eFedLLM: Efficient LLM Inference Based on Federated Learning
作者: Shengwen Ding, Chenhui Hu
分类: cs.LG, cs.AI
发布日期: 2024-11-24
💡 一句话要点
提出基于联邦学习的高效LLM推理框架eFedLLM,降低资源需求。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 大型语言模型 模型并行 分布式训练 激励机制 内存优化 奇异值分解
📋 核心要点
- 大型语言模型对计算和内存资源需求高,限制了其广泛应用。
- 利用联邦学习和模型并行分布式训练,将计算负载分散到多个参与者。
- 通过激励机制和内存优化策略,提升训练效率和模型性能。
📝 摘要(中文)
本文提出了一种有效的方法,旨在提高大型语言模型(LLM)推理的运行效率和可负担性。该模型利用基于Transformer的联邦学习(FL)与模型并行分布式训练,有效地将计算负载和内存需求分摊到参与者网络中。这种策略允许资源有限的用户协作训练先进的LLM。此外,还在FL框架内创新了一种激励机制,奖励建设性贡献并过滤恶意活动,从而保障训练过程的完整性和可靠性。同时,利用内存分层策略和权重矩阵的奇异值分解(SVD)进一步提高计算和内存效率。公式分析和数值计算结果表明,该方法显著优化了资源使用,普及了对尖端LLM的访问,确保广大用户能够贡献并受益于这些先进模型。
🔬 方法详解
问题定义:现有大型语言模型(LLM)的推理需要大量的计算和内存资源,使得许多资源有限的用户和研究人员难以访问和使用这些模型。现有的集中式训练方法无法有效利用分布式资源,并且存在数据隐私问题。
核心思路:论文的核心思路是利用联邦学习(FL)将LLM的训练过程分布到多个参与者,每个参与者使用自己的数据进行本地训练,然后将模型参数聚合到中心服务器。通过模型并行分布式训练,进一步降低单个参与者的计算和内存需求。同时,设计激励机制来保证训练过程的可靠性和安全性。
技术框架:eFedLLM的整体框架包括以下几个主要模块:1) 参与者选择:选择合适的参与者进行联邦学习。2) 本地训练:每个参与者使用自己的数据进行本地模型训练。3) 模型聚合:中心服务器收集参与者的模型参数,并进行聚合。4) 激励机制:奖励贡献大的参与者,惩罚恶意参与者。5) 内存优化:使用内存分层策略和奇异值分解(SVD)来降低内存需求。
关键创新:论文的关键创新点在于将联邦学习与模型并行分布式训练相结合,有效地降低了LLM训练的资源需求。此外,还创新性地设计了一种激励机制,保证了训练过程的可靠性和安全性。同时,结合内存优化策略,进一步提升了效率。
关键设计:在联邦学习中,采用基于Transformer的模型结构。使用模型并行策略将模型参数分布到多个参与者。激励机制采用基于贡献度的奖励策略,贡献度可以通过模型性能的提升来衡量。内存优化方面,采用SVD对权重矩阵进行分解,降低内存占用。损失函数采用交叉熵损失函数,优化目标是最小化模型在验证集上的损失。
🖼️ 关键图片
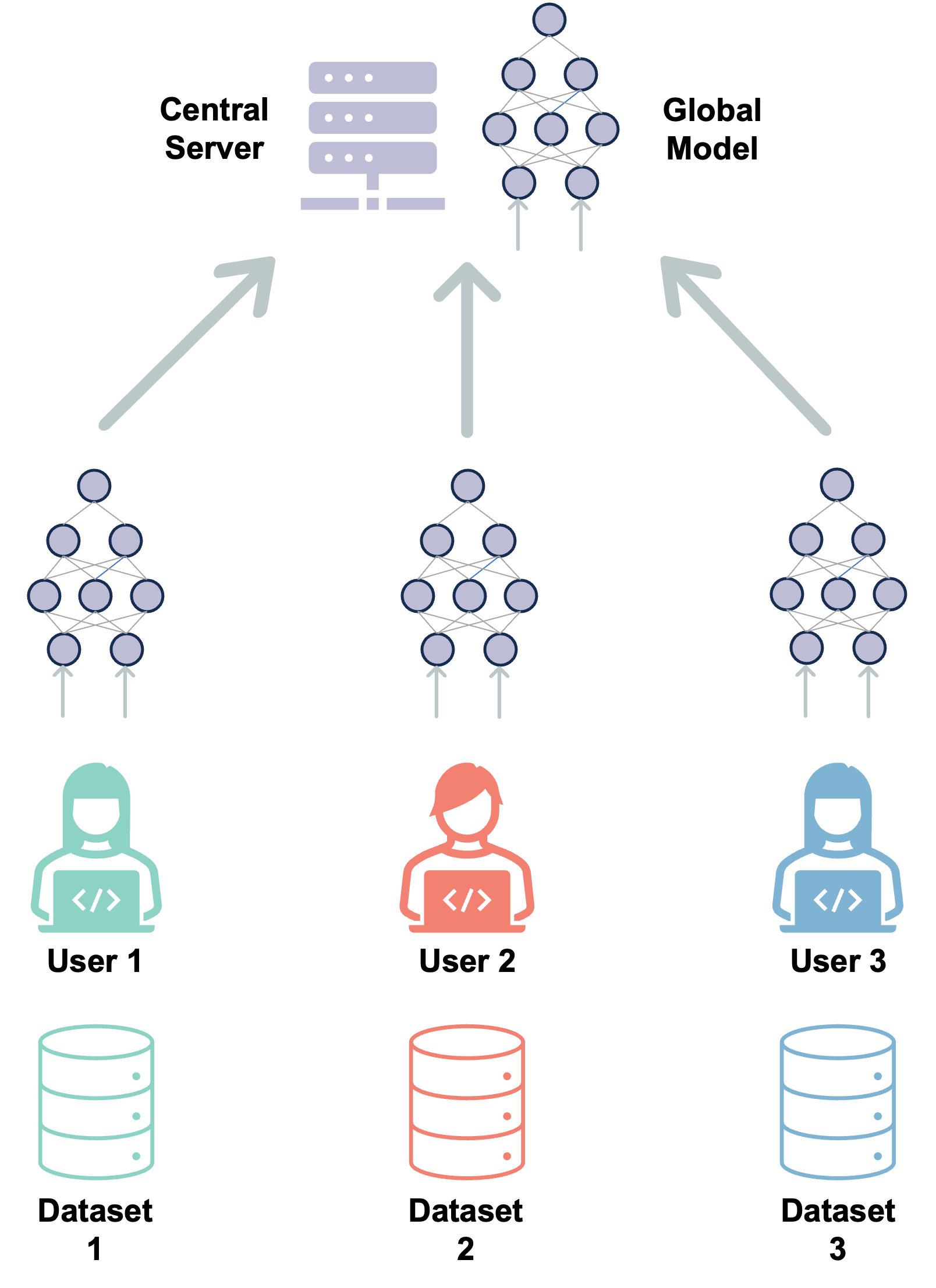
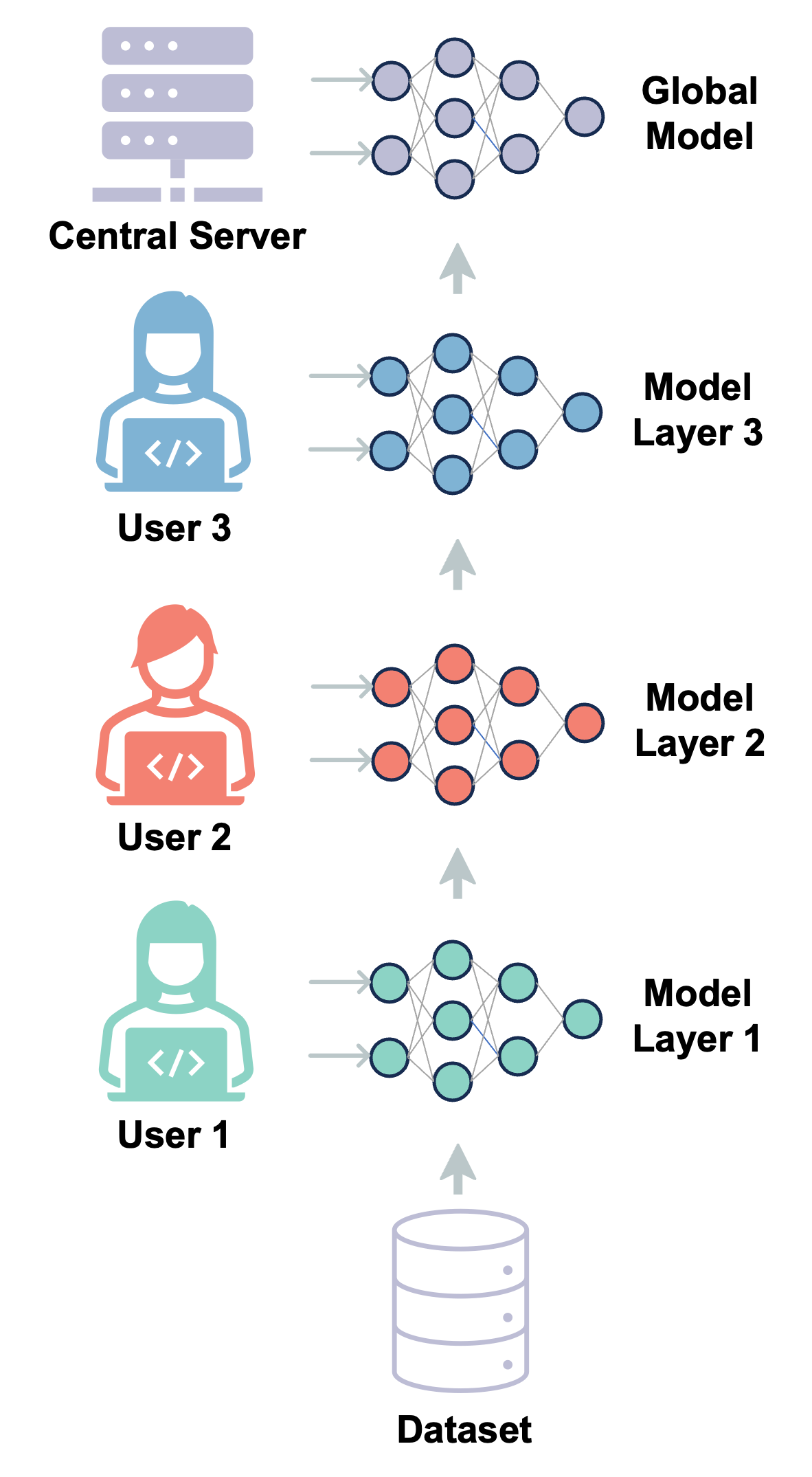
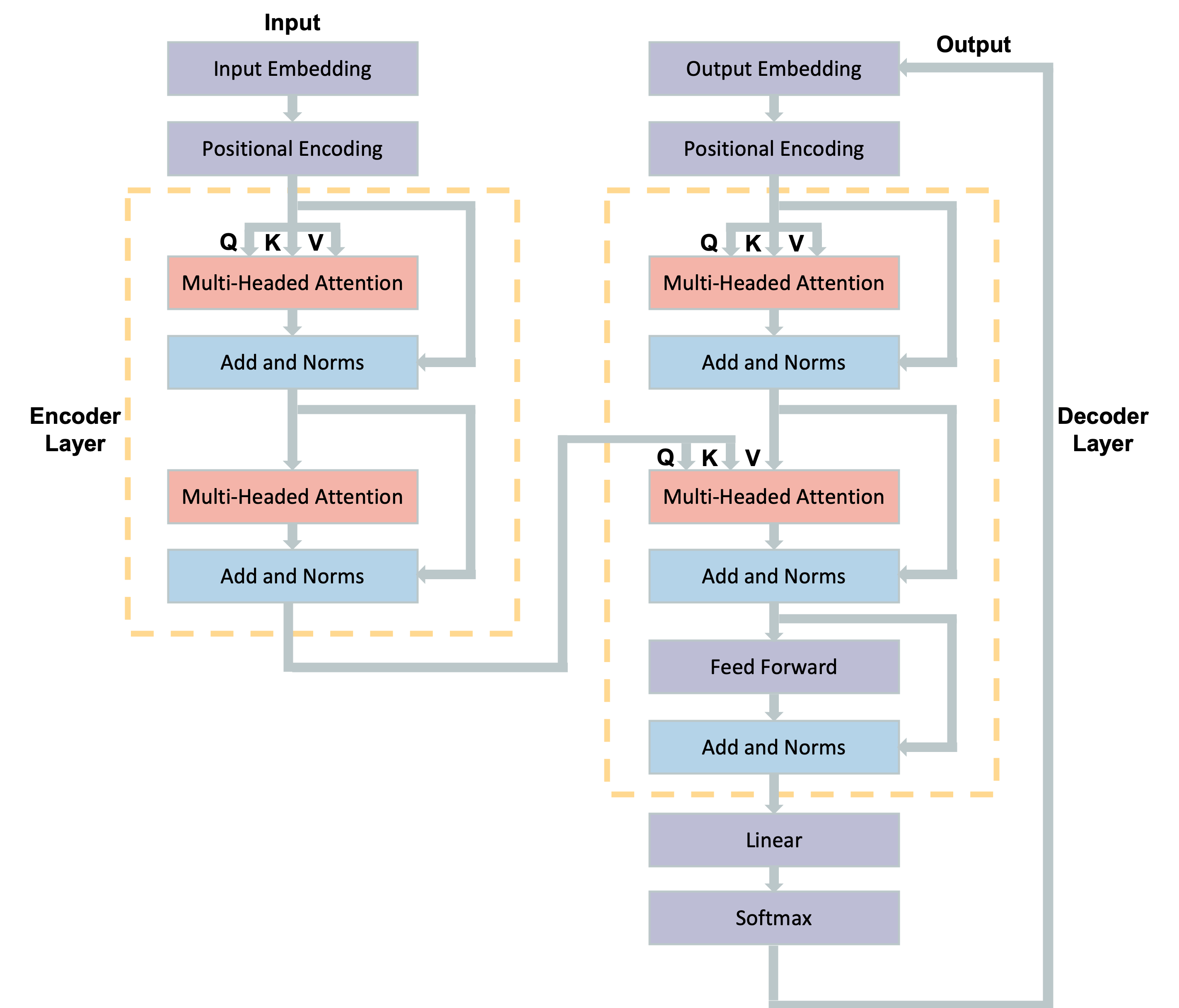
📊 实验亮点
论文通过公式分析和数值计算,验证了eFedLLM的有效性。结果表明,该方法能够显著降低LLM的资源需求,并提高训练效率。具体的性能数据和对比基线在论文中进行了详细的展示。通过联邦学习和模型并行,使得资源有限的用户也能够训练和使用先进的LLM。
🎯 应用场景
该研究成果可应用于各种需要大规模语言模型的场景,例如智能客服、文本生成、机器翻译等。通过降低LLM的资源需求,使得更多资源有限的用户和研究人员能够参与到LLM的训练和应用中,从而促进人工智能技术的普及和发展。未来,该方法可以进一步扩展到其他类型的深度学习模型,并应用于更广泛的领域。
📄 摘要(原文)
Large Language Models (LLMs) herald a transformative era in artificial intelligence (AI). However, the expansive scale of data and parameters of LLMs requires high-demand computational and memory resources, restricting their accessibility to a broader range of users and researchers. This paper introduces an effective approach that enhances the operational efficiency and affordability of LLM inference. By utilizing transformer-based federated learning (FL) with model-parallel distributed training, our model efficiently distributes the computational loads and memory requirements across a network of participants. This strategy permits users, especially those with limited resources to train state-of-the-art LLMs collaboratively. We also innovate an incentive mechanism within the FL framework, rewarding constructive contributions and filtering out malicious activities, thereby safeguarding the integrity and reliability of the training process. Concurrently, we leverage memory hierarchy strategies and Singular Value Decomposition (SVD) on weight matrices to boost computational and memory efficiencies further. Our results, derived from formulaic analyses and numerical calculations, demonstrate significant optimization of resource use and democratize access to cutting-edge LLMs, ensuring that a wide scale of users can both contribute to and benefit from these advanced models.