Evaluating and Improving the Robustness of Security Attack Detectors Generated by LLMs
作者: Samuele Pasini, Jinhan Kim, Tommaso Aiello, Rocio Cabrera Lozoya, Antonino Sabetta, Paolo Tonella
分类: cs.SE, cs.CR, cs.LG
发布日期: 2024-11-27 (更新: 2025-09-17)
💡 一句话要点
利用RAG和自排序提升LLM生成安全攻击检测器的鲁棒性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 安全攻击检测 检索增强生成 自排序 跨站脚本 SQL注入 鲁棒性 代码生成
📋 核心要点
- LLM生成的安全攻击检测器面临知识不足的挑战,难以有效应对各种攻击。
- 提出结合RAG和自排序的方法,RAG引入外部知识,自排序选择最鲁棒的检测器。
- 实验表明,该方法显著提升了LLM生成代码检测XSS和SQL注入攻击的性能。
📝 摘要(中文)
大型语言模型(LLMs)越来越多地被应用于软件开发中,用于生成诸如攻击检测器等实现安全需求的功能。一个关键挑战是确保LLMs拥有足够的知识来应对特定的安全需求,例如关于现有攻击的信息。为此,我们提出了一种将检索增强生成(RAG)和自排序(Self-Ranking)集成到LLM流程中的方法。RAG通过整合外部知识源来增强输出的鲁棒性,而自排序技术受到自洽性概念的启发,生成多个推理路径并创建排名以选择最鲁棒的检测器。我们进行了广泛的实证研究,针对由LLMs生成的用于检测Web安全中两种常见注入攻击(跨站脚本XSS和SQL注入SQLi)的代码。结果表明,采用RAG和自排序可以显著提高检测性能,XSS检测的F2-Score提高了高达71个百分点(平均37个百分点),SQLi检测的F2-Score提高了高达43个百分点(平均6个百分点)。
🔬 方法详解
问题定义:论文旨在解决LLM在生成安全攻击检测器时,由于知识储备不足而导致的检测性能不佳的问题。现有的LLM在面对新型或变种攻击时,往往缺乏有效的检测能力,需要人工干预进行改进和更新,效率较低。
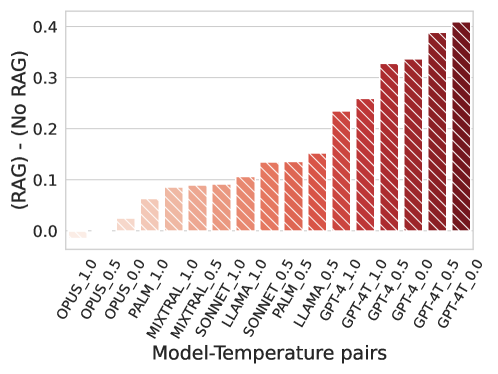
核心思路:论文的核心思路是通过检索增强生成(RAG)为LLM提供外部知识,并利用自排序(Self-Ranking)机制选择最鲁棒的检测器。RAG可以使LLM在生成代码时参考最新的攻击信息和防御策略,而自排序则可以从多个候选检测器中选择泛化能力最强的那个。
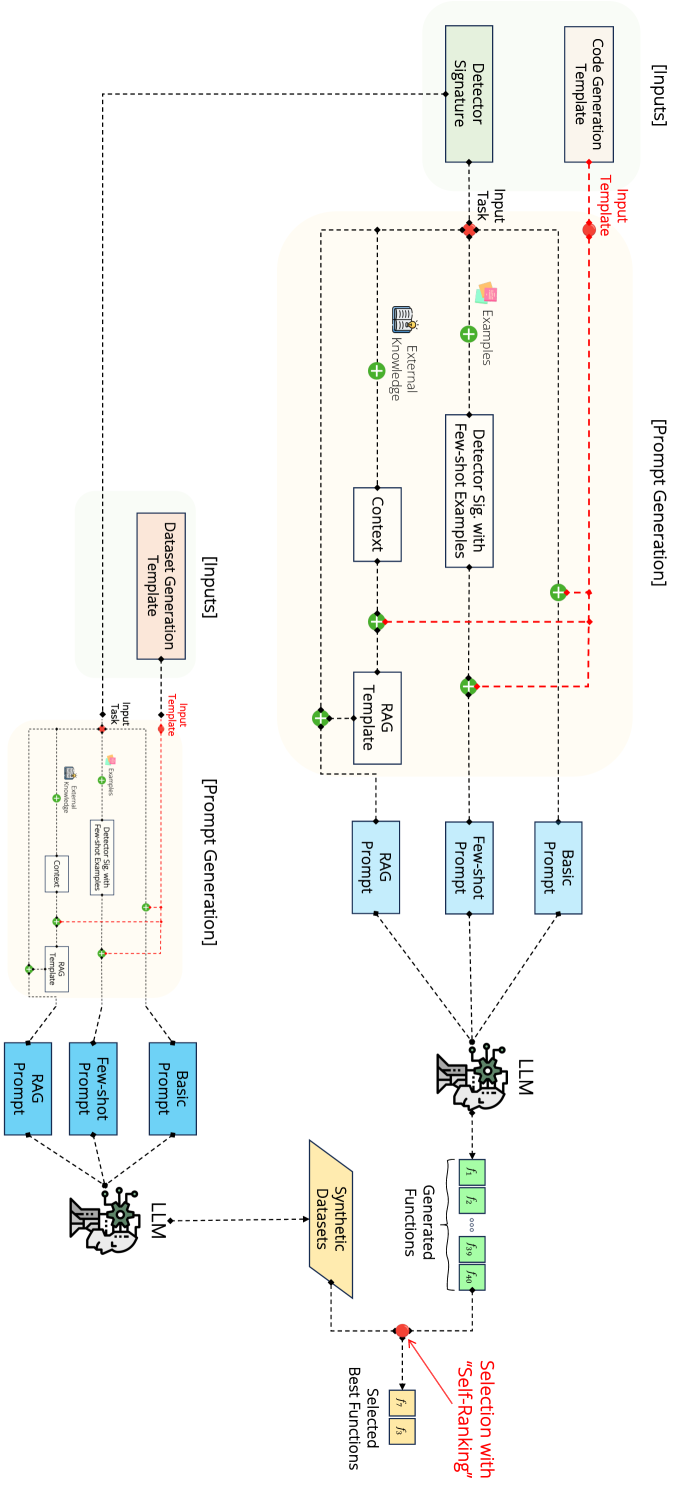
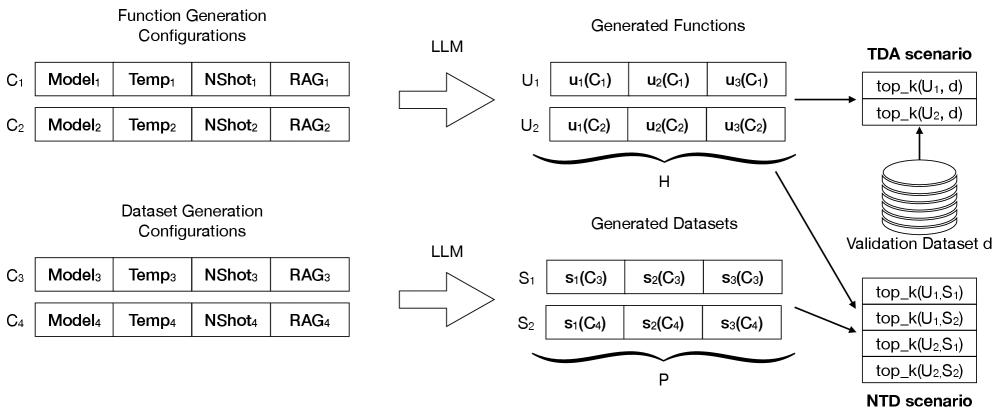
技术框架:整体框架包含三个主要阶段:1) 检索阶段:利用RAG从外部知识库中检索与目标攻击相关的知识;2) 生成阶段:LLM基于检索到的知识生成多个候选攻击检测器;3) 排序阶段:利用自排序机制对候选检测器进行评估和排序,选择最优的检测器。
关键创新:该方法最重要的创新点在于将RAG和自排序相结合,形成一个闭环的LLM安全代码生成流程。RAG弥补了LLM自身知识的不足,而自排序则提高了检测器的鲁棒性和泛化能力。这种结合使得LLM能够自动生成高质量的安全攻击检测器,减少了人工干预。
关键设计:在RAG阶段,需要选择合适的知识库和检索算法,以确保检索到的知识与目标攻击相关且有效。在自排序阶段,需要设计合理的评估指标,例如检测准确率、召回率和F2-Score,以及排序算法,以选择最鲁棒的检测器。论文中使用了F2-Score作为主要评估指标,因为它更侧重于召回率,这在安全检测领域尤为重要。
🖼️ 关键图片
📊 实验亮点
实验结果表明,结合RAG和自排序的方法能够显著提升LLM生成代码检测XSS和SQL注入攻击的性能。对于XSS检测,F2-Score平均提升了37个百分点,最高提升了71个百分点;对于SQL注入检测,F2-Score平均提升了6个百分点,最高提升了43个百分点。这些结果表明,该方法能够有效提高LLM生成安全攻击检测器的鲁棒性。
🎯 应用场景
该研究成果可应用于Web应用防火墙(WAF)、入侵检测系统(IDS)等安全产品中,提升其自动化攻击检测能力。通过自动生成和更新攻击检测规则,可以有效应对新型和变种攻击,降低安全风险。此外,该方法还可用于安全代码审计和漏洞挖掘等领域,辅助安全专家进行安全分析和漏洞修复。
📄 摘要(原文)
Large Language Models (LLMs) are increasingly used in software development to generate functions, such as attack detectors, that implement security requirements. A key challenge is ensuring the LLMs have enough knowledge to address specific security requirements, such as information about existing attacks. For this, we propose an approach integrating Retrieval Augmented Generation (RAG) and Self-Ranking into the LLM pipeline. RAG enhances the robustness of the output by incorporating external knowledge sources, while the Self-Ranking technique, inspired by the concept of Self-Consistency, generates multiple reasoning paths and creates ranks to select the most robust detector. Our extensive empirical study targets code generated by LLMs to detect two prevalent injection attacks in web security: Cross-Site Scripting (XSS) and SQL injection (SQLi). Results show a significant improvement in detection performance while employing RAG and Self-Ranking, with an increase of up to 71%pt (on average 37%pt) and up to 43%pt (on average 6%pt) in the F2-Score for XSS and SQLi detection, respectively.