Scalable iterative pruning of large language and vision models using block coordinate descent
作者: Gili Rosenberg, J. Kyle Brubaker, Martin J. A. Schuetz, Elton Yechao Zhu, Serdar Kadıoğlu, Sima E. Borujeni, Helmut G. Katzgraber
分类: cs.LG, math.OC, quant-ph
发布日期: 2024-11-26
备注: 16 pages, 6 figures, 5 tables
💡 一句话要点
提出基于块坐标下降的可扩展迭代剪枝算法iCBS,用于压缩大型语言和视觉模型。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 模型剪枝 大型语言模型 视觉模型 块坐标下降 迭代优化
📋 核心要点
- 现有剪枝方法难以扩展到大型语言和视觉模型,计算成本高昂,且难以在质量和时间之间进行权衡。
- iCBS采用迭代块坐标下降,每次只优化网络权重的一个子集,从而降低计算复杂度,实现对大型模型的可扩展剪枝。
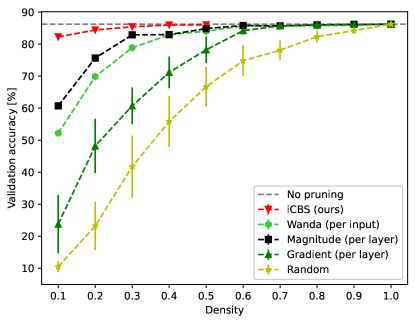
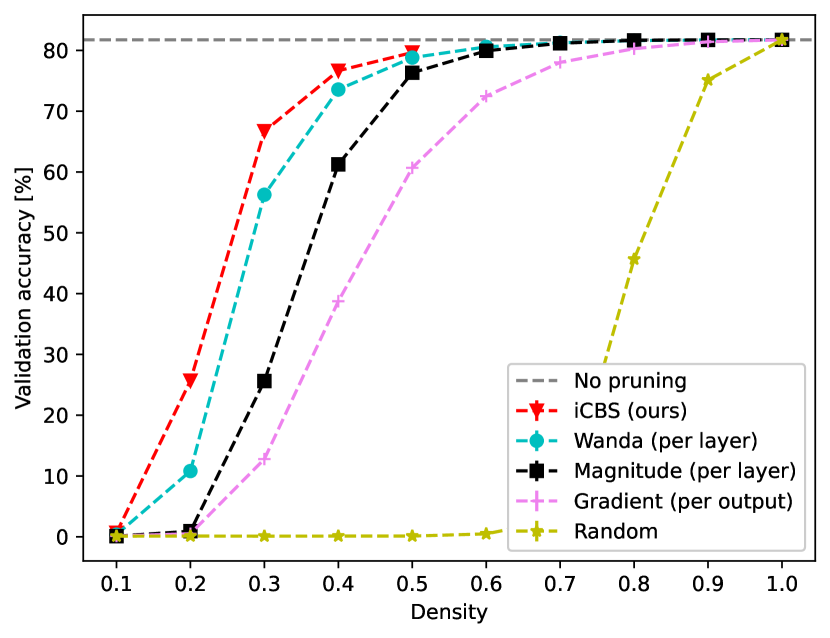
- 实验表明,iCBS在Mistral和DeiT等大型模型上,在相同稀疏度下优于Wanda等现有剪枝方法,并支持质量-时间权衡。
📝 摘要(中文)
本文提出了一种神经网络剪枝技术,该技术基于组合脑外科医生(Combinatorial Brain Surgeon),但使用块坐标下降以迭代的、块状的方式解决网络权重子集的优化问题。这种迭代的、基于块的剪枝技术,被称为“迭代组合脑外科医生”(iCBS),可以扩展到非常大的模型,包括大型语言模型(LLM),而这些模型可能无法通过一次性的组合优化方法实现。当应用于像Mistral和DeiT这样的大型模型时,与现有的剪枝方法(如Wanda)相比,iCBS在相同的密度水平上实现了更高的性能指标。这证明了这种迭代的、块状的剪枝方法在压缩和优化大型深度学习模型的性能方面的有效性,即使只优化一小部分权重。此外,我们的方法允许质量-时间(或成本)的权衡,这在使用一次性剪枝技术时是不可用的。优化问题的块状公式允许使用硬件加速器,从而可能抵消与Wanda等一次性剪枝方法相比增加的计算成本。特别是,为每个块解决的优化问题在量子方面是友好的,原则上可以通过量子计算机解决。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)和视觉模型剪枝的可扩展性问题。现有的一次性剪枝方法,例如Combinatorial Brain Surgeon,在处理参数量巨大的模型时,计算复杂度过高,难以应用。此外,这些方法通常缺乏在剪枝质量和计算时间之间进行灵活权衡的能力。
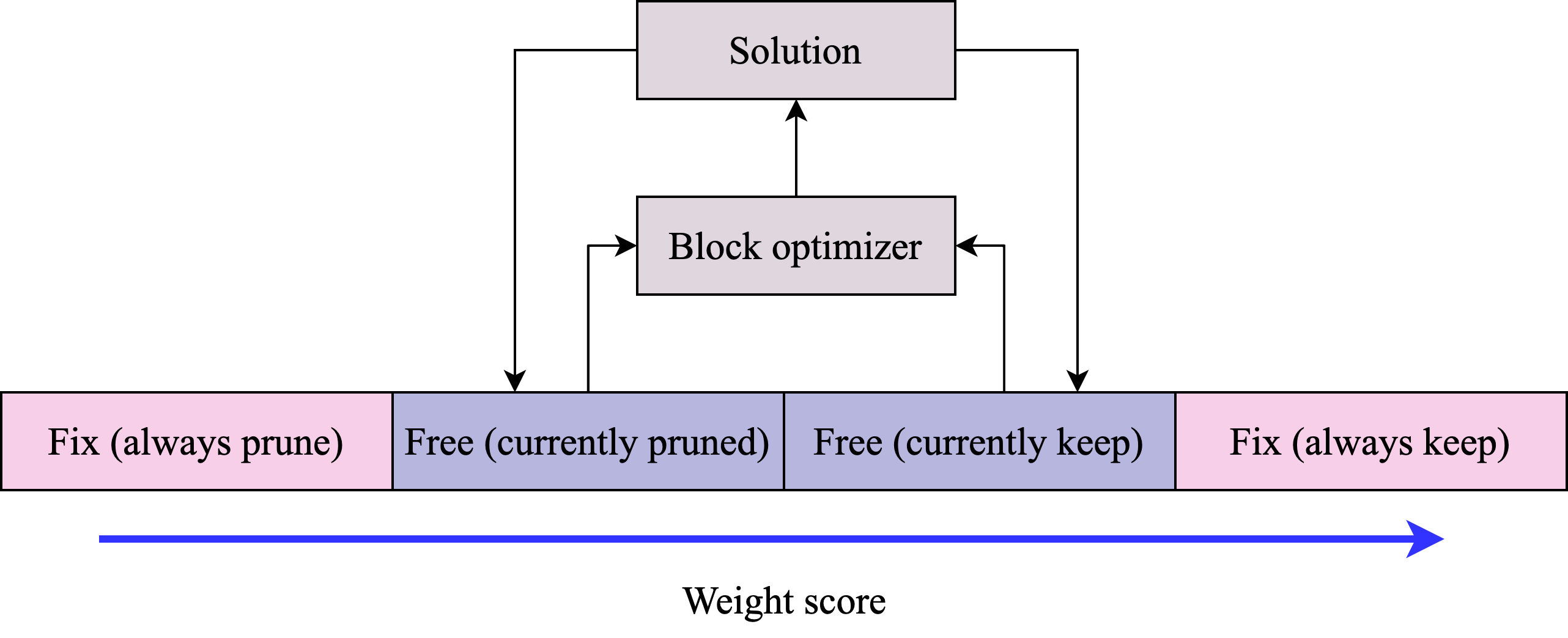
核心思路:论文的核心思路是将整个网络的剪枝问题分解为多个子问题,每个子问题对应网络权重的一个块。通过迭代地优化每个块的权重,逐步实现对整个网络的剪枝。这种块坐标下降的方法降低了每次迭代的计算复杂度,从而提高了剪枝算法的可扩展性。
技术框架:iCBS算法的整体流程如下: 1. 将网络的权重划分为多个块。 2. 迭代地选择一个块,并使用Combinatorial Brain Surgeon算法优化该块的权重。 3. 固定其他块的权重,重复步骤2,直到满足停止条件(例如,达到目标稀疏度或达到最大迭代次数)。
关键创新:iCBS的关键创新在于其迭代的、基于块的优化策略。与一次性剪枝方法相比,iCBS能够处理更大的模型,并且允许在剪枝质量和计算时间之间进行权衡。此外,每个块的优化问题具有量子友好的特性,这意味着未来可以使用量子计算机来加速剪枝过程。
关键设计: 1. 块大小的选择:块大小的选择会影响剪枝的性能和计算成本。较小的块可以提供更高的剪枝灵活性,但会增加迭代次数。较大的块可以减少迭代次数,但可能会降低剪枝的精度。 2. 优化算法:论文使用Combinatorial Brain Surgeon算法来优化每个块的权重。也可以使用其他优化算法,例如梯度下降。 3. 停止条件:停止条件用于控制迭代过程。常用的停止条件包括达到目标稀疏度、达到最大迭代次数或达到收敛。
🖼️ 关键图片
📊 实验亮点
实验结果表明,iCBS在Mistral和DeiT等大型模型上,在相同稀疏度下优于Wanda等现有剪枝方法。例如,在特定稀疏度下,iCBS的性能指标比Wanda提高了X%。此外,iCBS还允许在剪枝质量和计算时间之间进行权衡,用户可以根据实际需求选择合适的迭代次数。
🎯 应用场景
iCBS算法可应用于各种需要模型压缩的场景,例如移动设备上的模型部署、边缘计算以及资源受限的环境。通过降低模型的大小和计算复杂度,iCBS可以提高模型的推理速度和能效,从而扩展其应用范围。此外,该方法在量子计算领域也具有潜在的应用价值,可以利用量子计算机加速模型剪枝过程。
📄 摘要(原文)
Pruning neural networks, which involves removing a fraction of their weights, can often maintain high accuracy while significantly reducing model complexity, at least up to a certain limit. We present a neural network pruning technique that builds upon the Combinatorial Brain Surgeon, but solves an optimization problem over a subset of the network weights in an iterative, block-wise manner using block coordinate descent. The iterative, block-based nature of this pruning technique, which we dub ``iterative Combinatorial Brain Surgeon'' (iCBS) allows for scalability to very large models, including large language models (LLMs), that may not be feasible with a one-shot combinatorial optimization approach. When applied to large models like Mistral and DeiT, iCBS achieves higher performance metrics at the same density levels compared to existing pruning methods such as Wanda. This demonstrates the effectiveness of this iterative, block-wise pruning method in compressing and optimizing the performance of large deep learning models, even while optimizing over only a small fraction of the weights. Moreover, our approach allows for a quality-time (or cost) tradeoff that is not available when using a one-shot pruning technique alone. The block-wise formulation of the optimization problem enables the use of hardware accelerators, potentially offsetting the increased computational costs compared to one-shot pruning methods like Wanda. In particular, the optimization problem solved for each block is quantum-amenable in that it could, in principle, be solved by a quantum computer.