Joint Combinatorial Node Selection and Resource Allocations in the Lightning Network using Attention-based Reinforcement Learning
作者: Mahdi Salahshour, Amirahmad Shafiee, Mojtaba Tefagh
分类: cs.LG, q-fin.CP
发布日期: 2024-11-26
💡 一句话要点
提出基于注意力机制强化学习的LN节点选择与资源分配联合优化方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 闪电网络 深度强化学习 Transformer 节点选择 资源分配 支付通道网络 组合优化 去中心化
📋 核心要点
- 现有LN研究未能充分考虑资源分配的重要性,且缺乏对LN路由机制的真实模拟,导致节点选择和资源分配的联合优化问题难以解决。
- 论文提出一种基于Transformer增强的深度强化学习框架,用于解决LN中节点选择和资源分配的联合组合优化问题,旨在最大化个体收益。
- 实验结果表明,该模型在各种设置下均优于现有基线和启发式方法,并且验证了该方法与LN去中心化目标并不冲突,反而可能促进其发展。
📝 摘要(中文)
闪电网络(LN)作为比特币可扩展性挑战的第二层解决方案而出现。支付通道网络(PCN)的兴起及其特定机制激励个人加入网络以获取利润。最新统计数据显示,闪电网络中锁定的总价值约为5亿美元。然而,以盈利为动机加入LN存在若干障碍,因为它涉及解决一个复杂的组合问题,该问题包含与节点选择和资源分配相关的离散和连续控制变量。当前的研究未能充分捕捉资源分配的关键作用,并且缺乏对LN路由机制的真实模拟。本文提出了一种深度强化学习(DRL)框架,通过Transformer增强,以解决联合组合节点选择和资源分配(JCNSRA)问题。我们通过引入增强其路由机制的模块改进了现有环境,从而缩小了与实际LN路由系统的差距,并确保与JCNSRA问题的兼容性。我们将我们的模型与多个基线和启发式方法进行比较,证明了其在各种设置下的卓越性能。此外,我们通过在网络中部署我们的代理并监控演化图的中心性度量来解决对LN中中心化问题的担忧。我们的研究结果表明,LN的去中心化目标与个人收入最大化激励之间不仅不存在冲突,而且两者之间存在正相关关系。
🔬 方法详解
问题定义:论文旨在解决闪电网络(LN)中节点选择和资源分配的联合组合优化问题(JCNSRA)。现有方法主要痛点在于:1) 未能充分考虑资源分配对收益的影响;2) 缺乏对LN真实路由机制的模拟,导致优化结果与实际应用存在差距。
核心思路:论文的核心思路是利用深度强化学习(DRL)框架,结合Transformer的注意力机制,学习在复杂的LN环境中进行节点选择和资源分配的策略。通过DRL,智能体能够自主探索和学习最优策略,而Transformer则能够捕捉节点之间的复杂关系,从而做出更明智的决策。
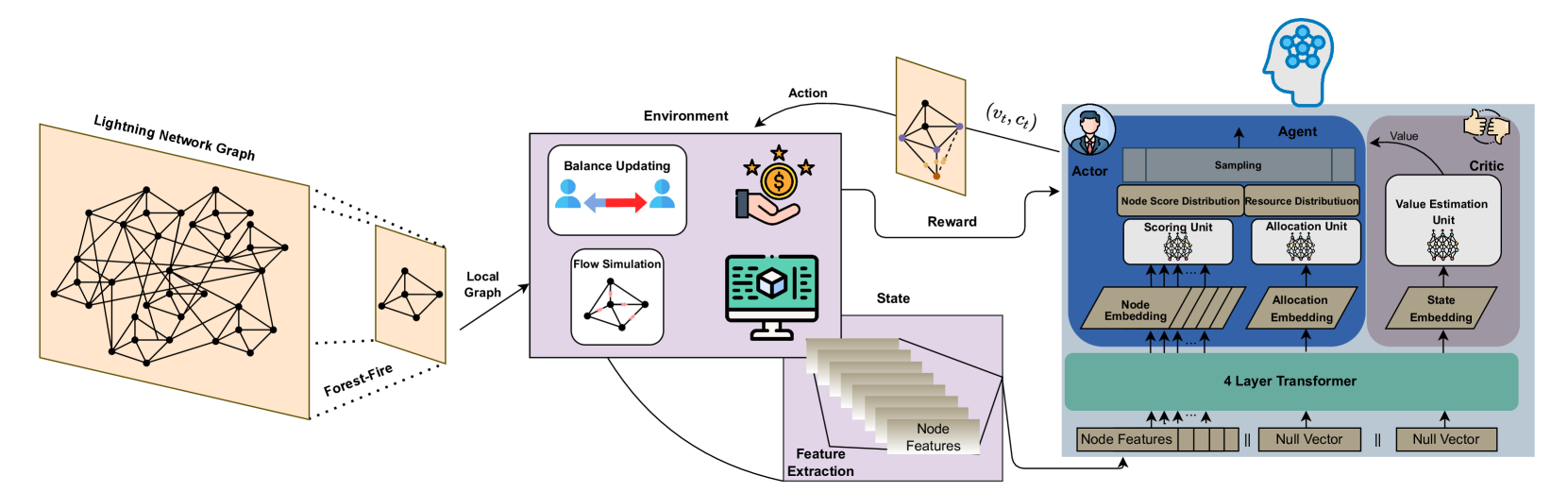
技术框架:整体框架包含以下几个主要模块:1) LN环境模拟器:模拟真实的LN网络拓扑和交易路由机制;2) 智能体(Agent):基于Transformer的DRL模型,负责学习节点选择和资源分配策略;3) 奖励函数:根据智能体的收益进行奖励,引导智能体学习最大化收益的策略;4) 训练模块:使用强化学习算法(未知,论文未明确指出)训练智能体。
关键创新:论文的关键创新在于:1) 将节点选择和资源分配问题建模为联合组合优化问题,更贴近实际应用场景;2) 引入Transformer的注意力机制,增强了智能体对LN网络拓扑和节点间关系的理解能力;3) 改进了LN环境模拟器,使其更接近真实的LN路由机制。
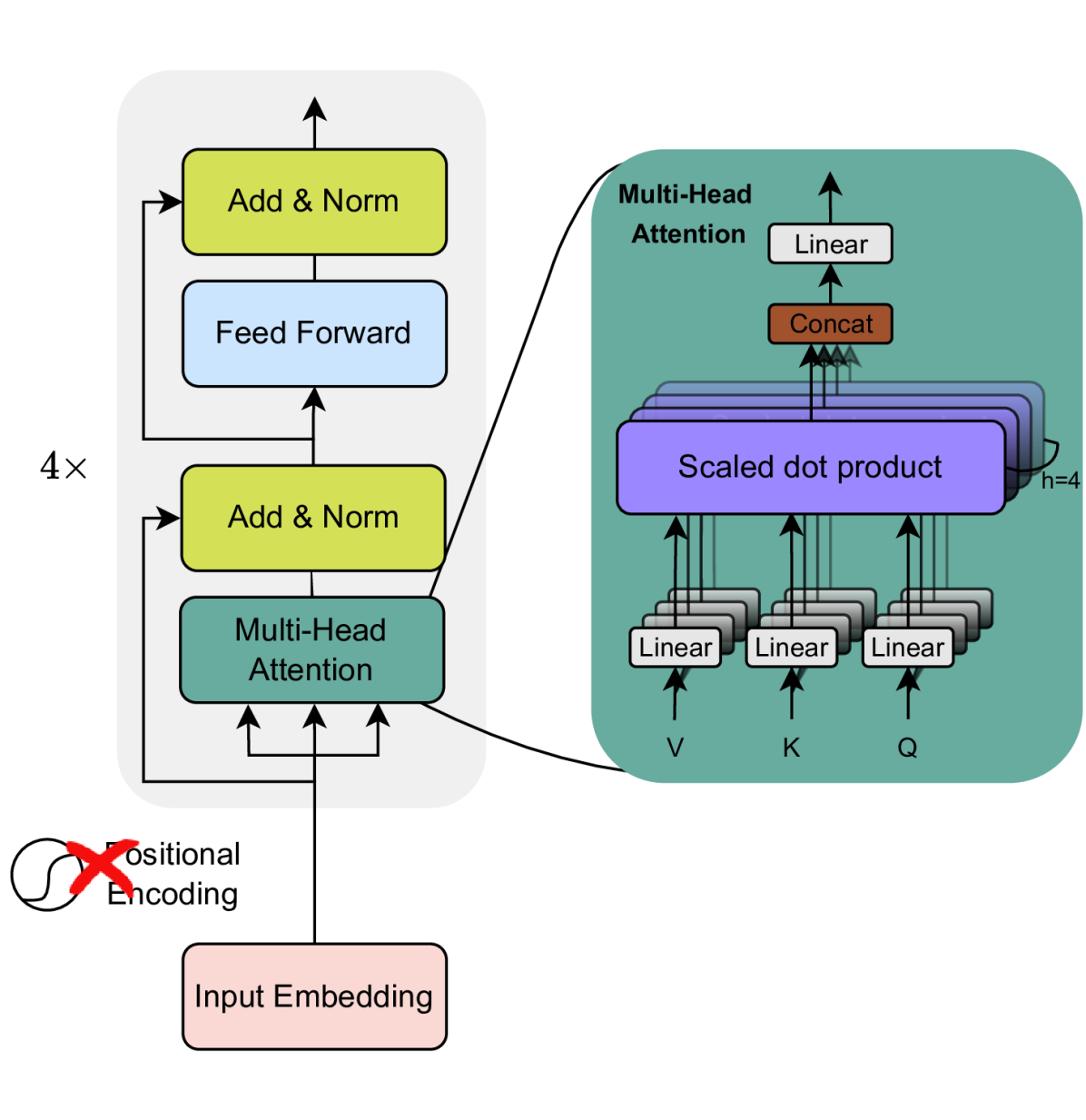
关键设计:论文的关键设计细节包括:1) 使用Transformer编码LN网络拓扑和节点特征;2) 设计合适的奖励函数,鼓励智能体选择有利可图的节点并合理分配资源;3) 具体Transformer的网络结构(层数、维度等)和强化学习算法(如PPO、DQN等)未知,论文未明确指出。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该模型在各种设置下均优于现有基线和启发式方法,证明了其在解决JCNSRA问题上的有效性。此外,通过监控演化图的中心性度量,发现该方法与LN的去中心化目标并不冲突,甚至可能促进其发展。具体的性能提升数据未知,论文未明确给出。
🎯 应用场景
该研究成果可应用于指导个人或机构在闪电网络中进行节点选择和资源分配,以最大化收益。同时,该研究有助于理解LN的动态特性和潜在的中心化风险,为LN的健康发展提供理论支持。未来,该方法可以扩展到其他支付通道网络或区块链应用中。
📄 摘要(原文)
The Lightning Network (LN) has emerged as a second-layer solution to Bitcoin's scalability challenges. The rise of Payment Channel Networks (PCNs) and their specific mechanisms incentivize individuals to join the network for profit-making opportunities. According to the latest statistics, the total value locked within the Lightning Network is approximately \$500 million. Meanwhile, joining the LN with the profit-making incentives presents several obstacles, as it involves solving a complex combinatorial problem that encompasses both discrete and continuous control variables related to node selection and resource allocation, respectively. Current research inadequately captures the critical role of resource allocation and lacks realistic simulations of the LN routing mechanism. In this paper, we propose a Deep Reinforcement Learning (DRL) framework, enhanced by the power of transformers, to address the Joint Combinatorial Node Selection and Resource Allocation (JCNSRA) problem. We have improved upon an existing environment by introducing modules that enhance its routing mechanism, thereby narrowing the gap with the actual LN routing system and ensuring compatibility with the JCNSRA problem. We compare our model against several baselines and heuristics, demonstrating its superior performance across various settings. Additionally, we address concerns regarding centralization in the LN by deploying our agent within the network and monitoring the centrality measures of the evolved graph. Our findings suggest not only an absence of conflict between LN's decentralization goals and individuals' revenue-maximization incentives but also a positive association between the two.