COAP: Memory-Efficient Training with Correlation-Aware Gradient Projection
作者: Jinqi Xiao, Shen Sang, Tiancheng Zhi, Jing Liu, Qing Yan, Yuqian Zhang, Linjie Luo, Bo Yuan
分类: cs.LG, cs.AI, cs.CL, cs.CV
发布日期: 2024-11-26 (更新: 2025-03-12)
备注: CVPR 2025
💡 一句话要点
COAP:一种相关性感知梯度投影的内存高效训练方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 内存高效训练 梯度投影 相关性感知 低秩优化 大模型微调
📋 核心要点
- 现有低秩梯度投影方法忽略了投影间的相关性,导致性能下降,且投影策略计算成本高昂。
- COAP通过感知相关性的梯度投影,在最小化计算开销的同时,保持训练性能。
- 实验表明,COAP在视觉、语言和多模态任务中,训练速度和模型性能均优于现有方法,并显著降低内存占用。
📝 摘要(中文)
在大规模视觉和多模态领域中训练大型神经网络需要大量的内存资源,这主要是由于优化器状态的存储。LoRA作为一种流行的参数高效方法,虽然降低了内存使用,但由于低秩更新的限制,其性能往往欠佳。低秩梯度投影方法(例如GaLore、Flora)通过奇异值分解或随机投影将梯度和动量估计投影到低秩空间中,从而减少优化器内存。然而,它们未能考虑投影间的相关性,导致性能下降,并且它们的投影策略通常会产生高计算成本。本文提出了一种内存高效的方法COAP(Correlation-Aware Gradient Projection),它在保持训练性能的同时,最大限度地减少了计算开销。在各种视觉、语言和多模态任务中进行评估,COAP在训练速度和模型性能方面均优于现有方法。对于LLaMA-1B,它在仅增加2%时间成本的情况下,将优化器内存减少了61%,实现了与AdamW相同的PPL。通过8位量化,COAP将LLaVA-v1.5-7B微调的优化器内存减少了81%,并实现了比GaLore快4倍的速度,同时提供了更高的准确性。
🔬 方法详解
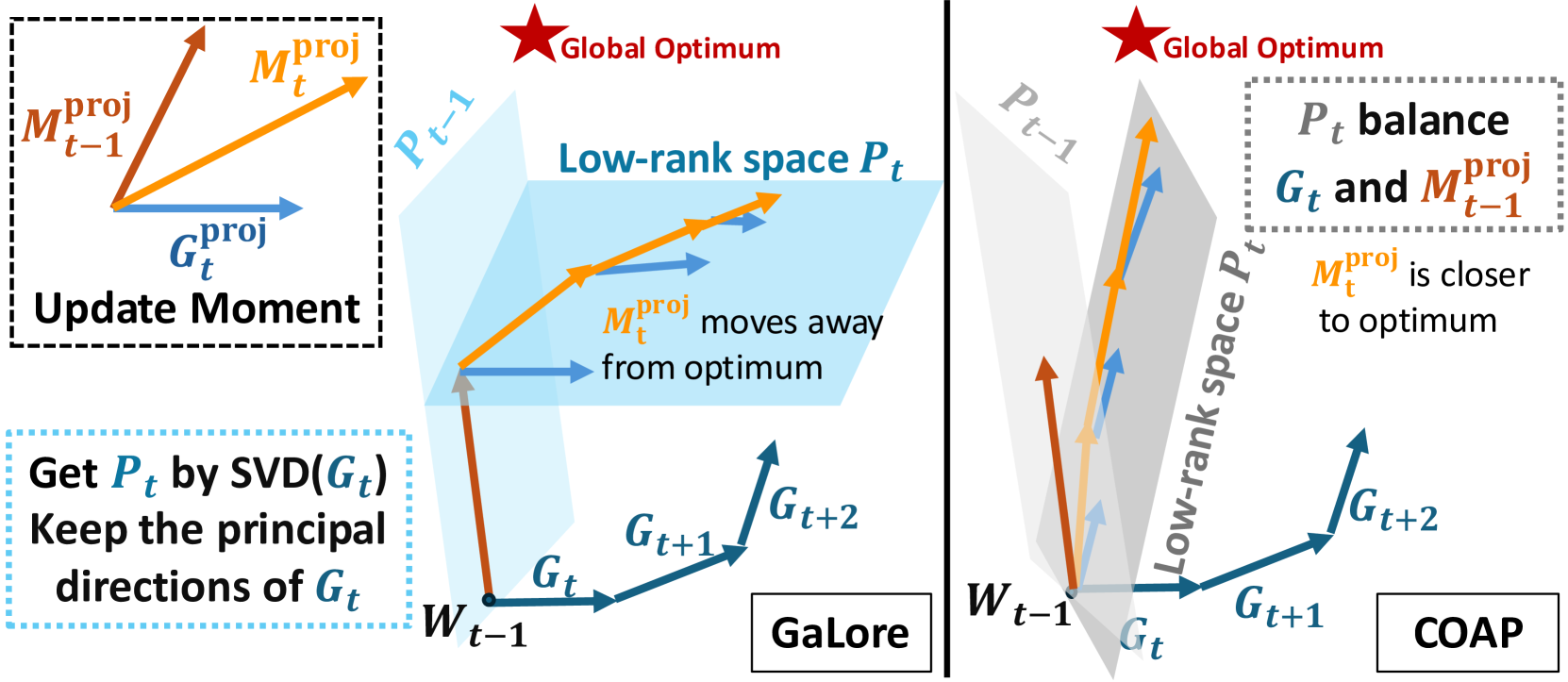
问题定义:论文旨在解决大规模神经网络训练中优化器状态占用大量内存的问题。现有的低秩梯度投影方法,如GaLore和Flora,虽然能降低内存占用,但忽略了不同投影之间的相关性,导致模型性能下降,并且投影计算开销较大。
核心思路:COAP的核心思路是在梯度投影过程中,显式地考虑并利用不同投影之间的相关性信息。通过对相关性进行建模,可以更有效地进行梯度投影,从而在减少内存占用的同时,保持甚至提升模型性能。此外,COAP还致力于降低投影过程本身的计算复杂度。
技术框架:COAP方法主要包含以下几个阶段:1. 计算梯度;2. 估计梯度投影之间的相关性;3. 基于相关性信息进行梯度投影;4. 使用投影后的梯度更新模型参数。整个框架旨在通过相关性感知的梯度投影,实现内存高效的训练。
关键创新:COAP的关键创新在于提出了相关性感知的梯度投影方法。与现有方法不同,COAP显式地建模并利用了梯度投影之间的相关性,从而提高了梯度投影的效率和准确性。这种相关性感知的机制是COAP能够优于现有方法的核心原因。
关键设计:COAP的具体实现细节包括:如何有效地估计梯度投影之间的相关性(例如,可以使用统计方法或神经网络来学习相关性);如何将相关性信息融入到梯度投影过程中(例如,可以使用加权投影或自适应投影);以及如何优化整个流程以降低计算复杂度。论文中可能还涉及一些超参数的设置,例如相关性估计的窗口大小、投影矩阵的秩等。
🖼️ 关键图片

📊 实验亮点
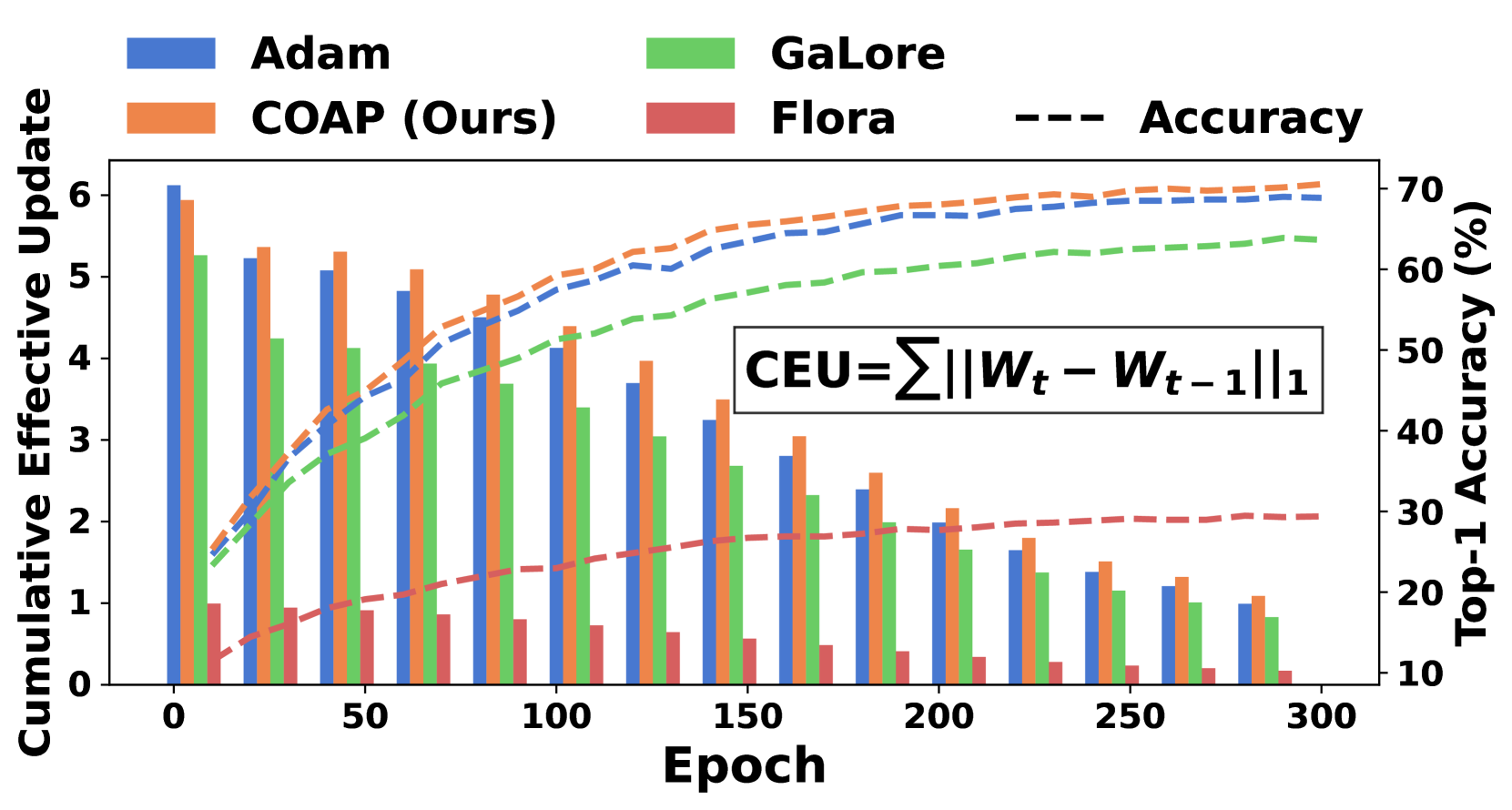
COAP在LLaMA-1B上将优化器内存减少了61%,且仅增加2%的时间成本,达到与AdamW相同的PPL。在LLaVA-v1.5-7B微调中,结合8位量化,COAP将优化器内存减少了81%,并实现了比GaLore快4倍的速度,同时获得了更高的准确率。这些结果表明COAP在内存效率和训练速度方面均优于现有方法。
🎯 应用场景
COAP方法可广泛应用于各种需要训练大型神经网络的场景,例如计算机视觉、自然语言处理和多模态学习等领域。它能够显著降低训练过程中的内存需求,使得在资源受限的设备上训练大型模型成为可能。此外,COAP还可以加速模型训练过程,提高开发效率,具有重要的实际应用价值和广阔的未来发展前景。
📄 摘要(原文)
Training large-scale neural networks in vision, and multimodal domains demands substantial memory resources, primarily due to the storage of optimizer states. While LoRA, a popular parameter-efficient method, reduces memory usage, it often suffers from suboptimal performance due to the constraints of low-rank updates. Low-rank gradient projection methods (e.g., GaLore, Flora) reduce optimizer memory by projecting gradients and moment estimates into low-rank spaces via singular value decomposition or random projection. However, they fail to account for inter-projection correlation, causing performance degradation, and their projection strategies often incur high computational costs. In this paper, we present COAP (Correlation-Aware Gradient Projection), a memory-efficient method that minimizes computational overhead while maintaining training performance. Evaluated across various vision, language, and multimodal tasks, COAP outperforms existing methods in both training speed and model performance. For LLaMA-1B, it reduces optimizer memory by 61% with only 2% additional time cost, achieving the same PPL as AdamW. With 8-bit quantization, COAP cuts optimizer memory by 81% and achieves 4x speedup over GaLore for LLaVA-v1.5-7B fine-tuning, while delivering higher accuracy.