AutoElicit: Using Large Language Models for Expert Prior Elicitation in Predictive Modelling
作者: Alexander Capstick, Rahul G. Krishnan, Payam Barnaghi
分类: cs.LG, cs.CL, stat.ML
发布日期: 2024-11-26 (更新: 2025-05-28)
💡 一句话要点
AutoElicit:利用大语言模型为预测模型提取专家先验知识
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 专家先验知识 预测模型 贝叶斯推理 知识提取
📋 核心要点
- 在数据稀缺领域,专家先验知识对预测模型至关重要,但人工获取耗时。
- AutoElicit利用大语言模型提取知识,自动构建信息丰富的模型先验分布。
- 实验表明,AutoElicit优于上下文学习,显著减少误差并节省标注成本。
📝 摘要(中文)
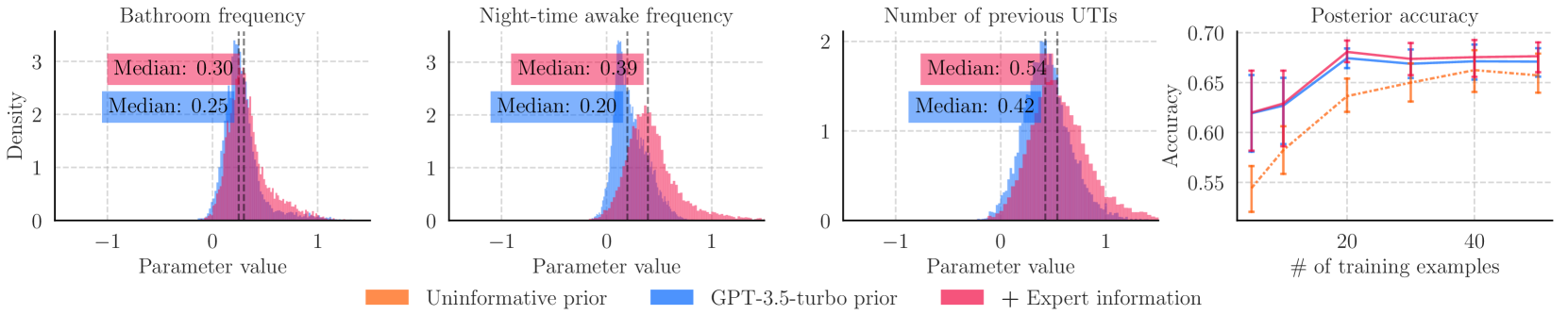
大型语言模型(LLMs)在各个领域都积累了广泛的信息。然而,它们的计算复杂性、成本和缺乏透明度通常阻碍了它们在预测任务中的直接应用,尤其是在隐私和可解释性至关重要的情况下。在医疗保健、生物学和金融等领域,专业且可解释的线性模型仍然具有相当大的价值。在这些领域,带标签的数据可能稀缺或获取成本高昂。对模型参数进行良好指定的先验分布可以降低贝叶斯推理的学习样本复杂度;然而,获取专家先验知识可能非常耗时。因此,我们引入AutoElicit,从LLM中提取知识并构建预测模型的先验。我们表明这些先验是有信息的,并且可以使用自然语言进行改进。我们进行了一项仔细的研究,将AutoElicit与上下文学习进行对比,并演示了如何在两种方法之间执行模型选择。我们发现,AutoElicit产生的先验可以显著减少非信息先验的误差,使用更少的标签,并且始终优于上下文学习。我们表明,当从患有痴呆症的人的传感器记录中构建新的尿路感染预测模型时,AutoElicit可以节省超过6个月的标签工作。
🔬 方法详解
问题定义:论文旨在解决在数据稀缺或标注成本高的领域,如何高效地获取预测模型所需的专家先验知识的问题。现有方法依赖于人工访谈专家,过程耗时且成本高昂。直接使用大型语言模型进行预测,又存在计算成本高、缺乏透明度和可解释性的问题。
核心思路:论文的核心思路是利用大型语言模型(LLMs)中蕴含的丰富知识,通过特定的提示工程(Prompt Engineering)和知识提取方法,自动构建预测模型的先验分布。这样既能利用LLMs的知识广度,又能避免直接使用LLMs带来的问题,同时降低了获取专家先验知识的成本。
技术框架:AutoElicit的整体框架包括以下几个主要阶段:1) 问题定义:明确需要构建先验知识的预测模型和相关领域。2) 提示工程:设计合适的提示语,引导LLM输出与模型参数相关的知识。3) 知识提取:从LLM的输出中提取有用的信息,例如参数的均值、方差等。4) 先验构建:根据提取的信息,构建模型参数的先验分布。5) 模型训练与评估:使用构建的先验分布训练预测模型,并评估其性能。
关键创新:AutoElicit的关键创新在于将大型语言模型作为专家知识的来源,并设计了一套自动化的流程来提取和利用这些知识。与传统的专家访谈相比,AutoElicit更加高效和可扩展。与直接使用LLMs进行预测相比,AutoElicit构建的先验分布可以提高模型的可解释性和鲁棒性。
关键设计:AutoElicit的关键设计包括:1) 提示语的设计:提示语需要能够准确地引导LLM输出与模型参数相关的知识,例如参数的含义、取值范围、与其他参数的关系等。2) 知识提取方法:需要设计合适的方法从LLM的输出中提取有用的信息,例如使用正则表达式或自然语言处理技术。3) 先验分布的选择:需要根据提取的信息选择合适的先验分布,例如高斯分布、Beta分布等。论文还探讨了如何使用自然语言对先验进行精细调整。
🖼️ 关键图片


📊 实验亮点
实验结果表明,AutoElicit构建的先验分布能够显著减少预测模型的误差,尤其是在数据量较少的情况下。与非信息先验相比,AutoElicit能够显著提高模型性能。此外,AutoElicit在尿路感染预测任务中,相比人工标注,节省了超过6个月的标注工作量,证明了其高效性。
🎯 应用场景
AutoElicit可应用于医疗健康、金融、生物等领域,在这些领域中,带标签数据稀缺,专家知识至关重要。例如,可以利用AutoElicit构建疾病预测模型、信用风险评估模型、基因表达调控模型等。该方法能够降低模型开发成本,提高模型性能,并促进相关领域的科学研究和应用。
📄 摘要(原文)
Large language models (LLMs) acquire a breadth of information across various domains. However, their computational complexity, cost, and lack of transparency often hinder their direct application for predictive tasks where privacy and interpretability are paramount. In fields such as healthcare, biology, and finance, specialised and interpretable linear models still hold considerable value. In such domains, labelled data may be scarce or expensive to obtain. Well-specified prior distributions over model parameters can reduce the sample complexity of learning through Bayesian inference; however, eliciting expert priors can be time-consuming. We therefore introduce AutoElicit to extract knowledge from LLMs and construct priors for predictive models. We show these priors are informative and can be refined using natural language. We perform a careful study contrasting AutoElicit with in-context learning and demonstrate how to perform model selection between the two methods. We find that AutoElicit yields priors that can substantially reduce error over uninformative priors, using fewer labels, and consistently outperform in-context learning. We show that AutoElicit saves over 6 months of labelling effort when building a new predictive model for urinary tract infections from sensor recordings of people living with dementia.