MixPE: Quantization and Hardware Co-design for Efficient LLM Inference
作者: Yu Zhang, Mingzi Wang, Lancheng Zou, Wulong Liu, Hui-Ling Zhen, Mingxuan Yuan, Bei Yu
分类: cs.LG, cs.AI, cs.AR
发布日期: 2024-11-25
💡 一句话要点
MixPE:面向高效LLM推理的量化与硬件协同设计
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 量化 混合精度 硬件加速 低比特量化
📋 核心要点
- 现有GPU和TPU等硬件加速器对混合精度矩阵乘法(mpGEMM)缺乏原生支持,导致LLM量化推理过程中反量化操作效率低下。
- MixPE通过在per-group mpGEMM后进行反量化,并采用shift&add操作替代传统乘法器,显著降低反量化开销,提升计算和能源效率。
- 实验结果表明,MixPE相比现有量化加速器,推理速度提升2.6倍,能耗降低1.4倍,展现了其优越的性能。
📝 摘要(中文)
基于Transformer的大语言模型(LLMs)随着模型规模的持续增长取得了显著的成功,但由于巨大的计算和内存需求,它们的部署仍然具有挑战性。量化已经成为一种有前景的解决方案,并且用于LLM的最先进的量化算法引入了混合精度矩阵乘法(mpGEMM)的需求,其中较低精度的权重与较高精度的激活相乘。尽管有其优点,但当前的硬件加速器(如GPU和TPU)缺乏对高效mpGEMM的原生支持,导致主顺序循环中存在低效的反量化操作。为了解决这个限制,我们引入了MixPE,一种专门的混合精度处理单元,专为LLM推理中的高效低比特量化而设计。MixPE利用两项关键创新来最大限度地减少反量化开销,并释放低比特量化的全部潜力。首先,认识到scale和zero point在每个量化组内共享,我们建议在per-group mpGEMM之后执行反量化,从而显著降低反量化开销。其次,MixPE没有依赖传统的乘法器,而是利用高效的shift&add操作进行乘法,从而优化了计算和能源效率。我们的实验结果表明,MixPE超越了最先进的量化加速器,实现了2.6倍的速度提升和1.4倍的能源降低。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLM)量化推理过程中,由于现有硬件加速器对混合精度矩阵乘法(mpGEMM)支持不足,导致的反量化操作效率低下的问题。现有方法在低比特量化时,反量化操作成为性能瓶颈,限制了量化的收益。
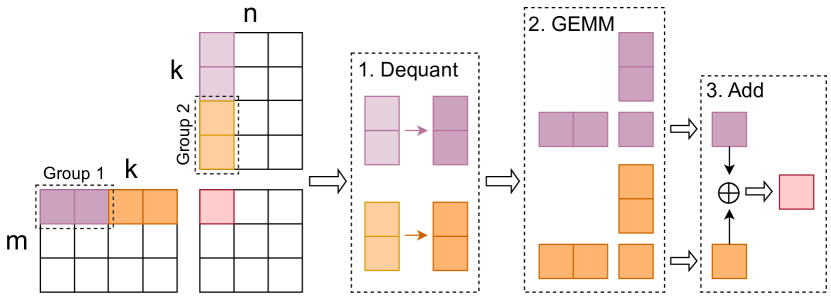
核心思路:论文的核心思路是通过硬件加速器MixPE的协同设计,优化混合精度计算流程,减少反量化操作的开销。具体而言,利用量化组内scale和zero point共享的特性,将反量化操作后移至per-group mpGEMM之后进行,从而减少反量化的次数。同时,采用shift&add操作替代传统乘法器,提高计算效率。
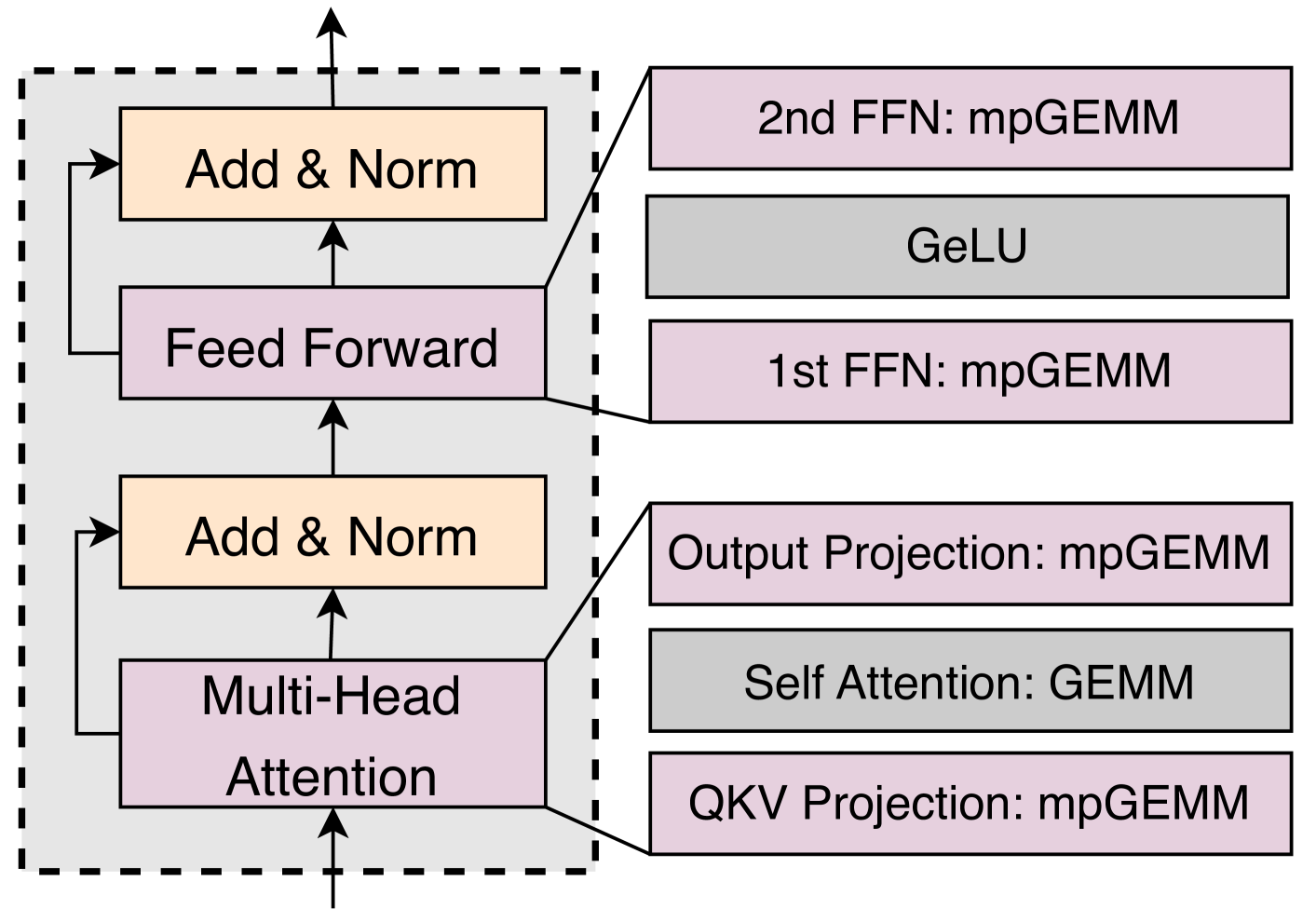
技术框架:MixPE是一个专门设计的混合精度处理单元,用于加速LLM的低比特量化推理。其主要流程包括:1) 从内存读取量化后的权重和激活值;2) 使用优化的mpGEMM进行矩阵乘法,其中权重为低精度,激活值为高精度;3) 在per-group mpGEMM后进行反量化操作;4) 将结果写回内存。MixPE的关键在于其优化的mpGEMM单元和反量化策略。
关键创新:论文的关键创新在于:1) 提出了在per-group mpGEMM后进行反量化的策略,显著减少了反量化操作的次数,降低了计算开销;2) 采用了基于shift&add操作的乘法器,替代传统的乘法器,提高了计算效率和能源效率;3) 针对LLM量化推理,进行了硬件和算法的协同设计,充分发挥了低比特量化的潜力。
关键设计:MixPE的关键设计包括:1) 量化组大小的选择,需要在计算复杂度和反量化次数之间进行权衡;2) shift&add操作的优化,例如采用Booth编码等技术,减少加法器的数量;3) 内存访问模式的优化,例如采用数据重排等技术,提高数据局部性,减少内存访问延迟。
🖼️ 关键图片

📊 实验亮点
实验结果表明,MixPE在LLM推理任务中,相比于最先进的量化加速器,实现了2.6倍的速度提升和1.4倍的能源降低。这些显著的性能提升验证了MixPE在低比特量化和硬件协同设计方面的有效性,为LLM的高效部署提供了新的解决方案。
🎯 应用场景
该研究成果可应用于各种需要高效LLM推理的场景,例如边缘设备上的自然语言处理、移动端的智能助手、以及对延迟敏感的云服务。通过降低计算和内存需求,MixPE能够使LLM在资源受限的环境中部署成为可能,并加速LLM在实际应用中的普及。
📄 摘要(原文)
Transformer-based large language models (LLMs) have achieved remarkable success as model sizes continue to grow, yet their deployment remains challenging due to significant computational and memory demands. Quantization has emerged as a promising solution, and state-of-the-art quantization algorithms for LLMs introduce the need for mixed-precision matrix multiplication (mpGEMM), where lower-precision weights are multiplied with higher-precision activations. Despite its benefits, current hardware accelerators such as GPUs and TPUs lack native support for efficient mpGEMM, leading to inefficient dequantization operations in the main sequential loop. To address this limitation, we introduce MixPE, a specialized mixed-precision processing element designed for efficient low-bit quantization in LLM inference. MixPE leverages two key innovations to minimize dequantization overhead and unlock the full potential of low-bit quantization. First, recognizing that scale and zero point are shared within each quantization group, we propose performing dequantization after per-group mpGEMM, significantly reducing dequantization overhead. Second, instead of relying on conventional multipliers, MixPE utilizes efficient shift\&add operations for multiplication, optimizing both computation and energy efficiency. Our experimental results demonstrate that MixPE surpasses the state-of-the-art quantization accelerators by $2.6\times$ speedup and $1.4\times$ energy reduction.