VQalAttent: a Transparent Speech Generation Pipeline based on Transformer-learned VQ-VAE Latent Space
作者: Armani Rodriguez, Silvija Kokalj-Filipovic
分类: cs.LG, eess.AS
发布日期: 2024-11-22
💡 一句话要点
VQalAttent:基于Transformer学习的VQ-VAE潜在空间,实现可控且透明的语音生成
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 语音合成 VQ-VAE Transformer 离散潜在空间 可解释性 生成模型 AudioMNIST
📋 核心要点
- 语音合成中,高效生成高质量语音仍然是生成模型面临的关键挑战。
- VQalAttent通过VQ-VAE将音频压缩为离散潜在表示,再用Transformer学习潜在变量的概率模型,实现语音生成。
- 实验表明,该模型能以有限的计算资源生成可理解的语音,且易于分析和改进。
📝 摘要(中文)
本文提出了一种名为VQalAttent的轻量级模型,旨在生成具有可调性能和可解释性的伪语音。该方法利用AudioMNIST数据集(包含人类对数字0-9的语音),采用两步架构:首先,使用可扩展的矢量量化自编码器(VQ-VAE)将音频频谱图压缩为离散潜在表示;其次,使用仅解码器Transformer学习这些潜在变量的概率模型。训练后的Transformer生成类似的潜在序列,通过VQ-VAE解码器转换为音频频谱图,进而生成伪语音。通过分析潜在空间的维度和外部信息对伪语音的统计和感知质量的影响,可以指导大型商业生成模型的改进。结果表明,VQalAttent能够以有限的计算资源生成可理解的语音样本,且训练流程的模块化和透明性有助于将分析结果与模块化修改相关联,从而为更复杂的模型提供见解。
🔬 方法详解
问题定义:现有语音生成模型在效率和可解释性方面存在不足,尤其是在理解模型内部运作机制以及如何通过调整模型参数来控制生成语音的质量方面面临挑战。该论文旨在解决如何在计算资源有限的情况下,生成高质量、可控且易于理解的语音,并为更复杂的语音生成模型提供设计思路。
核心思路:该论文的核心思路是将语音生成过程分解为两个阶段:首先,使用VQ-VAE将连续的音频频谱图转换为离散的潜在表示,从而降低模型的复杂度;其次,利用Transformer学习这些离散潜在表示的概率模型,从而生成新的潜在序列,进而生成语音。这种分解使得模型更易于理解和控制,并且可以利用VQ-VAE的压缩能力来提高生成效率。
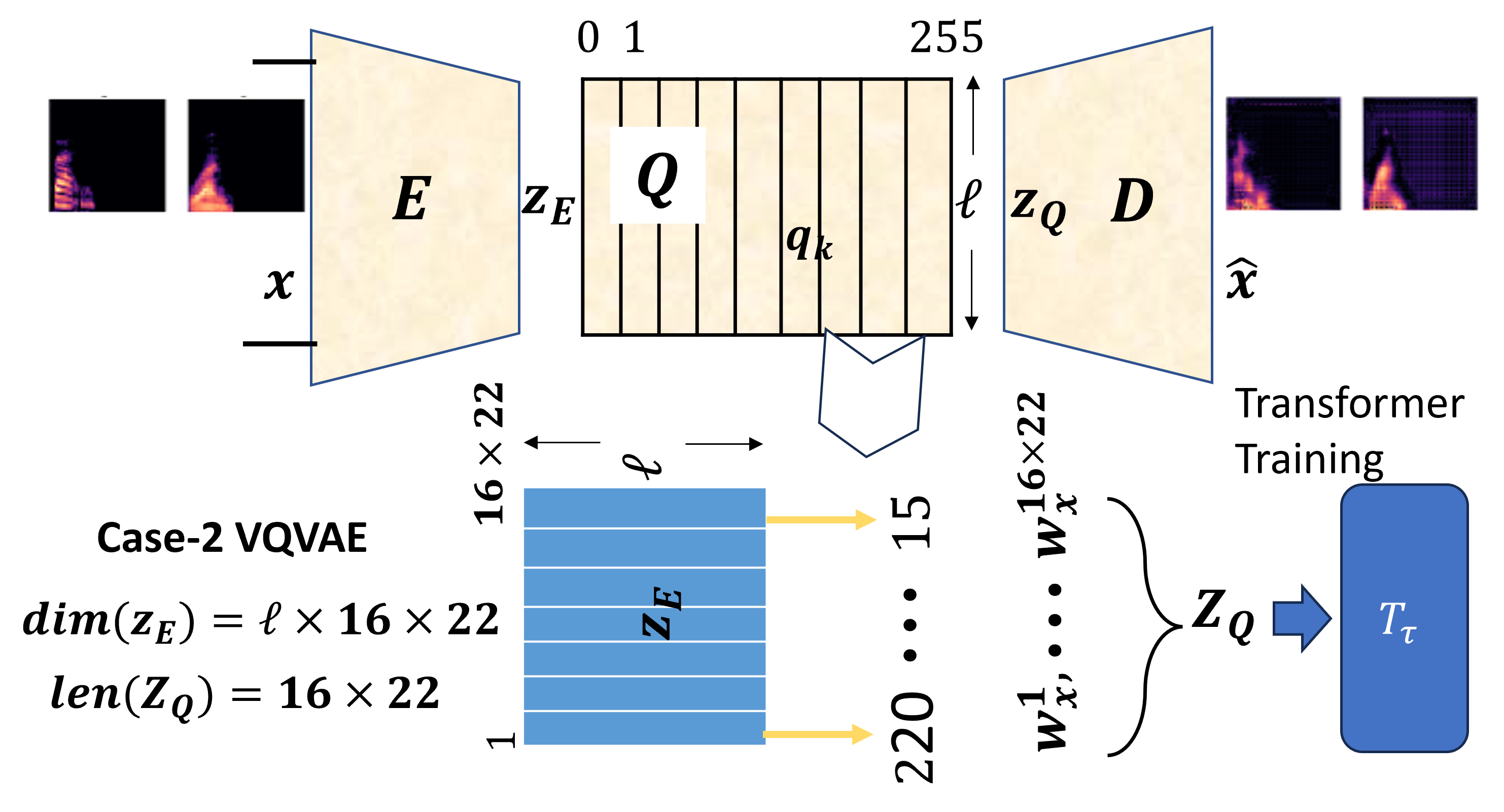
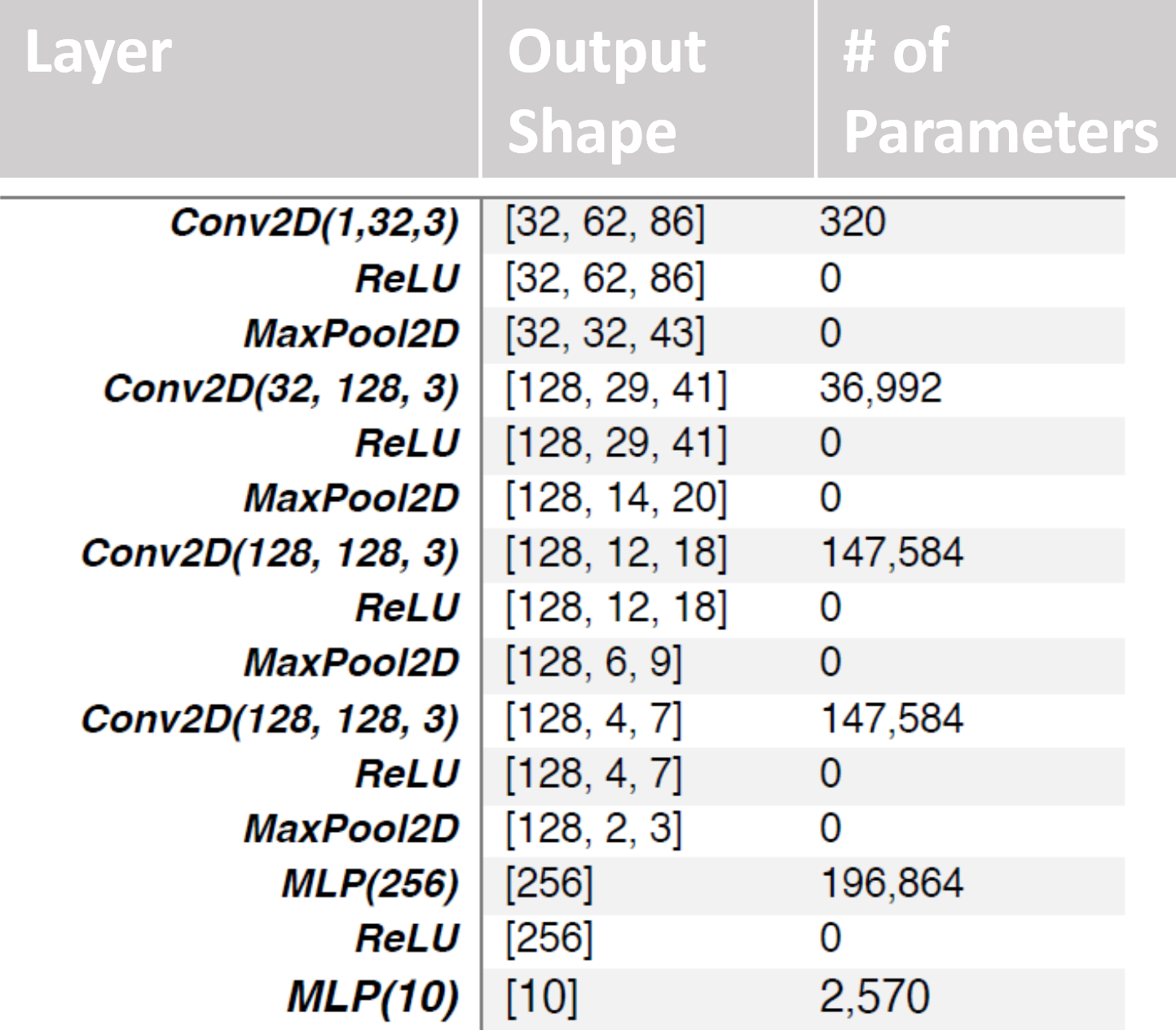
技术框架:VQalAttent模型包含两个主要模块:VQ-VAE和Transformer。VQ-VAE负责将音频频谱图编码为离散的潜在表示,并从潜在表示解码回音频频谱图。Transformer则负责学习潜在表示的概率模型,并生成新的潜在序列。整个流程如下:1) 输入音频频谱图;2) VQ-VAE编码器将频谱图编码为潜在表示;3) Transformer学习潜在表示的概率模型并生成新的潜在序列;4) VQ-VAE解码器将潜在序列解码为音频频谱图;5) 从音频频谱图生成语音。
关键创新:该论文的关键创新在于将VQ-VAE和Transformer结合起来,构建了一个可控且透明的语音生成流程。通过使用VQ-VAE,模型可以将连续的音频频谱图转换为离散的潜在表示,从而降低了模型的复杂度,并使得模型更易于理解和控制。同时,Transformer的学习能力使得模型可以生成高质量的语音。此外,该模型的设计注重模块化和透明性,使得研究人员可以更容易地分析和改进模型。
关键设计:VQ-VAE使用了可扩展的设计,可以根据需要调整潜在空间的维度。Transformer采用了仅解码器的结构,简化了训练过程。损失函数包括VQ-VAE的重构损失和Transformer的交叉熵损失。AudioMNIST数据集被用于训练和评估模型。
🖼️ 关键图片

📊 实验亮点
实验结果表明,VQalAttent模型能够以有限的计算资源生成可理解的语音样本。通过分析潜在空间的维度和外部信息对伪语音的统计和感知质量的影响,可以指导大型商业生成模型的改进。该模型在AudioMNIST数据集上取得了良好的效果,证明了其在语音生成方面的潜力。
🎯 应用场景
VQalAttent模型可应用于语音合成、语音转换、语音增强等领域。其透明性和可控性使其成为研究语音生成机制的有力工具,并可用于指导更复杂的语音生成模型的设计。此外,该模型还可用于生成各种类型的语音,例如特定风格的语音或特定情感的语音,具有广泛的应用前景。
📄 摘要(原文)
Generating high-quality speech efficiently remains a key challenge for generative models in speech synthesis. This paper introduces VQalAttent, a lightweight model designed to generate fake speech with tunable performance and interpretability. Leveraging the AudioMNIST dataset, consisting of human utterances of decimal digits (0-9), our method employs a two-step architecture: first, a scalable vector quantized autoencoder (VQ-VAE) that compresses audio spectrograms into discrete latent representations, and second, a decoder-only transformer that learns the probability model of these latents. Trained transformer generates similar latent sequences, convertible to audio spectrograms by the VQ-VAE decoder, from which we generate fake utterances. Interpreting statistical and perceptual quality of the fakes, depending on the dimension and the extrinsic information of the latent space, enables guided improvements in larger, commercial generative models. As a valuable tool for understanding and refining audio synthesis, our results demonstrate VQalAttent's capacity to generate intelligible speech samples with limited computational resources, while the modularity and transparency of the training pipeline helps easily correlate the analytics with modular modifications, hence providing insights for the more complex models.