Representation Collapsing Problems in Vector Quantization
作者: Wenhao Zhao, Qiran Zou, Rushi Shah, Dianbo Liu
分类: cs.LG, cs.AI
发布日期: 2024-11-25
备注: 13 pages, under review
💡 一句话要点
研究向量量化中的表征坍塌问题,并提出缓解方案
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 向量量化 表征坍塌 生成模型 码本学习 初始化策略
📋 核心要点
- 现有生成模型中向量量化技术缺乏深入研究,其表征坍塌问题会导致模型无法有效捕获数据多样性。
- 该论文通过分析合成和真实数据,揭示了受限初始化和有限编码器容量是导致表征坍塌的关键因素。
- 针对不同类型的表征坍塌,论文提出了相应的缓解策略,旨在提升向量量化在生成模型中的性能。
📝 摘要(中文)
向量量化是一种机器学习技术,它将连续的表征离散化为一组离散向量。它被广泛应用于大型语言模型、扩散模型和其他生成模型的数据表征标记化。尽管其应用广泛,但向量量化在生成模型中的特性和行为仍未得到充分探索。本研究调查了向量量化中的表征坍塌问题——一种关键的退化现象,其中码本标记或潜在嵌入通过收敛到有限的数值子集而失去其判别能力。这种坍塌从根本上损害了模型捕获多样化数据模式的能力。通过利用合成和真实数据集,我们确定了每种类型坍塌的严重程度和触发条件。我们的分析表明,受限的初始化和有限的编码器容量会导致标记坍塌和嵌入坍塌。基于这些发现,我们提出了旨在缓解每种坍塌的潜在解决方案。据我们所知,这是第一个全面研究向量量化中表征坍塌问题的研究。
🔬 方法详解
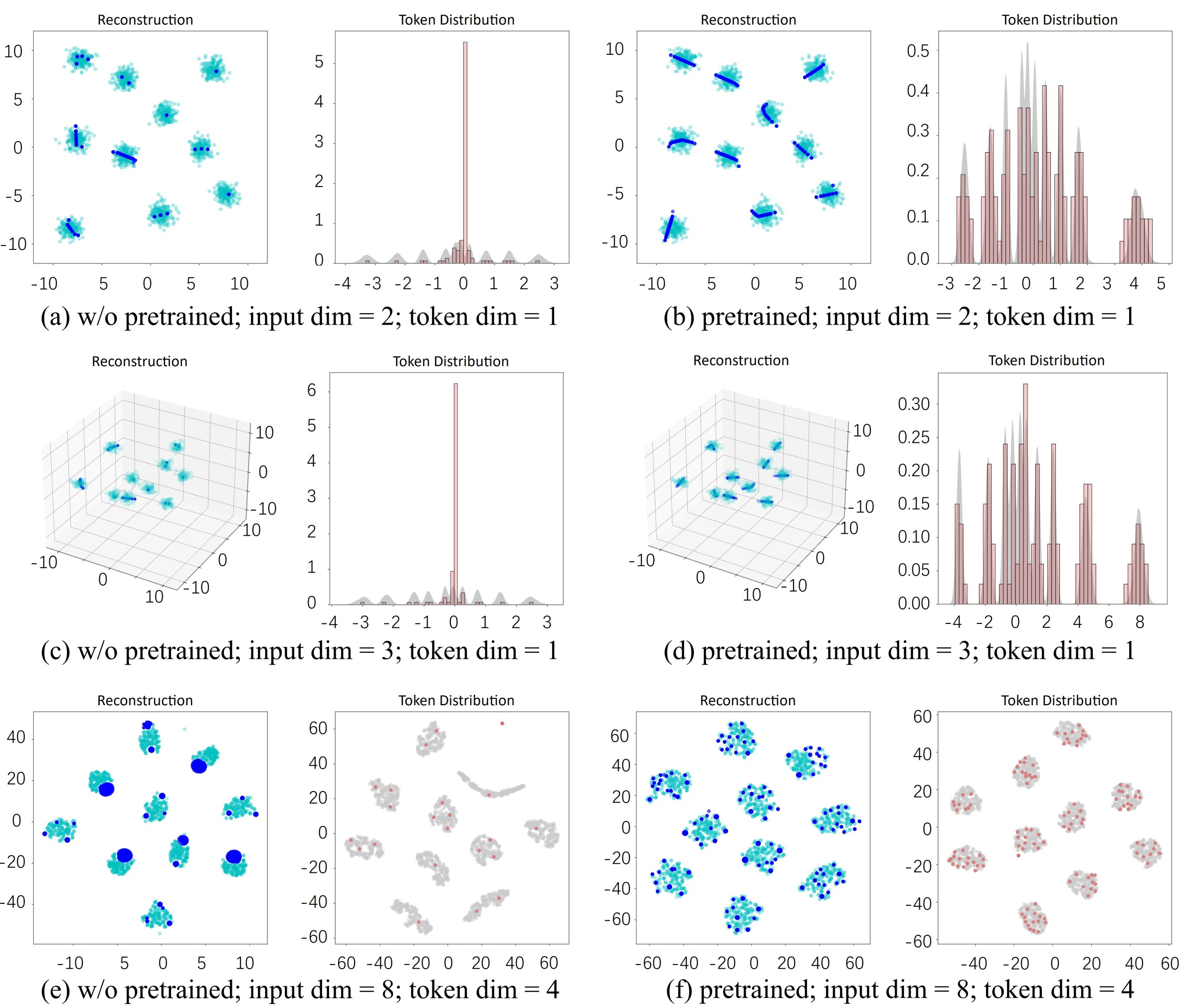
问题定义:论文旨在解决向量量化(VQ)中表征坍塌的问题。表征坍塌是指码本中的token或者潜在嵌入收敛到少量的值,导致模型无法捕捉到数据中丰富的模式。现有方法缺乏对这一问题的深入理解和有效解决方案,限制了VQ在生成模型中的应用。
核心思路:论文的核心思路是通过分析表征坍塌的触发条件,即受限的初始化和有限的编码器容量,来设计相应的缓解策略。通过控制初始化方式和增加编码器容量,可以避免或减轻表征坍塌,从而提升VQ的性能。
技术框架:论文首先通过合成数据和真实数据来复现和分析表征坍塌现象。然后,针对token坍塌和embedding坍塌,分别提出了不同的缓解方案。对于token坍塌,可能采用更好的初始化策略或者正则化方法。对于embedding坍塌,可能需要增加编码器的容量或者采用对比学习等方法。最后,通过实验验证了所提出方案的有效性。
关键创新:论文的关键创新在于首次全面地研究了向量量化中的表征坍塌问题,并从初始化和编码器容量两个方面揭示了其触发条件。此外,论文还针对不同类型的坍塌提出了相应的缓解策略,为解决这一问题提供了新的思路。
关键设计:论文中可能涉及的关键设计包括:1)码本初始化的方式,例如使用K-means++初始化;2)编码器的网络结构和容量,例如增加编码器的层数或神经元数量;3)损失函数的设计,例如引入正则化项来约束码本的分布;4)训练策略,例如采用对比学习来增强嵌入的区分性。
🖼️ 关键图片


📊 实验亮点
该研究通过实验验证了受限初始化和有限编码器容量是导致表征坍塌的关键因素。通过改进初始化策略和增加编码器容量,可以有效缓解表征坍塌,提升向量量化在生成模型中的性能。具体的性能提升数据未知,但论文强调了缓解策略的有效性。
🎯 应用场景
该研究成果可应用于各种生成模型,如大型语言模型、扩散模型等,提升模型生成样本的多样性和质量。通过缓解表征坍塌问题,可以提高模型对复杂数据分布的建模能力,从而在图像生成、文本生成、语音合成等领域取得更好的效果。此外,该研究也为向量量化技术的进一步发展提供了理论指导。
📄 摘要(原文)
Vector quantization is a technique in machine learning that discretizes continuous representations into a set of discrete vectors. It is widely employed in tokenizing data representations for large language models, diffusion models, and other generative models. Despite its prevalence, the characteristics and behaviors of vector quantization in generative models remain largely underexplored. In this study, we investigate representation collapse in vector quantization - a critical degradation where codebook tokens or latent embeddings lose their discriminative power by converging to a limited subset of values. This collapse fundamentally compromises the model's ability to capture diverse data patterns. By leveraging both synthetic and real datasets, we identify the severity of each type of collapses and triggering conditions. Our analysis reveals that restricted initialization and limited encoder capacity result in tokens collapse and embeddings collapse. Building on these findings, we propose potential solutions aimed at mitigating each collapse. To the best of our knowledge, this is the first comprehensive study examining representation collapsing problems in vector quantization.