Video-Text Dataset Construction from Multi-AI Feedback: Promoting Weak-to-Strong Preference Learning for Video Large Language Models
作者: Hao Yi, Qingyang Li, Yulan Hu, Fuzheng Zhang, Di Zhang, Yong Liu
分类: cs.LG, cs.CL, cs.CV
发布日期: 2024-11-25
💡 一句话要点
提出MMAIP-V数据集与Iter-W2S-RLAIF框架,提升视频大语言模型在VQA任务中的对齐能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频问答 多模态大语言模型 偏好学习 强化学习 AI反馈 数据集构建 弱到强学习
📋 核心要点
- 现有VQA偏好数据稀缺,手动标注成本高且质量难以保证,AI生成回复多样性不足,限制了MLLM的对齐能力。
- 提出MMAIP-V数据集,通过多AI反馈和外部评分构建高质量VQA偏好数据;提出Iter-W2S-RLAIF框架,迭代优化MLLM的对齐能力。
- 实验表明,MMAIP-V数据集能够有效提升MLLM的偏好学习能力,Iter-W2S-RLAIF框架能够充分利用数据集中的对齐信息。
📝 摘要(中文)
高质量的视频-文本偏好数据对于多模态大语言模型(MLLM)的对齐至关重要。然而,现有的偏好数据非常稀缺。获取用于偏好训练的VQA偏好数据成本高昂,并且手动标注回复非常不可靠,可能导致低质量的配对。同时,由温度调整控制的AI生成的回复缺乏多样性。为了解决这些问题,我们提出了一个高质量的VQA偏好数据集,称为MMAIP-V,它通过从回复分布集中抽样并使用外部评分函数进行回复评估来构建。此外,为了充分利用MMAIP-V中的偏好知识并确保充分的优化,我们提出了Iter-W2S-RLAIF框架,该框架通过迭代更新参考模型并执行参数外推来逐步增强MLLM的对齐能力。最后,我们提出了一种在VQA评估中无偏且信息完整的评估方案。实验表明,MMAIP-V有利于MLLM的偏好学习,并且Iter-W2S-RLAIF充分利用了MMAIP-V中的对齐信息。我们相信,所提出的基于AI反馈的自动VQA偏好数据生成流程可以极大地促进未来在MLLM对齐方面的工作。代码和数据集已开源。
🔬 方法详解
问题定义:当前视频多模态大语言模型(MLLM)的训练依赖于大量的视频-文本数据。然而,高质量的VQA偏好数据非常稀缺,获取成本高昂。人工标注的回复质量难以保证,且AI生成回复的多样性不足,这些问题严重阻碍了MLLM的对齐能力,使其难以生成符合人类偏好的答案。
核心思路:论文的核心思路是利用多个AI模型的反馈来自动构建高质量的VQA偏好数据集,并设计迭代的弱到强强化学习框架来充分利用这些数据。通过引入外部评分函数,可以更准确地评估AI生成的回复质量,从而筛选出更符合人类偏好的数据。迭代的训练方式能够逐步提升MLLM的对齐能力。
技术框架:Iter-W2S-RLAIF框架包含以下几个主要阶段:1) 使用多个预训练的MLLM生成VQA任务的多个候选回复。2) 使用外部评分函数(例如另一个更强大的MLLM)对这些回复进行评分。3) 基于评分结果构建MMAIP-V偏好数据集。4) 使用MMAIP-V数据集,通过迭代的弱到强强化学习来训练目标MLLM。在每次迭代中,使用当前模型作为参考模型,并进行参数外推,以进一步提升模型的性能。
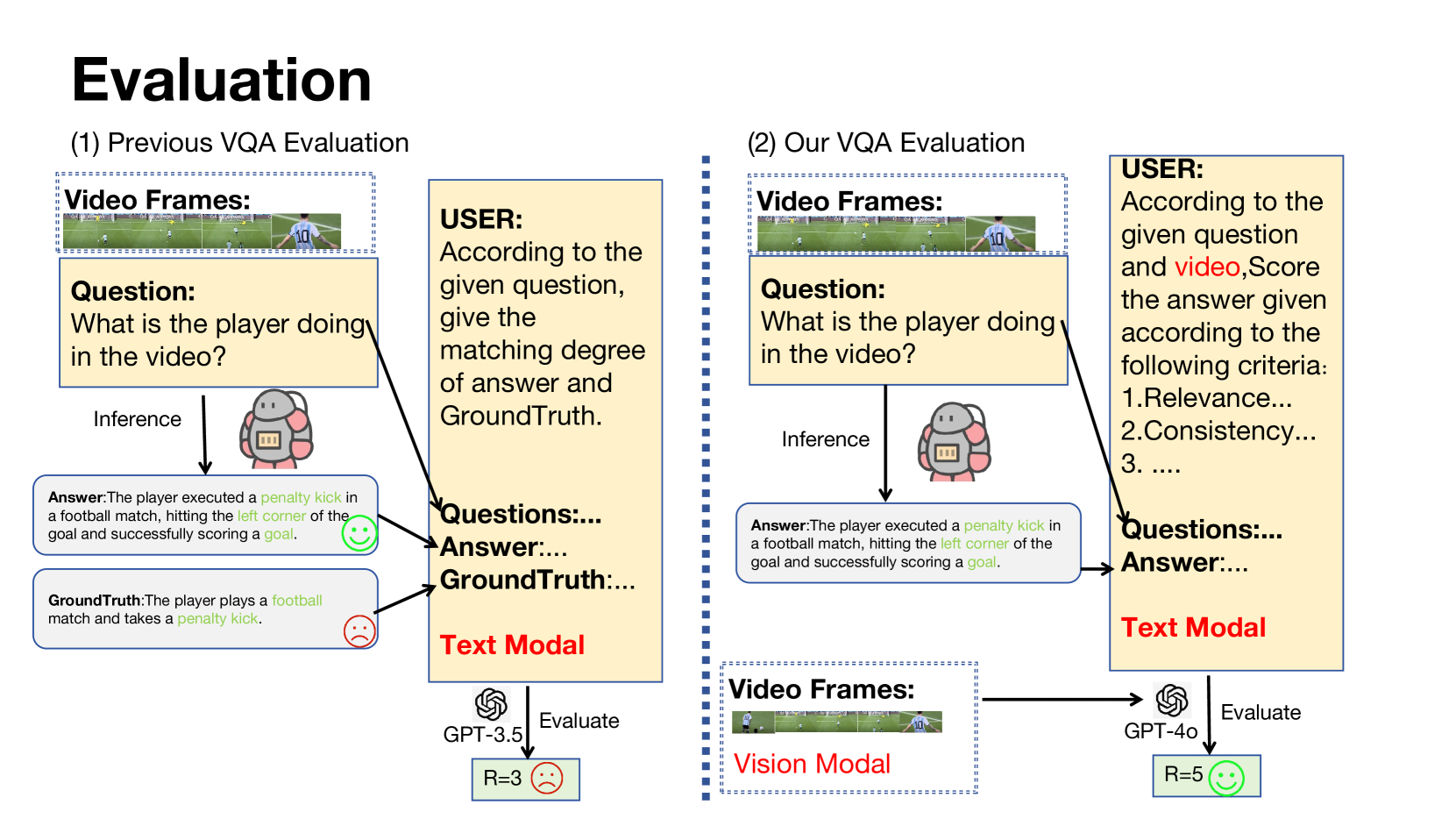
关键创新:论文的关键创新在于:1) 提出了基于多AI反馈的自动VQA偏好数据生成流程,有效降低了数据标注成本,并提高了数据质量。2) 提出了Iter-W2S-RLAIF框架,通过迭代的弱到强强化学习,充分利用了MMAIP-V数据集中的对齐信息,显著提升了MLLM的性能。3) 提出了无偏且信息完整的VQA评估方案。
关键设计:MMAIP-V数据集的构建过程中,关键在于选择合适的外部评分函数和抽样策略,以保证数据的质量和多样性。Iter-W2S-RLAIF框架的关键在于参数外推的策略,需要仔细调整参数,以避免训练不稳定。具体的损失函数未知,但推测使用了基于偏好排序的损失函数,例如pairwise ranking loss。
🖼️ 关键图片


📊 实验亮点
论文提出的MMAIP-V数据集和Iter-W2S-RLAIF框架在VQA任务上取得了显著的性能提升。具体的数据提升幅度未知,但摘要中提到实验证明MMAIP-V有利于MLLM的偏好学习,并且Iter-W2S-RLAIF充分利用了MMAIP-V中的对齐信息。该方法为提升视频MLLM的性能提供了一种有效的解决方案。
🎯 应用场景
该研究成果可广泛应用于视频内容理解、智能问答、视频推荐等领域。通过提升MLLM的对齐能力,可以使AI系统更好地理解视频内容,并生成更符合人类偏好的回复,从而提高用户体验和应用价值。未来,该方法有望应用于更复杂的视频分析和生成任务。
📄 摘要(原文)
High-quality video-text preference data is crucial for Multimodal Large Language Models (MLLMs) alignment. However, existing preference data is very scarce. Obtaining VQA preference data for preference training is costly, and manually annotating responses is highly unreliable, which could result in low-quality pairs. Meanwhile, AI-generated responses controlled by temperature adjustment lack diversity. To address these issues, we propose a high-quality VQA preference dataset, called \textit{\textbf{M}ultiple \textbf{M}ultimodal \textbf{A}rtificial \textbf{I}ntelligence \textbf{P}reference Datasets in \textbf{V}QA} (\textbf{MMAIP-V}), which is constructed by sampling from the response distribution set and using an external scoring function for response evaluation. Furthermore, to fully leverage the preference knowledge in MMAIP-V and ensure sufficient optimization, we propose \textit{\textbf{Iter}ative \textbf{W}eak-to-\textbf{S}trong \textbf{R}einforcement \textbf{L}earning from \textbf{AI} \textbf{F}eedback for video MLLMs} (\textbf{Iter-W2S-RLAIF}), a framework that gradually enhances MLLMs' alignment capabilities by iteratively updating the reference model and performing parameter extrapolation. Finally, we propose an unbiased and information-complete evaluation scheme in VQA evaluation. Experiments demonstrate that MMAIP-V is beneficial for MLLMs in preference learning and Iter-W2S-RLAIF fully exploits the alignment information in MMAIP-V. We believe that the proposed automatic VQA preference data generation pipeline based on AI feedback can greatly promote future work in the MLLMs alignment. \textbf{Code and dataset are available} \href{https://anonymous.4open.science/r/MMAIP-V_Iter-W2S-RLAIF-702F}{MMAIP-V_Iter-W2S-RLAIF-702F}.