在不足,从而影响了整体的公平性和效率。
核心思路:FastSwitch的核心思路是通过优化KV缓存的内存管理策略,减少不必要的I/O传输和GPU空闲时间,从而降低上下文切换的开销。它旨在与现有的KV缓存内存分配策略兼容,同时解决其固有的不连续性和粒度不足的问题。
技术框架:FastSwitch的整体框架围绕着优化KV缓存管理展开。它主要包含以下几个关键模块:优化的KV缓存分配器,用于减少内存碎片和提高缓存命中率;智能的I/O调度器,用于减少不必要的I/O传输;以及自适应的上下文切换策略,用于最小化GPU空闲时间。这些模块协同工作,以实现更高效和公平的LLM服务。
关键创新:FastSwitch最重要的技术创新在于其对KV缓存内存管理策略的优化,它在保持与现有块状分配策略兼容的同时,通过更细粒度的管理和智能的调度,显著减少了上下文切换的开销。与现有方法相比,FastSwitch更注重在保证公平性的前提下,提升整体的服务效率。
关键设计:FastSwitch的关键设计包括:1) 细粒度的KV缓存块管理,允许更灵活的内存分配和回收;2) 基于请求优先级的I/O调度策略,优先处理高优先级请求的I/O操作;3) 动态调整的上下文切换阈值,根据系统负载和请求特性,自适应地调整切换频率,以最小化GPU空闲时间。
🖼️ 关键图片

📊 实验亮点
实验结果表明,FastSwitch在不同的尾部TTFT和TBT指标下,性能优于最先进的LLM服务系统vLLM,加速比为1.4-11.2倍。这意味着FastSwitch能够显著降低延迟,提高吞吐量,并更好地满足用户的服务水平目标。这些实验结果充分验证了FastSwitch在优化上下文切换效率方面的有效性。
🎯 应用场景
FastSwitch适用于需要高并发和公平性保障的大语言模型在线服务场景,例如智能客服、对话式AI助手、在线教育等。通过降低上下文切换开销,FastSwitch可以提升用户体验,降低服务成本,并支持更大规模的用户并发访问。该研究成果对于构建更高效、更公平的AI服务基础设施具有重要意义。
📄 摘要(原文)
Serving numerous users and requests concurrently requires good fairness in Large Language Models (LLMs) serving system. This ensures that, at the same cost, the system can meet the Service Level Objectives (SLOs) of more users , such as time to first token (TTFT) and time between tokens (TBT), rather than allowing a few users to experience performance far exceeding the SLOs. To achieve better fairness, the preemption-based scheduling policy dynamically adjusts the priority of each request to maintain balance during runtime. However, existing systems tend to overly prioritize throughput, overlooking the overhead caused by preemption-induced context switching, which is crucial for maintaining fairness through priority adjustments. In this work, we identify three main challenges that result in this overhead. 1) Inadequate I/O utilization. 2) GPU idleness. 3) Unnecessary I/O transmission during multi-turn conversations. Our key insight is that the block-based KV cache memory policy in existing systems, while achieving near-zero memory waste, leads to discontinuity and insufficient granularity in the KV cache memory. To respond, we introduce FastSwitch, a fairness-aware serving system that not only aligns with existing KV cache memory allocation policy but also mitigates context switching overhead. Our evaluation shows that FastSwitch outperforms the state-of-the-art LLM serving system vLLM with speedups of 1.4-11.2x across different tail TTFT and TBT.