Pushing the Limits of Large Language Model Quantization via the Linearity Theorem
作者: Vladimir Malinovskii, Andrei Panferov, Ivan Ilin, Han Guo, Peter Richtárik, Dan Alistarh
分类: cs.LG
发布日期: 2024-11-26
💡 一句话要点
提出线性定理以优化大语言模型量化方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 量化方法 线性定理 数据无关量化 动态规划 GPU优化 模型压缩 准确性提升
📋 核心要点
- 现有量化方法主要集中于逐层误差最小化,缺乏理论支持且指标选择可能不理想。
- 本文提出的线性定理揭示了逐层重构误差与模型困惑度之间的关系,推动了新量化方法的开发。
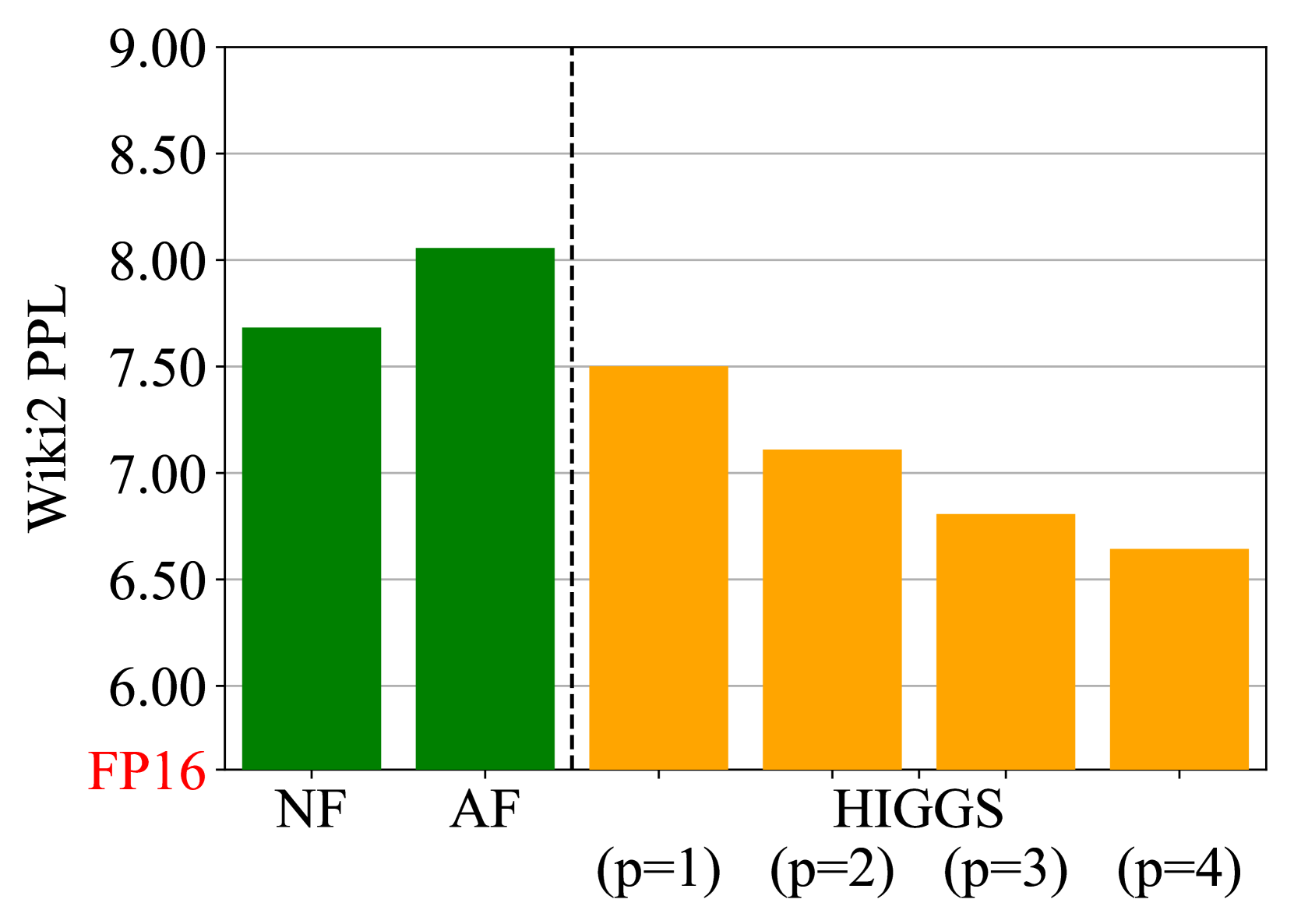
- 实验结果表明,HIGGS方法在多个模型上实现了更优的准确性与压缩效果,且支持高效的GPU实现。
📝 摘要(中文)
量化大语言模型已成为降低其内存和计算成本的标准方法。现有方法通常将问题分解为逐层子问题,最小化每层的误差,但缺乏理论依据且所用指标可能不够优化。本文提出的“线性定理”建立了逐层$ ext{l}_2$重构误差与量化导致的模型困惑度增加之间的直接关系。这一见解促成了两项新应用:一种基于Hadamard旋转和均方误差最优网格的数据无关LLM量化方法HIGGS,超越了以往的数据无关方法;以及通过动态规划求解的非均匀逐层量化水平的最优方案。我们在Llama-3.1和3.2系列模型及Qwen系列模型上展示了改进的准确性与压缩权衡。
🔬 方法详解
问题定义:本文旨在解决大语言模型量化过程中逐层误差最小化缺乏理论支持的问题。现有方法往往依赖于不够优化的指标,导致量化效果不理想。
核心思路:论文提出的线性定理建立了逐层$ ext{l}_2$重构误差与模型困惑度增加之间的直接关系,这一理论基础为新方法的设计提供了支持。
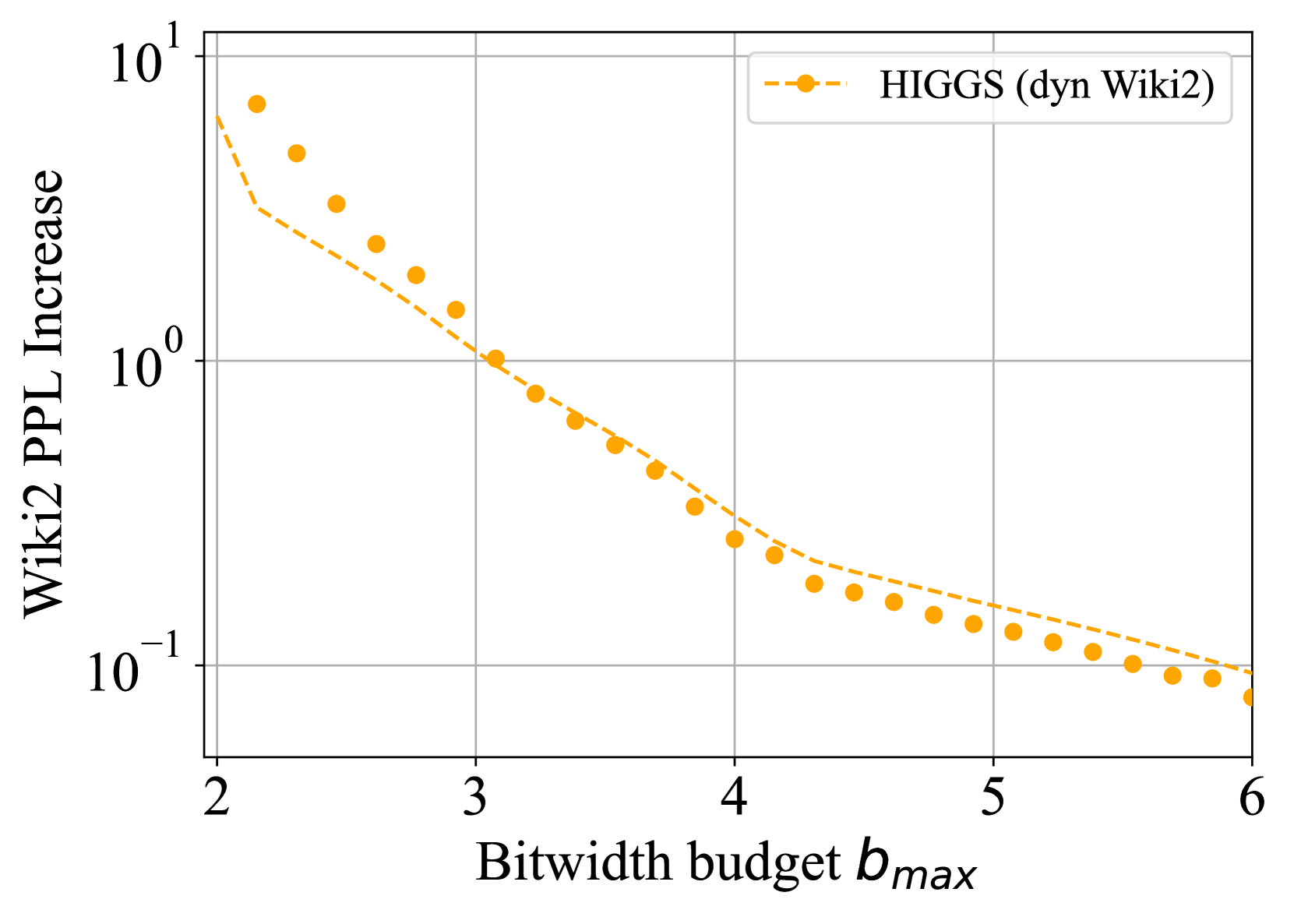
技术框架:整体方法包括两个主要模块:首先是基于Hadamard旋转和均方误差最优网格的HIGGS量化方法,其次是通过动态规划实现的非均匀逐层量化水平的优化。
关键创新:最重要的技术创新在于线性定理的提出,使得量化过程中的误差分析更加系统化,并且为数据无关和非均匀量化提供了理论依据。
关键设计:在HIGGS方法中,采用Hadamard旋转和均方误差最优网格进行量化,确保了在数据无关情况下的最佳性能;而在非均匀量化中,通过动态规划实现了在给定压缩约束下的最优量化水平选择。
🖼️ 关键图片

📊 实验亮点
实验结果显示,HIGGS方法在Llama-3.1和3.2系列模型及Qwen系列模型上实现了显著的准确性提升,相较于流行的NF4量化格式,HIGGS在数据无关量化中表现更优。此外,该方法在不同批量大小下的GPU实现效率也得到了提升,进一步增强了其实用性。
🎯 应用场景
该研究的潜在应用领域包括大语言模型的高效部署,尤其是在资源受限的环境中。通过优化量化方法,可以显著降低模型的内存和计算需求,从而推动更广泛的人工智能应用,尤其是在移动设备和边缘计算场景中的应用。未来,该方法可能会影响更多模型的量化策略,提升其实际应用价值。
📄 摘要(原文)
Quantizing large language models has become a standard way to reduce their memory and computational costs. Typically, existing methods focus on breaking down the problem into individual layer-wise sub-problems, and minimizing per-layer error, measured via various metrics. Yet, this approach currently lacks theoretical justification and the metrics employed may be sub-optimal. In this paper, we present a "linearity theorem" establishing a direct relationship between the layer-wise $\ell_2$ reconstruction error and the model perplexity increase due to quantization. This insight enables two novel applications: (1) a simple data-free LLM quantization method using Hadamard rotations and MSE-optimal grids, dubbed HIGGS, which outperforms all prior data-free approaches such as the extremely popular NF4 quantized format, and (2) an optimal solution to the problem of finding non-uniform per-layer quantization levels which match a given compression constraint in the medium-bitwidth regime, obtained by reduction to dynamic programming. On the practical side, we demonstrate improved accuracy-compression trade-offs on Llama-3.1 and 3.2-family models, as well as on Qwen-family models. Further, we show that our method can be efficiently supported in terms of GPU kernels at various batch sizes, advancing both data-free and non-uniform quantization for LLMs.